横扫六大权威榜单后,达摩院开源深度语言模型体系 AliceMind
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了横扫六大权威榜单后,达摩院开源深度语言模型体系 AliceMind相关的知识,希望对你有一定的参考价值。


整理 | AI 科技大本营(ID:rgznai100)
自然语言处理(NLP)被誉为 AI 皇冠上的明珠,传统 NLP 模型制作复杂,耗时耗力,且用途单一,难以复用。预训练语言模型是 NLP 领域的研究热点之一,“预训练+精调”已成为NLP任务的新范式,当前预训练语言模型正在改变局面,有望让语言 AI 走向入可规模化复制的工业时代。
今日,阿里巴巴达摩院正式开源预训练语言模型体系 AliceMind。历经三年研发,AliceMind 涵盖通用语言模型StructBERT、多语言VECO、生成式PALM、多模态StructVBERT、结构化StructuralLM、知识驱动LatticeBERT、机器阅读理解UED、超大模型 PLUG 等,此次大部分已开源:
https://github.com/alibaba/AliceMind
据了解,AliceMind 从通用语言模型 StructBERT 的基础上,拓展到多语言、生成式、多模态、结构化、知识驱动等领域,能力全面;先后登顶 GLUE 等六大 AI 权威榜单,其中上周再次登顶多模态榜单 VAQ Challenge 2021。
AliceMind 掌握语言超过100种,具有阅读、写作、翻译、问答、搜索、摘要生成、对话等多种能力,目前已成为阿里的语言技术底座,日均调用量超过 50 亿次,活跃场景超过 200 个,已在跨境电商、客服、广告等数十个核心业务应用落地。在阿里之外,AliceMind 广泛运用于医疗、能源、金融等多个行业。其中,浙江电网公司以 AliceMind 为底座为员工构建智能化运维平台,应用于变压器检修、供电抢修等业务,开始在国家电网公司统一推广。
AliceMind 拥有以下 8 大技术创新点:

通用语言模型(StructBERT)
Google 于 2018 年底推出的 BERT 模型是业界广泛使用的自然语言预训练模型,达摩院团队在 BERT 的基础上提出优化模型 StructBERT,让机器更好地掌握人类语法,理解自然语言,2020 年多次在自然语言处理领域顶级赛事 GLUE Benchmark 上夺冠。
StructBERT 通过在句子级别和词级别引入两个新的目标函数,好比给机器内置一个“语法识别器”,使机器在面对语序错乱或不符合语法习惯的词句时,仍能准确理解并给出正确的表达和回应,大大提高机器对词语、句子以及语言整体的理解力。


多语言语言模型(VECO)
跨语言预训练初衷是为多种语言建立起一个统一联合的语义表示,AliceMind 体系内的跨语言预训练模型 VECO 一经提出,便在国际权威多语言榜单 XTREME 排名第一,VECO 目前支持 100 种语言的理解和生成任务。
VECO 效果亮眼,主要是因为两项创新:一是其可以更加“显式”得进行跨语言信息的建模(图1);二是 VECO 在预训练的过程充分学习用于语言理解(NLU)和生成(NLG)任务,并让二者互相学习提高彼此(图2)。因此,VECO 模型成为了多语言领域内的第一个同时在多语言理解(NLU)和语言生成(NLG)任务上均取得业内最佳效果的模型,也被顶会 ACL2021 录用。
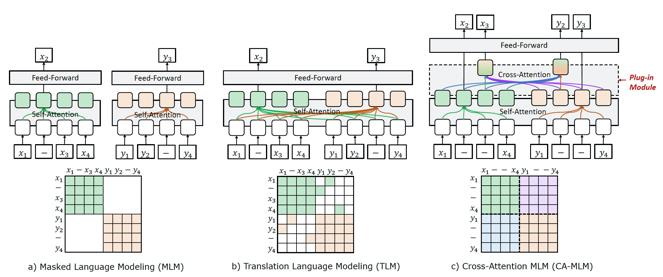
图1
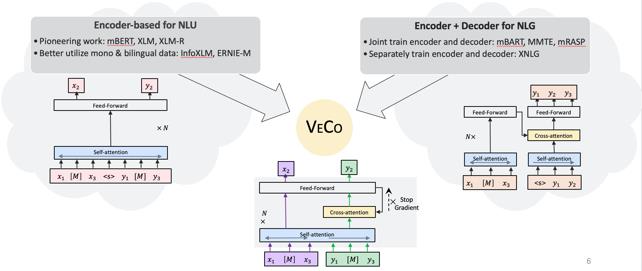
图2

生成式语言模型(PALM)
PALM 采用了与之前的生成模型不同的预训练方式,将预测后续文本作为其预训练目标,而非重构输入文本。PALM 在一个模型中使用自编码方式来编码输入文本,同时使用自回归方式来生成后续文本。这种预测后续文本的预训练促使该模型提高对输入文本的理解能力,从而在下游的各个语言生成(NLG)任务上取得更好的效果。
PALM 在 MARCONLG 自然语言生成公开评测上取得了排行榜第一,同时在摘要生成标准数据集 CNN/DailyMail和Gigaword 上也超过了现有的各个预训练生成语言模型。PALM 可被用于问答生成、文本复述、回复生成、文本摘要、Data-to-Text 等生成应用上。


多模态语言模型(StructVBERT)
StructVBERT 是在通用的 StructBERT 模型基础上,同时引入文本和图像模态,在统一的多模态语义空间进行联合建模,在单流架构的基础上同时引入图像-文本描述数据和图像问答数据进行多任务预训练,并在多尺度的图像特征上进行分阶段预训练。此外,模型利用attention mask矩阵控制实现双流架构,从而提升跨模态双流建模能力,结合单流、双流结构的优点进一步提升模型对文本和图像两个模态的理解能力。关联文章已被 ACL2020 录用。


结构化语言模型(StructuralLM)
StructuralLM 在语言模型 StructBERT 的基础上扩展到结构化语言模型,充分利用图片文档数据的 2D 位置信息,并引入 box 位置预测的预训练任务,帮助模型感知图片不同位置之间词语的关系,这对于理解真实场景中的图片文档十分重要。Structural LM模型在 DocVQA 榜单上排名第一,同时在表单理解 FUNSD 数据集和文档图片分类 RVL-CDIP 数据集上也超过现有的所有预训练模型。
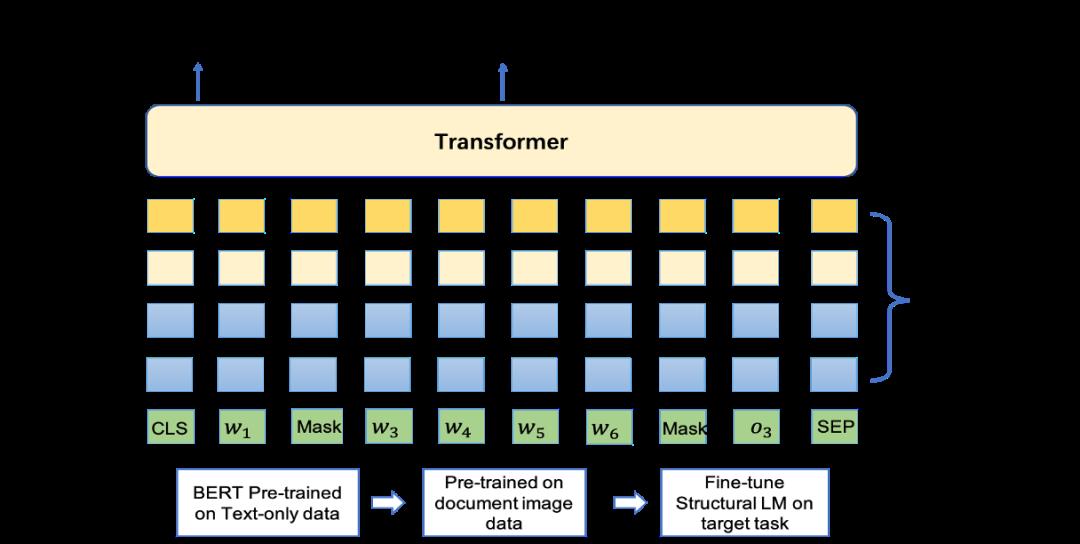

机器阅读理解模型(UED)
自最开始声名大噪的SQuAD榜单起,阿里围绕着机器阅读理解发展路线:单段落抽取->多文档抽取/检索->多文档生成->开放式阅读理解,拿下了一系列的榜单冠军:
2018 年在单段落机器阅读理解领域顶级赛事 SQuAD 上首次超出人类回答精准率。
2018 年在多文档机器阅读理解权威比赛TriviaQA和DuReader上双双刷新纪录,取得第一名。
2019年在信息检索国际顶级评测TREC 2019 Deep Learning Track上的段落检索和文档检索任务上均取得第一名。
2019年在机器阅读理解顶级赛事MS MARCO的段落排序、多文档答案抽取以及多文档答案生成3个任务均取得第一名,并在多文档答案抽取任务上首次超越人类水平。


超大规模中文理解和生成统一模型(PLUG)
PLUG 是目前中文社区已开放 API 的最大规模的纯文本预训练语言模型,集语言理解与生成能力于一身。PLUG 可为目标任务做针对性优化,通过利用下游训练数据 finetune 模型使其在该特定任务上生成质量达到最优,弥补之前其它大规模生成模型 few-shotinference 的生成效果不足,适于应用在实际生成任务。同时,PLUG 采用 encoder-decoder 的双向建模方式,因此,在传统的 zero-shot 生成的表现上,无论是生成的多样性,领域的广泛程度,还是生成长文本的表现,较此前的模型均有明显的优势。
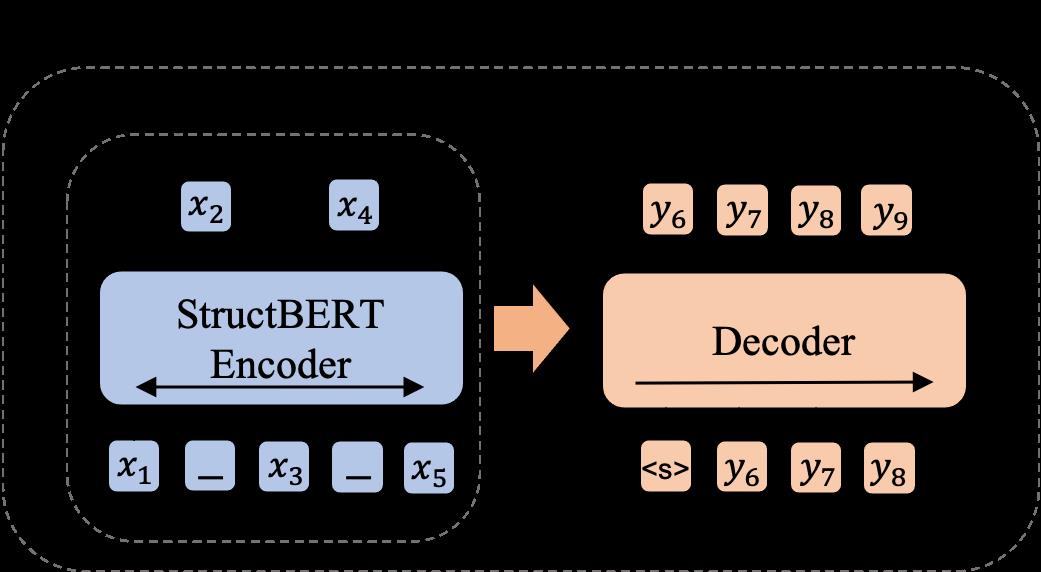

知识驱动的语言模型 LatticeBERT
LatticeBERT 在预训练模型中训练中有效地融合了词典等知识,从而能够同时建模字和词的结构,来线性化地表示这种混合粒度的输入。第一步是将涵盖多粒度字词信息的中文文本用词格(Lattice)表示起来,再把这个词格线性化作为BERT 的输入。LatticeBERT 在 2020 年 9 月达到中文予以理解评估基准 CLUE 榜单的 base 模型中的第一名。

传送门:
https://github.com/alibaba/AliceMind/
更多了解:
通用预训练模型StructBERT: https://arxiv.org/abs/1908.04577
多语言预训练模型 VECO: https://arxiv.org/abs/2010.16046
生成式预训练模型PALM: https://arxiv.org/abs/2004.07159
多模态预训练模型E2E-VLP: https://arxiv.org/abs/2106.01804
结构化预训练模型StructuralLM:https://arxiv.org/abs/2105.11210
融合知识的预训练模型 Lattice-BERT: https://arxiv.org/abs/2104.07204

更多精彩推荐
这篇论文,透露谷歌团队构想的“未来搜索”
盛夏海边,用Python分析青岛哪些景点性价比高
搞深度学习框架的那帮人,不是疯子,就是骗子
点分享点收藏点点赞点在看
以上是关于横扫六大权威榜单后,达摩院开源深度语言模型体系 AliceMind的主要内容,如果未能解决你的问题,请参考以下文章
AI中文语言理解得分首超人类,阿里达摩院创造新纪录,大模型又立功了
北大95后「AI萝莉」回来了,一次中8篇顶会论文的她,现在达摩院开源7大NLP模型