可视化卷积神经网络的特征和过滤器
Posted Wang_AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可视化卷积神经网络的特征和过滤器相关的知识,希望对你有一定的参考价值。
卷积神经网络是一种特殊类型的人工神经网络,广泛应用于图像识别。这种架构的成功始于 2015 年,当时凭借这种方法赢得了 ImageNet 图像分类挑战。
这些方法非常强大并且能够很好地进行预测,但同时它们也难以解释。因此,它们也被称为黑盒模型。
肯定是可用的与模型无关的方法,如LIME和部分依赖图,可以应用于任何模型。但在这种情况下,应用专为神经网络开发的可解释方法更有意义。与 ML 模型不同,卷积神经网络从原始图像像素中学习抽象特征 [1]。
在这篇文章中,我将重点介绍卷积神经网络如何学习特征。这可以通过逐步学习的特征的可视化来实现。在展示 Pythorch 的实现之前,我将解释 CNN 的工作原理,然后我将可视化为分类任务训练的 CNN 学习的特征图和感受野。
本文内容:
什么是CNN
定义和训练CNN的MNIST
在测试集4上评估模型
可视化过滤器
可视化特征图
什么是CNN
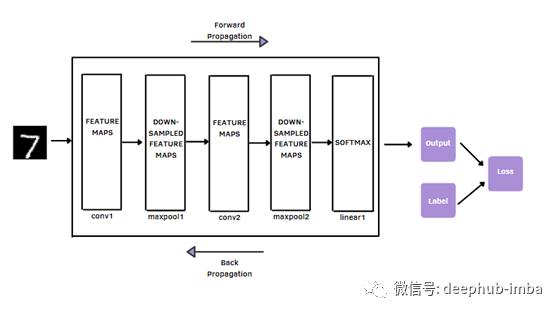
cnn由构建模块组成:卷积层、池化层和全连接层。卷积层的主要功能是提取特征或所谓的特征映射。它是如何做到的呢?它使用来自数据集[2]的多个过滤器。
之后,通过池化层将卷积运算得到的特征映射降维。最常用的池化操作是Maxpooling,它选择feature map中每个filter patch中最显著的像素值。因此,这两种类型的层对于进行特征提取是很有用的。
与卷积层和池化层不同的是,全连接层将提取的特征映射到最终的输出中,例如MNIST图像的分类为10位数字之一。
在数字图像中,一个二维网格存储像素值。它可以看作是一组数字。内核是一个小网格,通常大小为3x3,应用于图像的每个位置。当你深入到更深的层次时,这些特性会变得越来越复杂。
模型的性能是通过一个损失函数,即输出和目标标签之间的差异,通过在训练集上的前向传播,并通过梯度下降算法的反向传播更新参数,如权值和偏差。
定义和训练CNN的MNIST数据集
让我们首先导入库和数据集。Torch是为一维或多维张量提供数据结构的模块。
几个重要的包:
Torchvision:在我们的例子中,它为我们提供了MNIST数据集。
torch.nn:包含帮助你构建卷积神经网络的类和函数。
torch.optim:提供了所有的优化器,比如Adam。
torch.nn.functional:用于导入函数,如dropout、convolution、pooling、非线性激活函数和loss函数等。
我们下载训练和测试数据集,并将图像数据集转换为张量。我们不需要对图像进行归一化,因为数据集已经包含了灰度图像。将训练数据集划分为训练集和验证集。random_split为这两个集合提供了一个随机分区。DataLoader用于为训练、验证和测试集创建数据加载器,这些数据加载器被划分为小批。batchsize是模型训练过程中一次迭代中使用的样本数量。
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader,TensorDataset,random_split,SubsetRandomSampler, ConcatDataset
from torch.nn import functional as F
import torchvision
from torchvision import datasets,transforms
import torchvision.transforms as transforms
train_dataset = torchvision.datasets.MNIST('classifier_data', train=True, download=True)
test_dataset = torchvision.datasets.MNIST('classifier_data', train=False, download=True)
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_dataset.transform=transform
test_dataset.transform=transform
m=len(train_dataset)
#random_split randomly split a dataset into non-overlapping new datasets of given lengths
train_data, val_data = random_split(train_dataset, [int(m-m*0.2), int(m*0.2)])
batch_size=128
# The dataloaders handle shuffling, batching, etc...
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size)
valid_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size,shuffle=True)
print("Batches in Train Loader: {}".format(len(train_loader)))
print("Batches in Valid Loader: {}".format(len(valid_loader)))
print("Batches in Test Loader: {}".format(len(test_loader)))
print("Examples in Train Loader: {}".format(len(train_loader.sampler)))
print("Examples in Valid Loader: {}".format(len(valid_loader.sampler)))
print("Examples in Test Loader: {}".format(len(test_loader.sampler)))
我们定义了CNN架构。
class ConvNet(nn.Module):
def __init__(self,h1=96):
# We optimize dropout rate in a convolutional neural network.
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2)
self.drop1=nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(32 * 7 * 7, h1)
self.drop2=nn.Dropout2d(p=0.1)
self.fc2 = nn.Linear(h1, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x),kernel_size = 2))
x = F.relu(F.max_pool2d(self.conv2(x),kernel_size = 2))
x = self.drop1(x)
x = x.view(x.size(0),-1)
x = F.relu(self.fc1(x))
x = self.drop2(x)
return self.fc2(x)我们可以很容易地打印架构来快速了解一下:

您可以看到有两个卷积层和两个完全连接的层。每个卷积层之后是ReLU激活函数和maxpooling层。视图函数将数据重塑为一维数组,并将其传递给线性层。第二个完全连接的层,也称为输出层,将图像分类为10位数字之一。
我们定义构建块,将用于训练CNN:
用硬件加速器比如GPU来训练模型
CNN网络,这将被转移到设备上
交叉熵损失和Adam优化器
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.manual_seed(0)
model = ConvNet()
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.002)
criterion= nn.CrossEntropyLoss()现在,我们可以在训练集中训练网络,并在验证集中对其进行评估:
history={'train_loss':[],'valid_loss':[],'train_acc':[],'valid_acc':[]}
num_epochs=10
for epoch in range(num_epochs):
train_loss,train_correct=0.0,0
model.train()
for images, labels in train_loader:
images,labels = images.to(device),labels.to(device)
optimizer.zero_grad()
output = model(images)
loss = criterion(output,labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * images.size(0)
scores, predictions = torch.max(output.data, 1)
train_correct += (predictions == labels).sum().item()
valid_loss, val_correct = 0.0, 0
model.eval()
for images, labels in valid_loader:
images,labels = images.to(device),labels.to(device)
output = model(images)
loss=criterion(output,labels)
valid_loss+=loss.item()*images.size(0)
scores, predictions = torch.max(output.data,1)
val_correct+=(predictions == labels).sum().item()
train_loss = train_loss / len(train_loader.sampler)
train_acc = train_correct / len(train_loader.sampler)*100
valid_loss = valid_loss / len(valid_loader.sampler)
valid_acc = val_correct / len(valid_loader.sampler) * 100
print("Epoch:{}/{} \\t AVERAGE TL:{:.4f} AVERAGE VL:{:.4f} \\t AVERAGE TA:{:.2f} % AVERAGE VA:{:.2f} %".format(epoch + 1, num_epochs,
train_loss,
valid_loss,
train_acc,
valid_acc))
history['train_loss'].append(train_loss)
history['valid_loss'].append(valid_loss)
history['train_acc'].append(train_acc)
history['valid_acc'].append(valid_acc) 
训练代码可以分为两部分。
向前传播:
我们通过模型(images)将输入图像传递给网络
损失是通过调用标准(输出,标签)来计算的,其中输出构成预测类,标签构成目标类。
反向传播:
清除梯度以确保我们不会用optimizer.zero_grad()积累其他值
loss.backward()用于执行反向传播,并根据损失计算梯度
step()总是在梯度计算之后。它遍历所有参数并更新它们的值。
对训练集和验证集都计算损失函数和准确性。
在测试集上评估模型
模型训练完成后,我们可以对测试集的性能进行评估:
correct = 0
total = 0
test_loss = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs,labels)
test_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_loss = test_loss / len(test_loader.sampler)
print('Accuracy of the network on the test images: {:.2f} %%'.format(100 * correct / total))
print('Loss of the network on the test images: {:.4f}'.format(test_loss))
让我们把测试代码分解成小块:
torch.no_grad()用于禁用梯度跟踪,我们不再需要计算梯度,因为模型已经训练。
将输入图像传递给网络
通过添加loss.item()*images.size(0)计算测试损失
通过添加(predicted==labels).sum().item()计算测试精度
可视化过滤器
我们可以将学习到的过滤器可视化,CNN使用它来卷积feature map,其中包含从上一层提取的特征。可以通过遍历模型的所有层,list(model.children())来获得这些过滤器。如果层是卷积的,我们可以将权重存储在model_weights列表中,该列表将包含两个卷积层中使用的过滤器。
model_weights = []
conv_layers = []
model_children = list(model.children())
# counter to keep count of the conv layers
counter = 0
# append all the conv layers and their respective weights to the list
for i in range(len(model_children)):
if type(model_children[i]) == nn.Conv2d:
counter += 1
model_weights.append(model_children[i].weight)
conv_layers.append(model_children[i])
elif type(model_children[i]) == nn.Sequential:
for j in range(len(model_children[i])):
for child in model_children[i][j].children():
if type(child) == nn.Conv2d:
counter += 1
model_weights.append(child.weight)
conv_layers.append(child)
print(f"Total convolutional layers: {counter}")
下面是我找到的过滤器的形状。
for weight, conv in zip(model_weights, conv_layers):
# print(f"WEIGHT: {weight} \\nSHAPE: {weight.shape}")
print(f"CONV: {conv} ====> SHAPE: {weight.shape}")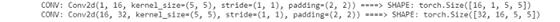
现在,我们可以可视化学习到的第一个卷积层的滤波器:
# visualize the first conv layer filters
plt.figure(figsize=(20, 17))
for i, filter in enumerate(model_weights[0]):
plt.subplot(4, 4, i+1) # we have 5x5 filters and total of 16 (see printed shapes)
plt.imshow(filter[0, :, :].detach().cpu().numpy(), cmap='viridis')
plt.axis('off')
plt.savefig('filter1.png')
plt.show()
现在,轮到可视化第二层卷积层的滤波器了。
# visualize the second conv layer filters
plt.figure(figsize=(20, 17))
for i, filter in enumerate(model_weights[1]):
plt.subplot(6, 6, i+1) # (8, 8) because in conv0 we have 5x5 filters and total of 64 (see printed shapes)
plt.imshow(filter[0, :, :].detach().cpu().numpy(), cmap='viridis')
plt.axis('off')
plt.savefig('filter2.png')
plt.show()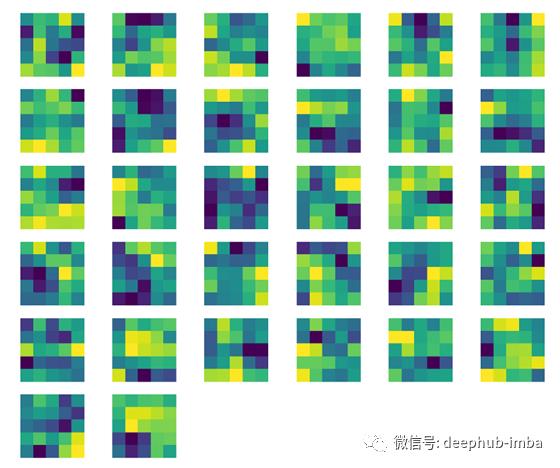
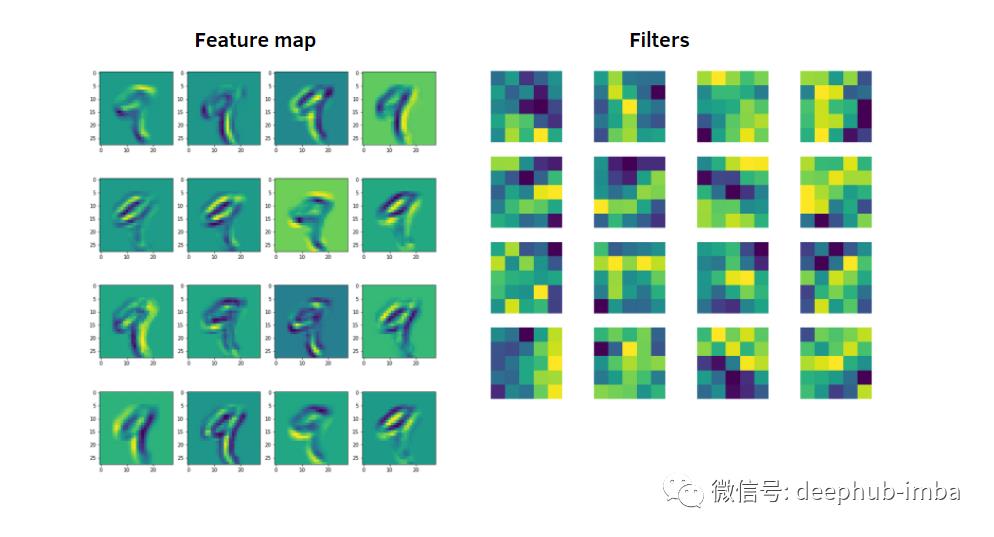
可视化特征图
Feature Map,又称Activation Map,是通过卷积运算得到的,通过filter/kernel将其应用到输入数据上。下面,我们定义一个函数来提取应用激活函数后获得的特征。
activation = {}
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook从训练数据集中,我们取一个代表数字9的图像。因此,我们将在第一个卷积层中可视化该图像获得的特征映射。
model.conv1.register_forward_hook(get_activation('conv1'))
data, _ = train_dataset[4]
data=data.to(device)
data.unsqueeze_(0)
output = model(data)
k=0
act = activation['conv1'].squeeze()
fig,ax = plt.subplots(4,4,figsize=(12, 15))
for i in range(act.size(0)//4):
for j in range(act.size(0)//4):
ax[i,j].imshow(act[k].detach().cpu().numpy())
k+=1
plt.savefig('fm1.png')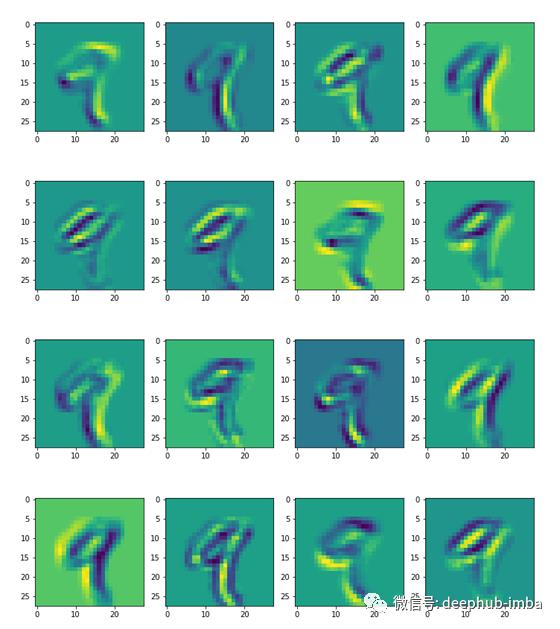
现在,我们在第二层卷积中将同一幅图像获得的特征映射可视化。
model.conv2.register_forward_hook(get_activation('conv2'))
data, _ = train_dataset[4]
data=data.to(device)
data.unsqueeze_(0)
output = model(data)
act = activation['conv2'].squeeze()
fig, axarr = plt.subplots(act.size(0)//4,4,figsize=(12, 16))
k=0
for i in range(act.size(0)//4):
for j in range(4):
axarr[i,j].imshow(act[k].detach().cpu().numpy())
k+=1
plt.savefig('fm2.png')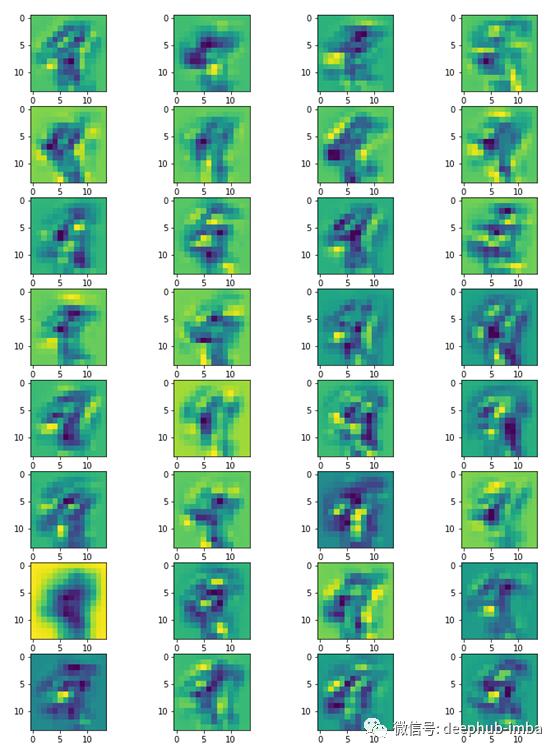
最后总结
恭喜你!您已经学会了用Pytorch将CNN学到的特征可视化。网络在其卷积层中学习新的、日益复杂的特征。从第一个卷积层到第二个卷积层,您可以看到这些特征的差异。在卷积层中走得越远,特征就越抽象。
感谢你的阅读。祝你过得愉快。
作者:Eugenia Anello
原文地址:https://medium.com/dataseries/visualizing-the-feature-maps-and-filters-by-convolutional-neural-networks-e1462340518e
以上是关于可视化卷积神经网络的特征和过滤器的主要内容,如果未能解决你的问题,请参考以下文章