OneVPL与FFmpeg/GStreamer硬件编解码器
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OneVPL与FFmpeg/GStreamer硬件编解码器相关的知识,希望对你有一定的参考价值。
相对软件Codec来说,人们对硬件Codec的应用并不太熟悉。本次LiveVideoStackCon 2021 上海站大会我们邀请到了来自英特尔的媒体工程师——许广新,来为我们分享Intel在硬件编解码器中的最新研发进展。
文 / 许广新
整理 / LiveVideoStack
谢谢大家,下午来参加讨论。我是Intel开发者软件工程部门的工程师许广新,我们team主要负责多媒体框架,我们与开源FFmpeg/GStreamer社区有良好的合作关系。FFmpeg官方Twitter曾经赞扬过我们说:“如果这些大公司都能像Intel一样,都能给他们贡献pacth,该有多好。”我们team也有GStreamer在中国的第一个maintainer。

今天我们先给大家做一些基本的介绍,然后讨论Intel最新的硬件功能,第三,会让大家看一下Intel的独立显卡在HEVC的transcode的质量和性能。第四,我会简单介绍一下FFmpeg的hardwork codecs的工作流程。第五,介绍我们提供的两个Post Process,一个是FFmpeg DNN,一个是LibXCam。最后我会介绍如何在Intel的GPU上面,搭建一个优化的硬件视频pipeline,怎么发现硬件管线的问题。

图中就是一个基本的FFmpeg/GStreamer的pipeline,一般会包括一个基本的输入、video parser、video decoder、video process、video encoder,以及最后的输出。今天我们会分享video parser和video codec的内容。

接下来简单介绍一下,为什么会使用硬件codec?其中一个好处是,低延时和高吞吐。我记得我年轻的时候,解码一个VCD 352*240分辨率,就需要买一个单独的解码卡,但是现在买一个笔记本,解码几十路、近百路的1080p视频,可能一点问题都没有。硬件codec还有一个好处是,CPU的使用率会降低,会大量节省电源的消耗。但是它也有不好的地方。一个是,它很难跟软件encoder的最高质量模式竞争。因为客户对一般硬件编码器不是很熟悉,有很多厂商从下到下都是闭环的,很难去做定制化。但是,在Intel的平台上,我们从上到下,从driver到中间件、FFmpeg都是开源的,能在一定程度上帮助大家。大家需要对Intel硬件有一定的了解,才能去做定制化。所以,硬件codec大概的用途有video play,现在市面上看到的播放器都会用硬件来播放,很少用软件,否则CPU就会全部占用了。还有流媒体、云游戏的用途,以及对时延要求非常高的video encoder。

图中是对Intel在Linux上的媒体API的简单介绍,在介绍后面内容之前需要对此有个基本的了解。最下面是软件层,是video driver。在此之上,我们提供了一个叫VAAPI的接口,这就是Intel在Linux上面的硬件抽象层。基本上Linux系统都会有这个硬件抽象层,比如android、Chrome上都有。但是,这个硬件抽象层,一般人会觉得非常复杂,因为需要做surface管理,最后要decode到slice 层,才能使用到这个API。所以,Intel又提供了另外一套API,就是oneVPL,你可以认为它就是以前的MediaSDK。这一层主要的接口就是,一帧的码流进去,然后一帧解码后的数据出来,因为它是基于VAAPI的二次开发,所以它能够提供更强大的编码参数,并做了一些跟硬件相关的质量调整,能够提供更高质量的编码码流。

从去年到今年,我们可以看到的Intel硬件可能都是基于Xe的lowPower架构的产品,这个架构有三种平台。一种是Tiger Lake,或者是其续任产品,它就是我们的集成显卡。另外一种是独立显卡DG1,一些笔记本上可能会使用到,他也有单独的显卡。还有一种是SG1,它其实就是4个DG1,是专门给服务器用的,所以可以期待有3~4倍的DG1的性能。

对于这一代的Xe LowPower的媒体引擎来说,我们有什么改进呢?比如,达到了以前两倍以上的encode和decode的输入和输出,新加了AV1的硬件decode,也加了HEVC SCC的扩展,可以达到4K~8K的60fps的视频播放,也支持HDR/杜比、12bit端到端的视频pipeline。

图中就是Tiger Lake、DG1和SG1所有支持的功能。对于基本上市面上能见到的decoder,它们都能支持。对于encoder来说,它们也能支持。特别是针对HEVC,功能比前几代都有很大的提升,后面我会详细介绍。对于VPP来说,它们基本上都能支持。
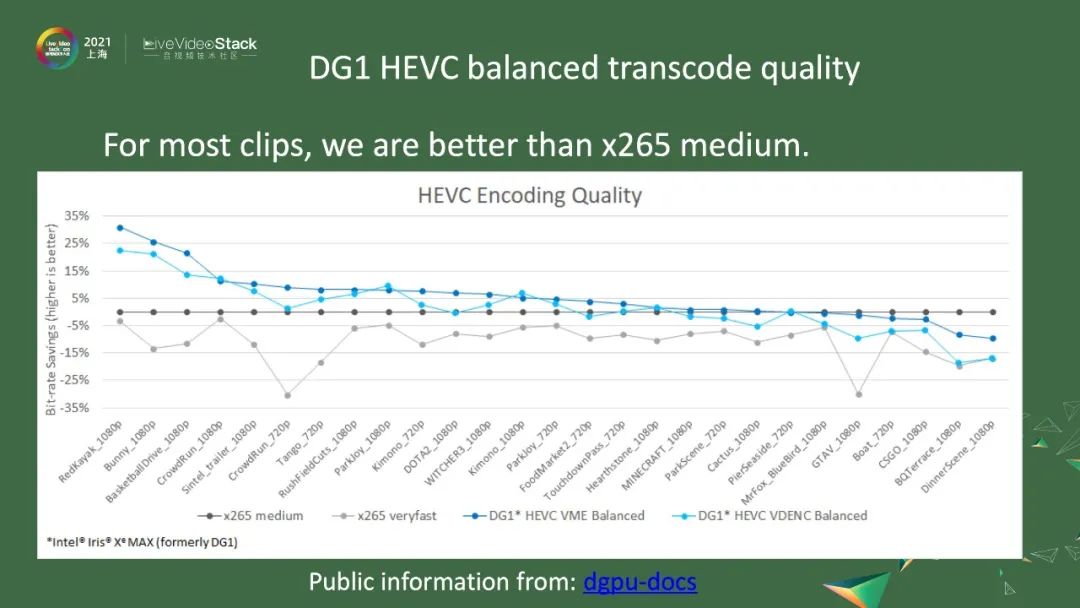
接下来,我们看看独立显卡DG1的transcode的质量。图中纵轴的原点是x265 medium,纵轴是bit-rate的节省,意思是比x265 medium好5%左右。横轴就是我们测的27个码流,在各个码流上DG1的表现。我们在DG1上提供了两种编码器。一种是VDENC,这其实是固定管线的、不可配置的,又把它叫作Low power模式,会节约电力。另一种是VME,是用处理单元去做一些事情,最后可以得到更好的码率。从这27个码流看来,码率基本上都会比x265 medium要好,有的会好到30%。
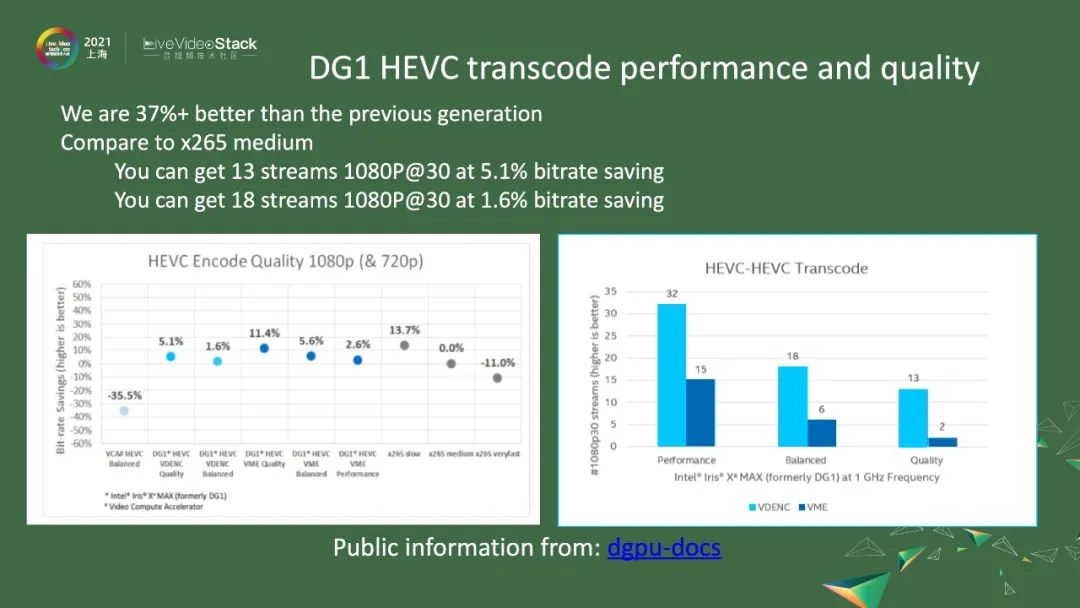
左图是对27个码流做了加权平均值,有很多点很有趣。第一个点是,前几代的产品,Intel以前卖过叫作VCA卡的产品。我们这一代的DG1相比VCA卡,最差的情况也会好37%以上,然后平均下来,所有的点都会比x265 medium都要好。第一个点是VDENC的high Quality模式,这个点上要比x265 medium要好5.1%左右。右图是transcode能到达的路数,即比x265 medium好5.1%的情况下,可以达到13路的1080p的30fps。如果你愿意牺牲2~3%的bit-rate的话,就使用Balanced模式,对应于第二个柱状图,大概能够达到18路的1080p的30fps。第一个柱状图是最好的,其实跟x265 slow差不多,大概差1、2点,在这个点上,可以达到2路的1080p的30fps。
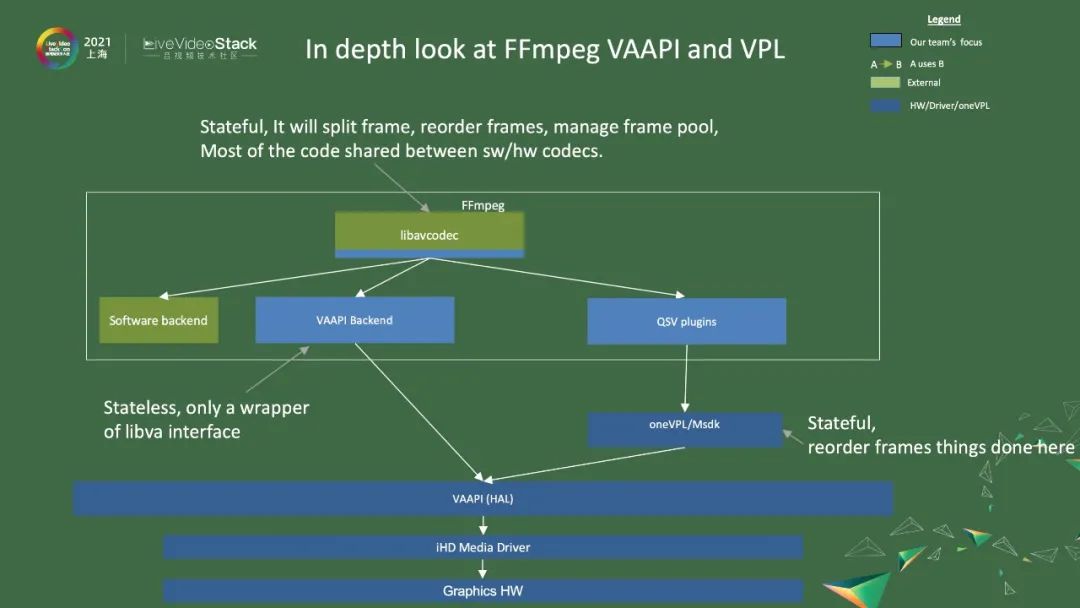
接下来我们简单介绍FFmpeg VAAPI和VPL,图中是架构图。最底下是Graphic HW,然后是driver,以及硬件抽象层。在硬件抽象层的基础上,FFmpeg会提供VAAPI的backend,直接调用VAAPI。然后,我们也会做一些硬件相关优化,就提供了一个oneVPL或media SDK,然后会被QSV plugin调用。它们都会被libavcodec接口调用,最后FFmpeg提供统一的接口给外部使用。

图中展示了一些细节。左边是decode,一般一个码流进来,会经过Demux、video decode、video Fliter等。Decode细化来说,先会接受到AVpacket,其就是一个bitstream,之后会判断有没有硬件decode,如果没有,就会走软件程序流程。软件decode会解码SPS、PPS,将整帧分成不同的slice,然后解码slice,之后就会输出一帧一帧的数据。如果发现有硬件decode,就会走硬件流程。硬件decode就是调用decode_params,把SPS、PPS都送给driver,然后有start_frame告诉driver,它要解码这一帧数据。然后,decode_slice将一个个slice的数据送给driver,送完之后,它就会调用end_frame。end_frame就是告诉driver可以解码了,之后就把数据放到AVFrame的data[3]上。这就是一个Graphic Video memory surface。如果要使用的话,要拿出data[3]。右边是encode,基本上是一个相反的过程。它会接受一个AVFrame,通过encode后,会变换成一个AVpacket数据,就是bitstream数据,会送给Muxer。这里列出了两个接口,一个是VAAPI,一个是QSV。如果调用了VAAPI,就会调用send_frame/receive_packet,之后是encode_issue,它认为参数数据都有了,就会调用vaBeginPicture,它与start_frame是一一对应的,之后就用vaRender把数据都传给driver,再调用EndPicture,就是告诉driver,整帧已经送完。然后调用encode_output,要求做完encode,输出bitstream,并放入AVPacket里面。如果是调用QSV,就简化很多,即调用两个接口即可。一个是EncodeFrameAsync,它是一个异步接口,把帧送给它之后,它在后台编码。或者把当前帧送到FIFO里去,隔几个buffer将帧从FIFO里取出来。之后经过一个SyncOperation,之后就可以拿到bitstream。
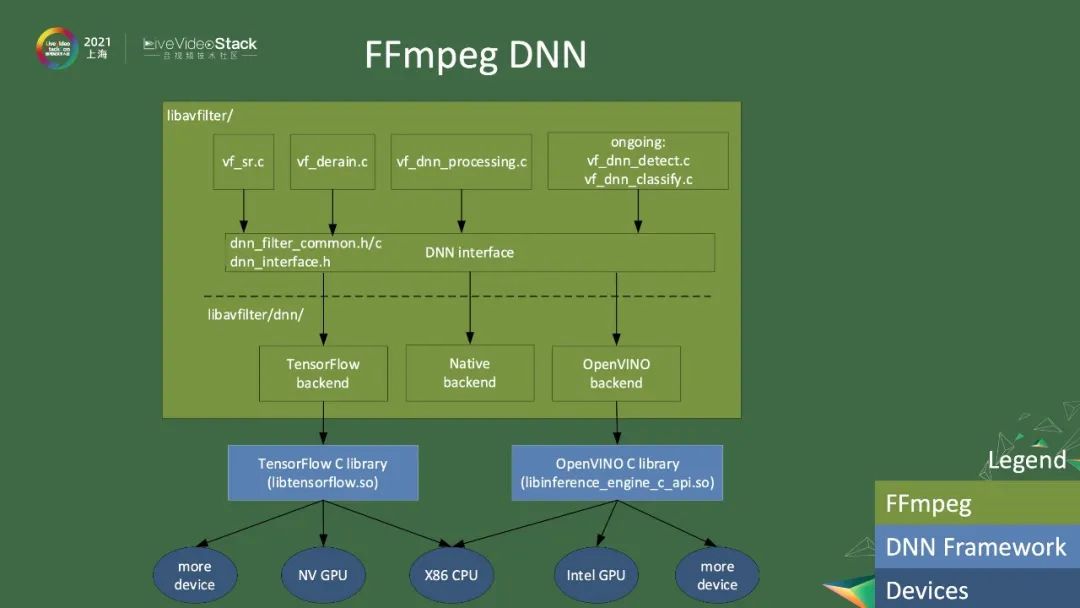
除了传统的FFmpeg encode和decode以外,我们还提供了一些FFmpeg DNN、filter相关的功能。FFmpeg DNN提供了一些基于深度神经网络的功能,可以做到传统filter做不到的事情,比如超分、把雨点去掉、基于DNN的降噪等。我们现在正在做的是基于DNN的detection和分类,以后很多事情都可以在FFmpeg里面完成。所有filter都会调用一个公共的DNN interface,这个interface会被下面三个backend实现。一个是Tensorflow backend,一个是FFmpeg自带的Native backend,还有一个是Intel的OpenVINO backend。不同的backend依赖于不同的外部库。Tensorflow backend依赖于Tensorflow C library,可以调用NVIDIA GPU。OpenVINO backend可以调用Intel GPU等。

我们还提供了一个视频处理库,叫作LibXCam,里面包括360 video stitching、数字降抖动、wavelet denoise以及HDR的处理,还提供了FFmpeg和GStreamer 的filter。这个库在GPU和CPU上做过大量优化,所以对于360 stitching,它能做到大概3个4k,到1个8k的ERP,就是说把三个不同方向上采集到的图像转换成一个环绕360图像。GPU是通过GLES和Vulkan优化的,CPU是通过AVX512优化的。

接下来是搭建优化的pipeline。图中列出了我们开发硬件管线的一些经验。比如很多人会去access decode的帧,把帧取出来后做后处理、编码等操作,然后用CPU访问这些decode的帧。这样做的话,速度就会很慢。主要原因在于,一方面是集成显卡会使用tiled memory,虽然在主存里,但是它没有cache,当CPU去访问它的时候,就是用没有cache的方式。经过我们的测试,访问这个内存,1080p大概会慢30倍左右。另一方面,对于独立显卡,情况就会更加糟糕,因为它会访问总线内存。在这种情况下,最好就是不要去读GPU内存,可以使用GPU上的操作去访问GPU内存,必然可以使用OpenCL,或者OpenGL、Vulkan来进行这些事情。一个简单的例子就是background aware subtitles,因为一个subtitles要根据后面的视频信息合成起来,如果用CPU去访问就会非常慢,但如果用OpenCL的话,因为它们都在GPU上面,速度就会快非常多。如果实在是要这样操作的话,可以使用我们提供的vpp。你可以认为vpp就是DMA的操作,可以从没有cache的内存里面,搬到一块有内存的cache里,这样去访问就会快很多。还有一种方法是用AVX512指令,一次搬运512个字节,或者用AVX2搬运256个字节,搬到有cache的内存里,这样速度就会快很多。

图中列出了一些工具,可以帮助大家观察GPU的状态。因为各种客户的应用场景不一样,有些客户会反映说,负载太低,或者fps太低,这时候就可以用开源工具来观察。针对Intel-GPU-Top,上面是GPU的频率,可能因为各种各样的原因,GPU的频率太低,不能达到要求。中间是引擎。第一个是Render引擎,包含了3D、OpenCL和vpp等,如果同时用3D和vpp操作,这个引擎的占用率就会很高。第二个是Blitter引擎,包含在CPU和GPU之间互相复制数据的操作,占用率一般不会很高。第三个引擎是Video,包含了decoder和encoder的硬件操作,尽量用满,硬件的功能才能完全发挥。第四个引擎是VideoEnhance,如果发现Render使用率过高,我们还提供了一个LowPower的方式,虽然质量稍低,但是可以做Video post process这些操作,把这些负载都移到这边,那么整体的负载就会均衡一些。像这张图一样,你会发现,任何引擎的使用率都不高,那就说明系统里有一些相互依赖的关系,要么去解决这些依赖关系,要么就多开一些实例把某一个引擎占满,那这个引擎就会成为你的系统瓶颈。

最后是参考文献,大家有空可以看看。
谢谢大家!


详情请扫描图中二维码或点击阅读原文了解大会更多信息。
以上是关于OneVPL与FFmpeg/GStreamer硬件编解码器的主要内容,如果未能解决你的问题,请参考以下文章
音视频处理基础框架介绍,FFmpegGStreamerOpenCVOpenGL