创建和分析 Java 堆转储(Heap Dumps)
Posted 守夜人爱吃兔子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了创建和分析 Java 堆转储(Heap Dumps)相关的知识,希望对你有一定的参考价值。
作为 Java 开发人员,我们熟悉我们的应用程序抛出 OutOfMemoryErrors 或我们的服务器监控工具抛出警报并抱怨 JVM 内存利用率高。
要调查内存问题,通常首先要查看 JVM 堆内存。
要进行此操作,我们可以先触发程序抛出 OutOfMemoryError,然后捕获堆转储。接下来我们将分析这个堆转储,以确定可能导致内存泄漏的潜在对象。
什么是堆转储(Heap Dumps)?
每当我们通过创建类的实例来创建 Java 对象时,它总是放置在称为堆的区域中。 Java 运行时的类也在这个堆中创建。
JVM 启动时会创建堆。它在运行时扩展或收缩以适应在我们的应用程序中创建或销毁的对象。
当堆满时,垃圾收集过程将运行以收集不再被引用的对象(即程序不再使用它们)。
堆转储包含Java应用程序当前正在使用的一些存活对象实例(注意:在堆内存中的存活对象)的快照。我们可以获得每个对象实例的详细信息,例如地址、类型、类名或大小,以及该实例是否有其他对象的引用。
堆转储有两种格式:
- 经典格式(the classic format)
- 便携式堆转储 (PHD) 格式(the Portable Heap Dump (PHD) format)
PHD 是默认格式。经典格式是人类可读的,因为它是 ASCII 文本,但 PHD 格式是二进制的,应通过适当的工具进行处理以进行分析。
生成 OutOfMemoryError 的示例程序
为了解释堆转储的分析,我们将使用一个简单的 Java 程序来生成 OutOfMemoryError:
public class OOMGenerator {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
System.out.println("Max JVM memory: " + Runtime.getRuntime().maxMemory());
try {
ProductManager productManager = new ProductManager();
productManager.populateProducts();
} catch (OutOfMemoryError outofMemory) {
System.out.println("Catching out of memory error");
throw outofMemory;
}
}
}public class ProductManager {
private static ProductGroup regularItems = new ProductGroup();
private static ProductGroup discountedItems = new ProductGroup();
public void populateProducts() {
int dummyArraySize = 1;
for (int loop = 0; loop < Integer.MAX_VALUE; loop++) {
if(loop%2 == 0) {
createObjects(regularItems, dummyArraySize);
}else {
createObjects(discountedItems, dummyArraySize);
}
System.out.println("Memory Consumed till now: " + loop + "::"+ regularItems + " "+discountedItems );
dummyArraySize *= dummyArraySize * 2;
}
}
private void createObjects(ProductGroup productGroup, int dummyArraySize) {
for (int i = 0; i < dummyArraySize; ) {
productGroup.add(createProduct());
}
}
private AbstractProduct createProduct() {
int randomIndex = (int) Math.round(Math.random() * 10);
switch (randomIndex) {
case 0:
return new ElectronicGood();
case 1:
return new BrandedProduct();
case 2:
return new GroceryProduct();
case 3:
return new LuxuryGood();
default:
return new BrandedProduct();
}
}
}我们通过运行 for 循环持续分配内存,直到到达某个点,当 JVM 没有足够的内存来分配时,导致抛出 OutOfMemoryError。
查找 OutOfMemoryError 的根本原因
我们现在将通过堆转储分析来找出此错误的原因。这分两步完成:
- 捕获堆转储
- 分析堆转储文件,定位可疑原因。
我们可以通过多种方式捕获堆转储。让我们首先使用 jmap 捕获我们示例的堆转储,然后在命令行中传递一个 VM 参数。
使用 jmap 按需生成堆转储
jmap工具 与 JDK 打包在一起,并将堆转储提取到指定的文件位置。
要使用 jmap 生成堆转储,我们首先使用 jps 工具找到我们正在运行的 Java 程序的进程 ID,以列出我们机器上所有正在运行的 Java 进程:

运行 jps 命令后,我们可以看到进程以“ ”格式列出。
接下来,我们运行 jmap 命令来生成堆转储文件:
jmap -dump:live,file=mydump.hprof 41927运行此命令后,将创建扩展名为 hprof 的堆转储文件。
选项 -dump:live 用于仅收集在运行代码中仍有引用的活动对象。使用 live 选项时,会触发完整的 GC 以清除无法访问的对象,然后仅转储有引用的活动对象。
在 OutOfMemoryErrors 上自动生成堆转储
此选项用于在发生 OutOfMemoryError 时自动捕获堆转储。这有助于诊断问题,因为我们可以看到哪些对象位于内存中,以及它们在 OutOfMemoryError 发生时占用的内存百分比。
我们将在我们的示例中使用此选项,因为它可以让我们更深入地了解崩溃的原因。
让我们从命令行或我们最喜欢的 IDE 使用 VM 选项 HeapDumpOnOutOfMemoryError 运行程序以生成堆转储文件:
java -jar target/oomegen-0.0.1-SNAPSHOT.jar \\
-XX:+HeapDumpOnOutOfMemoryError \\
-XX:HeapDumpPath=hdump.hprof使用这些 VM 参数运行我们的 Java 程序后,我们得到以下输出:
Max JVM memory: 2147483648
Memory Consumed till now: 960
Memory Consumed till now: 29760
Memory Consumed till now: 25949760
java.lang.OutOfMemoryError: Java heap space
Dumping heap to /hdump.hprof …
Heap dump file created [17734610 bytes in 0.031 secs]
Catching out of memory error
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at io.pratik.OOMGenerator.main(OOMGenerator.java:25)从输出中可以看出,当 OutOfMemoryError 发生时,会创建名为 hdump.hprof 的堆转储文件。
生成堆转储的其他方法
生成堆转储的其他一些方法是:
- jcmd:jcmd 用于向JVM 发送诊断命令请求。它被打包为 JDK 的一部分。它可以在 Java 安装的 \\bin 文件夹中找到。
- JVisualVM:通常,分析堆转储需要比实际堆转储大小更多的内存。如果我们试图在开发机器上分析来自大型服务器的堆转储,这可能会出现问题。 JVisualVM 提供了堆内存的实时采样,因此它不会占用整个内存。
分析堆转储(Heap Dump)
我们在堆转储中寻找的是:
- 内存使用率高的对象
- 用于识别未释放内存的对象的对象图
- 可达和不可达对象
Eclipse Memory Analyzer (MAT) 是分析 Java 堆转储的最佳工具之一。让我们通过分析我们之前生成的堆转储文件来了解使用 MAT 进行 Java 堆转储分析的基本概念。
我们将首先启动内存分析器工具并打开堆转储文件。在 Eclipse MAT 中,报告了两种类型的对象大小:
- 浅堆大小(Shallow heap size):对象的浅堆是它在内存中的大小
- 保留堆大小(Retained heap size):保留堆是对象被垃圾回收时将释放的内存量。
MAT 中的概述部分
打开堆转储后,我们将看到应用程序内存使用情况的概览。饼图在概览选项卡中按保留大小显示最大的对象,如下所示:
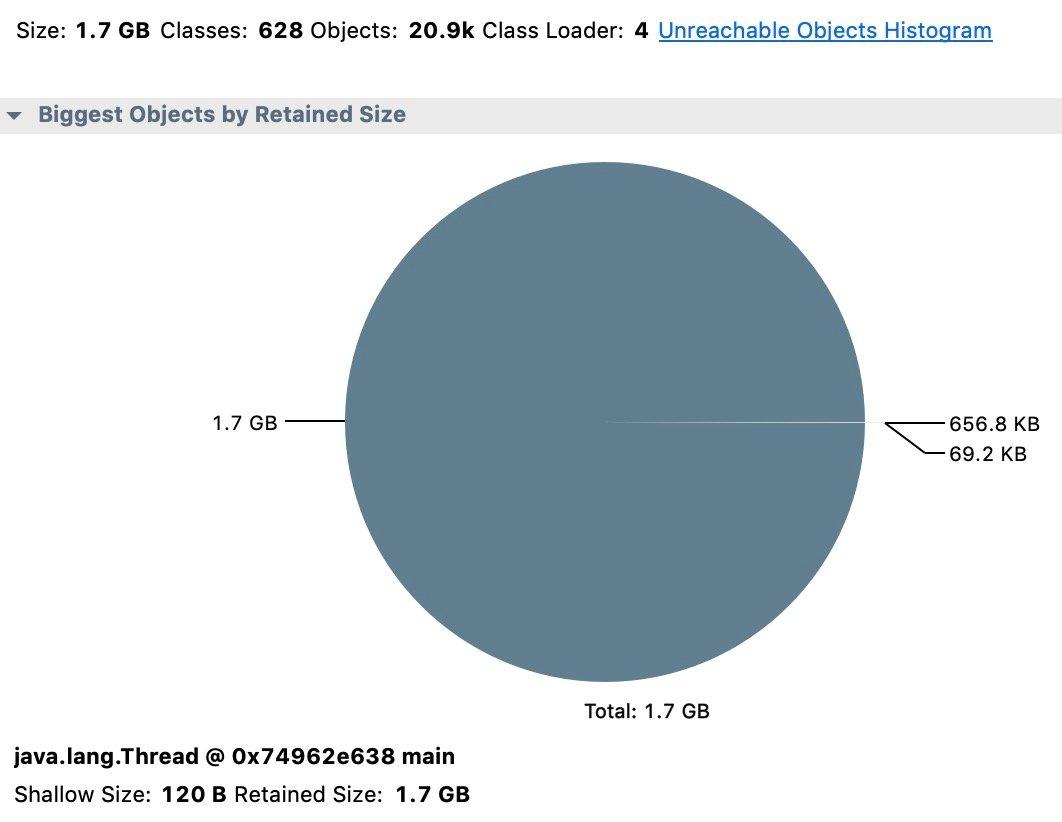
对于我们的应用程序,概述中的这些信息意味着如果我们可以处理 java.lang.Thread 的特定实例,我们将节省 1.7 GB,以及该应用程序中使用的几乎所有内存。
直方图视图
虽然这看起来很有希望,但 java.lang.Thread 不太可能是这里的真正问题。为了更好地了解当前存在哪些对象,我们将使用直方图视图:

我们使用正则表达式“io.pratik.*”过滤了直方图,以仅显示与模式匹配的类。通过此视图,我们可以看到活动对象的数量:例如,系统中有 243 个 BrandedProduct 对象和 309 个Price对象。我们还可以看到每个对象使用的内存量。
有两种计算,浅堆(Shallow heap)和保留堆(Retained heap)。浅堆是一个对象消耗的内存量。对于每个引用,对象需要 32(或 64 位,取决于体系结构)。整数和长整型等基元需要 4 或 8 个字节,等等……虽然这可能很有趣,但更有用的指标是保留堆。
保留堆大小(Retained Heap Size)
保留堆大小是通过将保留集中所有对象的大小相加来计算的。保留的 X 集是垃圾收集器在收集 X 时将删除的对象集。
保留堆可以通过两种不同的方式计算,使用快速近似或精确保留大小:
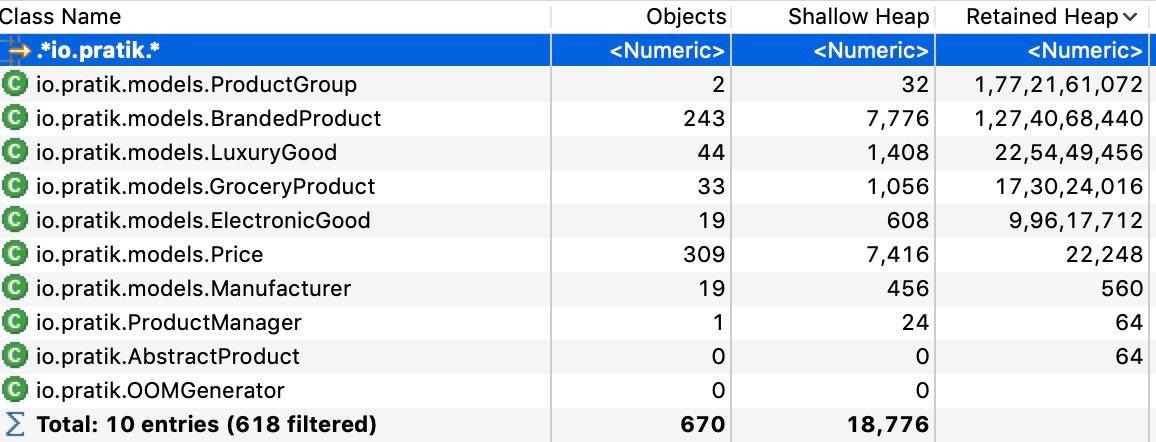
通过计算保留堆,我们现在可以看到 io.pratik.ProductGroup 占据了大部分内存,即使它本身只有 32 字节(浅堆大小)。通过找到释放这个对象的方法,我们当然可以控制我们的内存问题。
支配树(Dominator Tree)
支配树用于标识保留的堆。它由运行时生成的复杂对象图生成,有助于识别最大的内存图。如果从根到 Y 的每条路径都必须经过 X,则称对象 X 支配对象 Y。
查看我们示例的支配树,我们可以看到哪些对象保留在内存中。
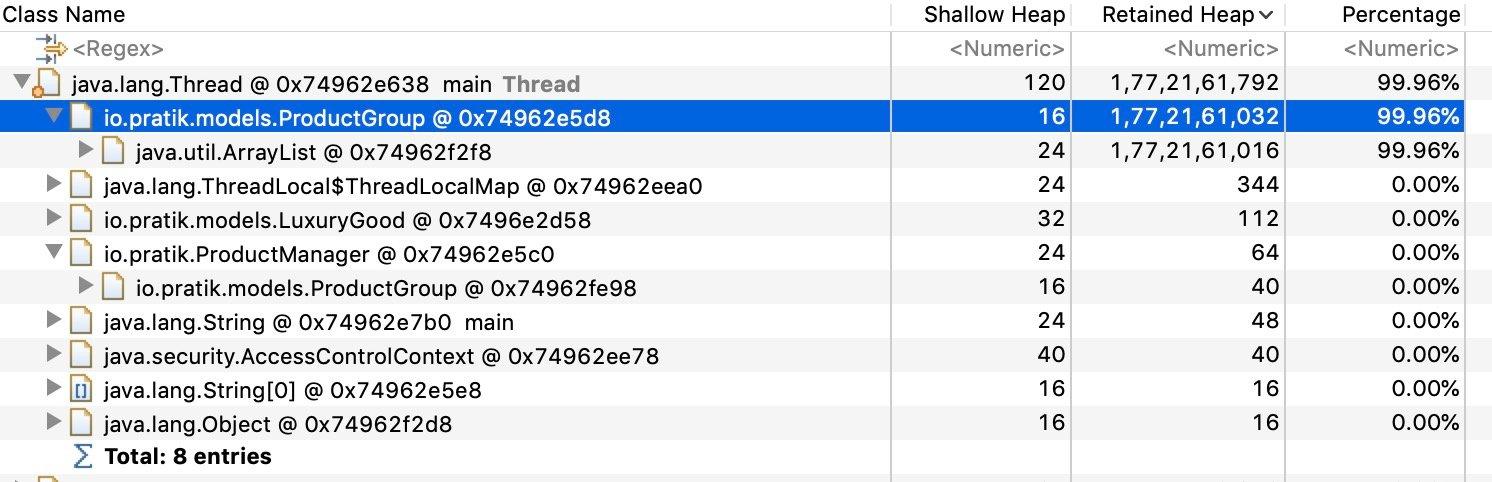
我们可以看到 ProductGroup 对象持有内存而不是 Thread 对象。我们或许可以通过释放这个对象中包含的对象来解决内存问题。
泄漏嫌疑报告(Leak Suspects Report)
我们还可以生成“泄漏嫌疑报告”以查找疑似大对象或对象集。此报告在 html 页面上显示调查结果,并且还保存在堆转储文件旁边的 zip 文件中。
由于其较小,最好与专门执行分析任务的团队共享“泄漏可疑报告”报告,而不是原始堆转储文件。
该报告有一个饼图,其中给出了可疑对象的大小:
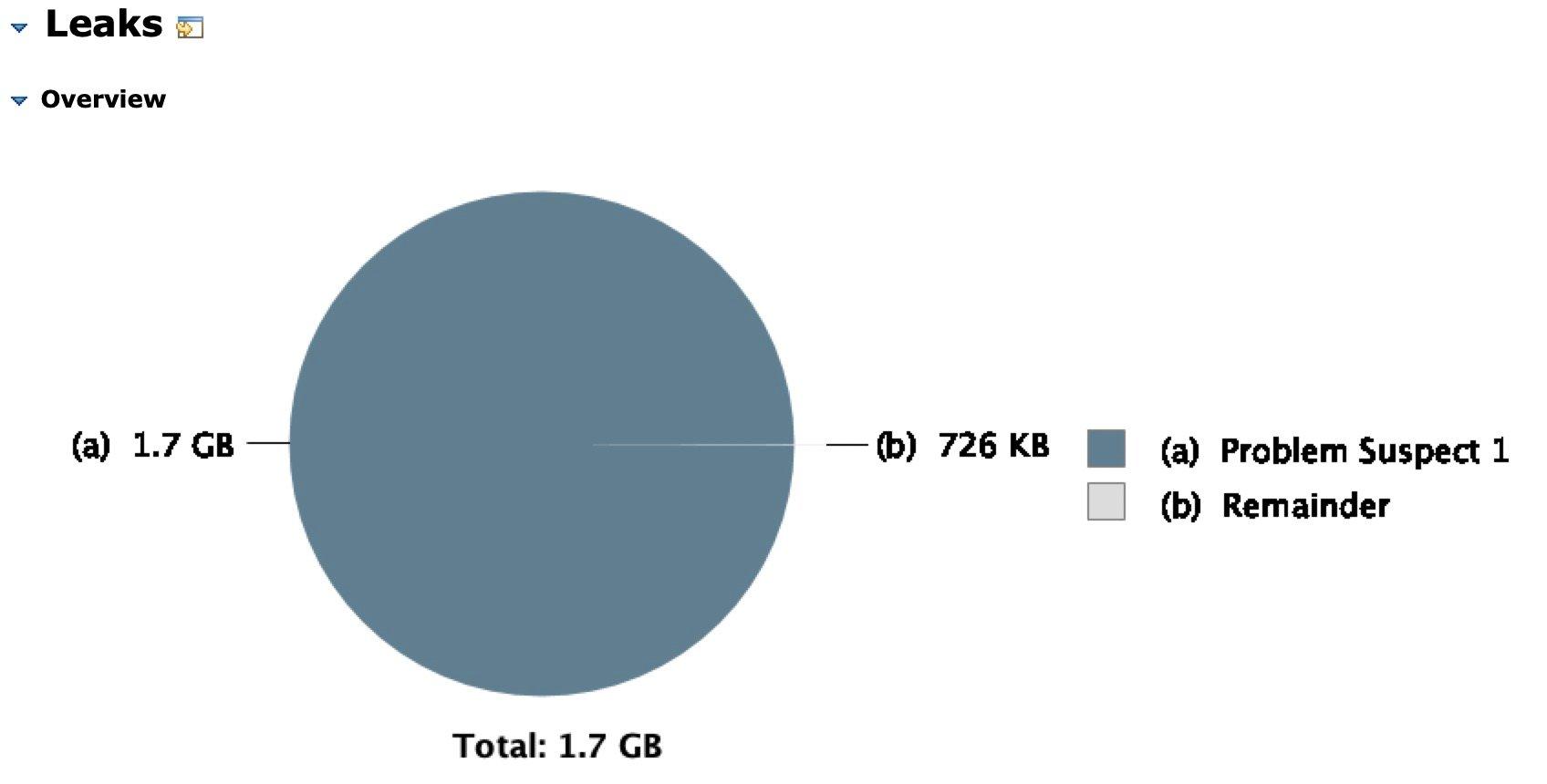
对于我们的示例,我们标记了一个嫌疑问题,并用简短描述进一步描述:
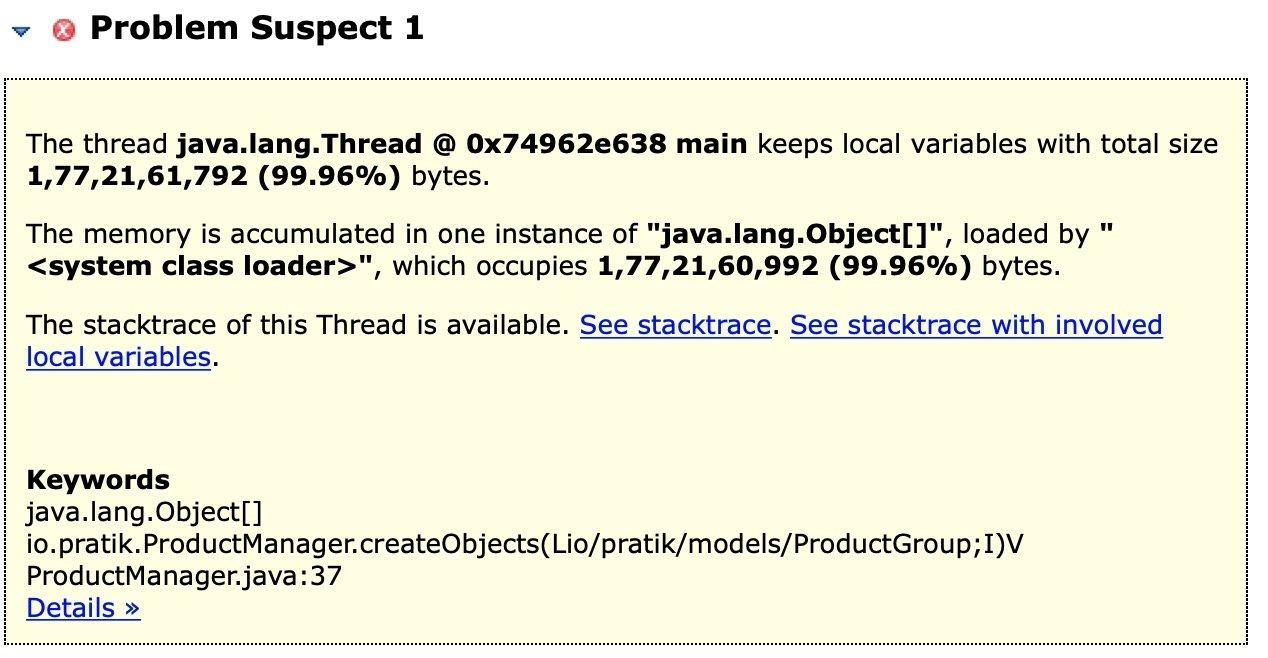
除摘要外,本报告还包含有关嫌疑问题的详细信息,可通过报告底部的“详细信息”链接访问:
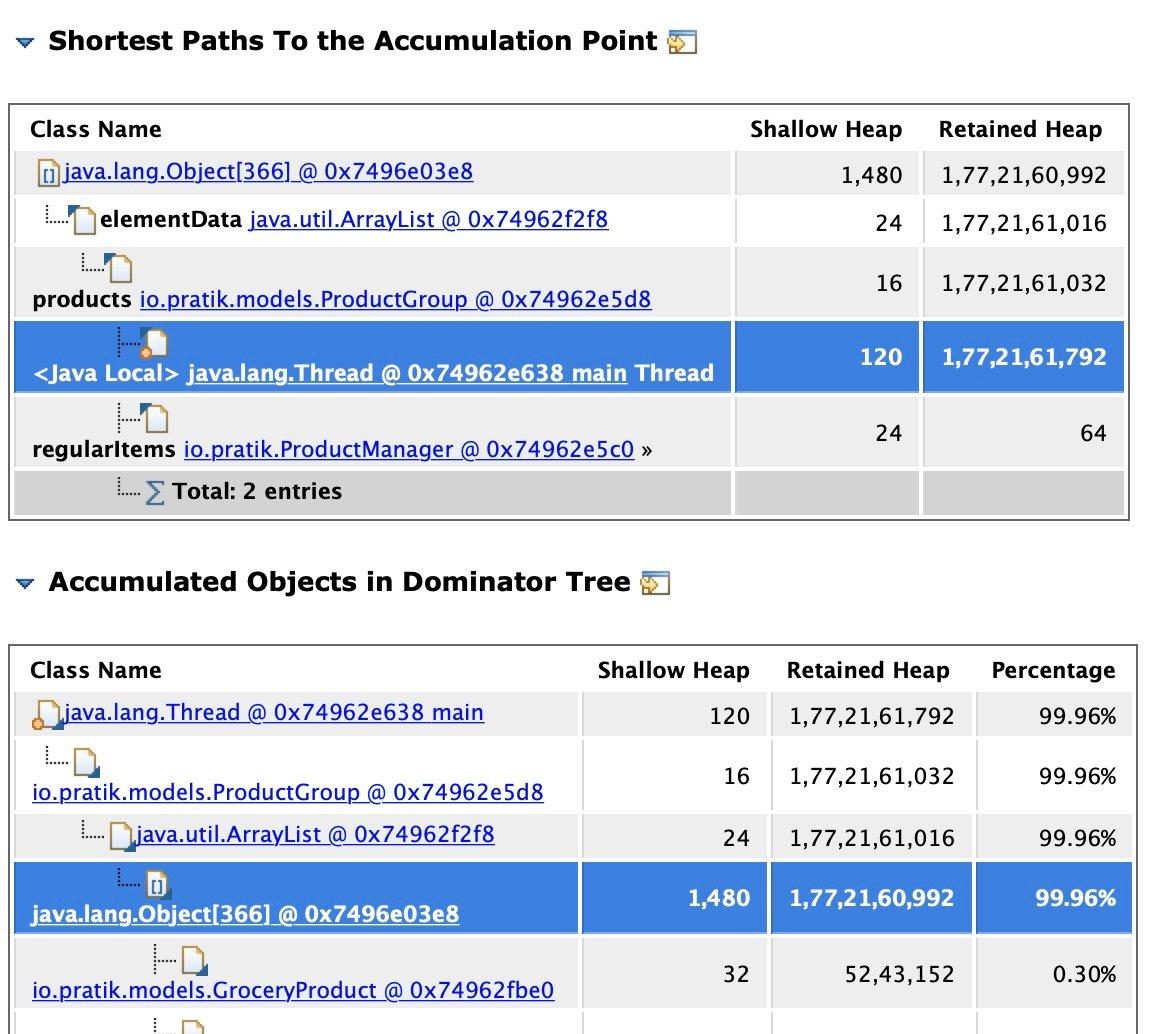
详细信息包括:
- 从GC根到累积点的最短路径:在这里我们可以看到引用链所经过的所有类和字段,这很好地理解了对象是如何保持的。在此报告中,我们可以看到从 Thread 到 ProductGroup 对象的引用链。
- 支配树中的累积对象:这提供了一些关于累积内容的信息,这些内容是此处的 GroceryProduct 对象的集合。
总结
在这篇文章中,我们介绍了堆转储,它是 Java 应用程序运行时对象内存图的快照。为了说明这一点,我们从一个在运行时抛出 OutOfMemoryError 的程序中捕获了堆转储。
然后我们查看了使用 Eclipse Memory Analyzer 进行堆转储分析的一些基本概念:大对象、GC 根、浅堆与保留堆以及支配树,所有这些都将帮助我们确定特定内存问题的根本原因。
最后
最近我整理了整套《JAVA核心知识点总结》,说实话 ,作为一名Java程序员,不论你需不需要面试都应该好好看下这份资料。拿到手总是不亏的~我的不少粉丝也因此拿到腾讯字节快手等公司的Offer
进【Java进阶之路群】,找管理员获取哦-!

以上是关于创建和分析 Java 堆转储(Heap Dumps)的主要内容,如果未能解决你的问题,请参考以下文章