复制黏贴就能实现简单爬虫?小白现身教学!
Posted kasami_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了复制黏贴就能实现简单爬虫?小白现身教学!相关的知识,希望对你有一定的参考价值。
我们经常看到CSDN上有一些文章,有上千上万的阅读量,看看点赞数评论数和收藏数却空空如也。

难道是我们这些读者太懒了吗?只愿意当白嫖党吗?
非也非也,有可能是因为他们使用了爬虫来刷阅读量。
本文将以一位只学过C语言的python小白角度带领大家简单应用爬虫技术。
这篇文章只供大家学习,切勿用于违法途径。
阅读量的多少反映不出什么,是驴子是马拿出来遛一遛便知。
我用的编译器是VSCODE,并安装好了python环境。大家可自行搜索相关教程。
这是我们引入的库
requests用于将链接转化成html语言,而BeautifulSoup则用于查找需要的内容。
from bs4 import BeautifulSoup
import requests
import time
import random
如果同学们没有安装某个库的话,会报错
比如
import "bs4" can not be resolved
解决:首先确保你安装了BeautifulSoup4
在命令行中敲
pip install beautifulsoup4
然后在命令行打开python
python
引入bs4
import bs4
如果没有异常就表示成功了。
如果导入成功还显示以上错误,可稍等片刻重启试试。
其他也类同
接下来是定义我们要爬的网页地址url
url =('https://www.baidu.com')
然后是定义我们的header
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
对于网络爬虫来说header是很重要的一环,因为有些网站只认可浏览器发送的访问请求。
要获取我们的header,大家可以按照以下步骤查询
-
打开网页
-
按F12进入开发者模式
-
选择网络
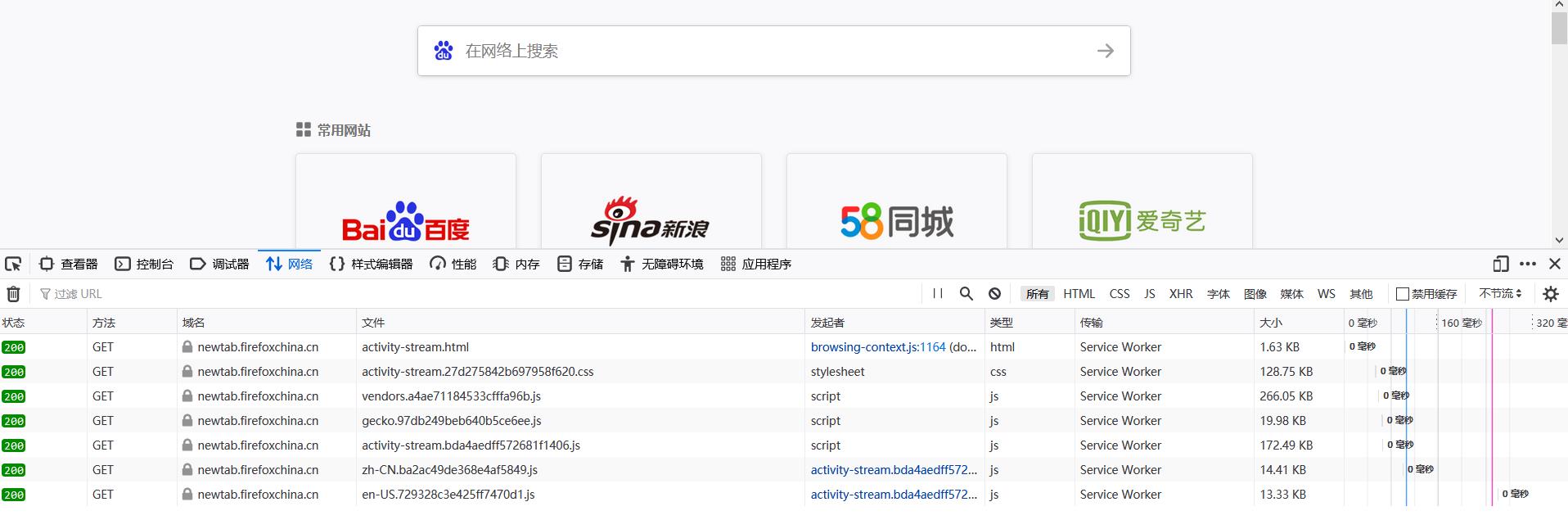
-
点击一项进去
-
右下角可以看到User-Agent
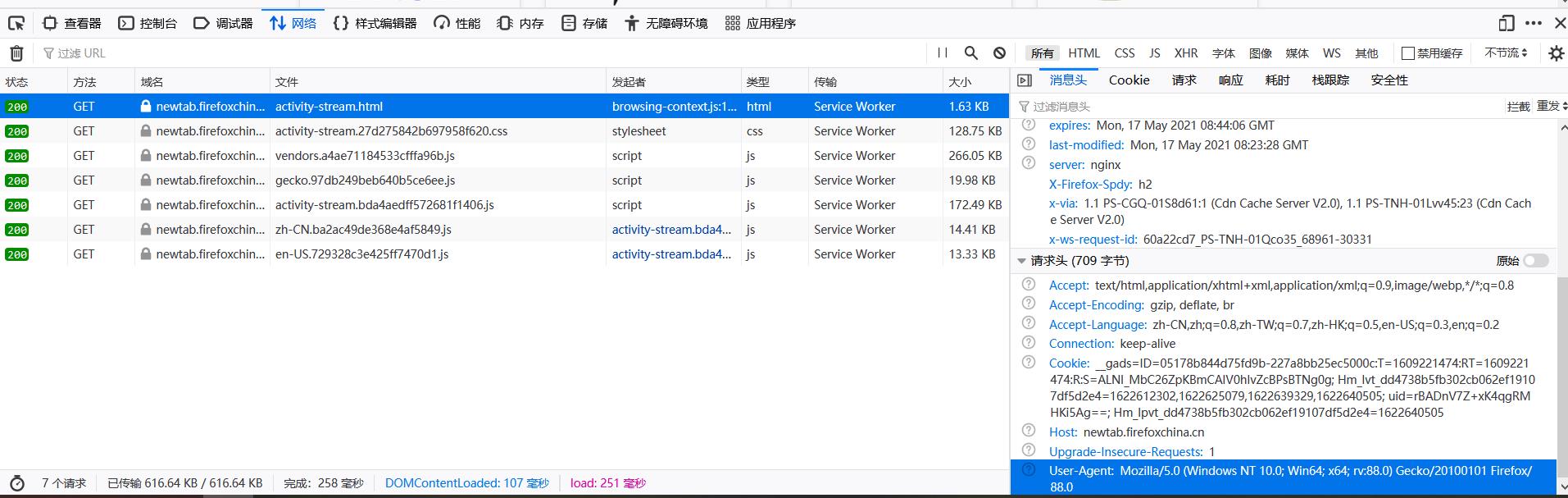
如果在运行的时候报错:
AttributeError: 'set' object has no attribute 'items'
这是因为headers是一个字典,不是字符串,所以报错了,是粘贴复制的时候出错了,把User-Agent给漏了
然后是一个循环爬取
for i in range(10000):
time.sleep(random.randint(30,90))
req = requests.get(url,headers =headers )
soup = BeautifulSoup(req.text,'lxml')
title = soup.select('title')
print (title)
print (i)
我们在这里只爬取网页内的title元素,大家可以根据自己的需要更改。
在爬取数据的时候为了防止 IP被封,我们选择降低访问速度。可以使用 time模块中的sleep,使程序每运行一次后就睡眠随机时间(random模块),这样的话就可以大大的减少ip被封的几率

如果在运行中出现了这样的错误:
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
解决:在命令行中输入以下信息
pip install lxml
“本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/kasami_/article/details/117362772。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。”
以上是关于复制黏贴就能实现简单爬虫?小白现身教学!的主要内容,如果未能解决你的问题,请参考以下文章