spark剖析:spark读取parquet文件会有多少个task
Posted 甄情
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark剖析:spark读取parquet文件会有多少个task相关的知识,希望对你有一定的参考价值。
前言
做大数据开发的肯定都知道小文件的弊端
- 读取阶段:
spark在读取文件时会根据文件的数量以及文件的大小来切分文件生成task。一般task数是大于等于文件数的,如果都是小于128M的文件就是等于文件数。小文件越多,task数越多,单个task处理的数据量就少,如果并行度不够会导致查询数据过慢。 - 写入阶段:如果你的数据是存储到类似于
cos、oss、s3等对象存储中,spark最后移动文件的rename阶段如果出现大量的小文件,性能低的会让你疯掉(毕竟rename在这些对象存储底层分两步copy和delete)。最后发现整个ETL任务的绝大部分时间用来rename
所以为了优化小文件的问题,我们目前对所有的ETL任务执行结束会输出当前分区的文件数、文件大小。如下图:
然后让开发者根据该信息在 insert 之前对数据进行REPARTITION来达到控制文件数量的目的。
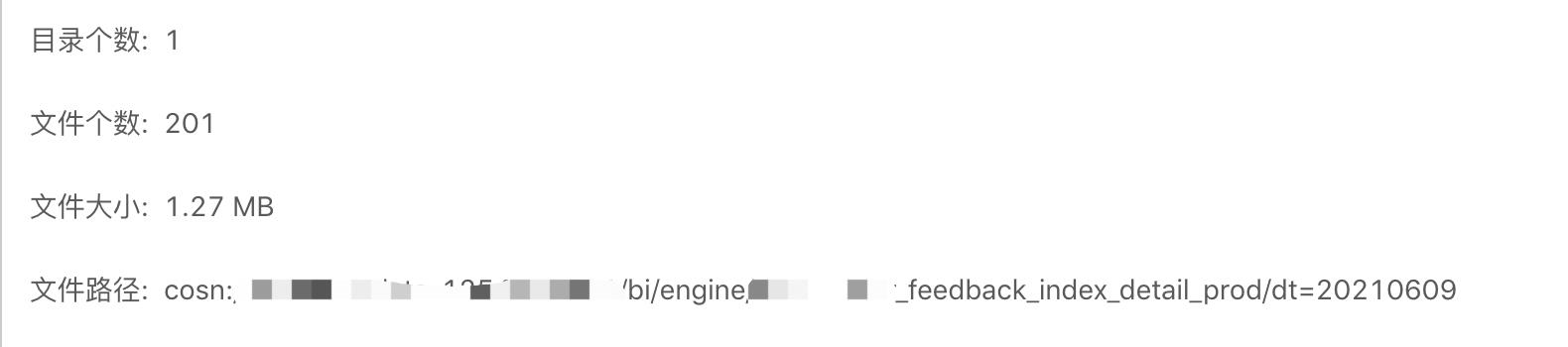
但是最近发现一个问题,某位同学的 spark sql 任务执行完成后生成了 200个文件,总大小为3M附近(如下图),但是在读取的时候 spark生成的 task数只有 8 个,和我们想象中的200个 task 不一致,究竟原因在哪里?


对象存储问题?
由于我们大数据集群是计算存储分离的架构,所有的数据都存储在对象存储上,我首先怀疑是由于我们用的对象存储的原因。所以我特意 copy了一份数据存储到HDFS上(bi_ods_real.sucx_test1表的 location 在 HDFS)
spark-sql --master yarn -e "insert overwrite table bi_ods_real.sucx_test1 select /*+ repartition(200) */ * from bi_dw_plan.dws_order_****_order_df where dt='20210607'"
为了和对象存储表文件数一致,在这里加上了
/*+ repartition(200) */,如果不加只有8个文件
表的文件数量和大小如下图:

对 default.sucx_test1 进行查询
发现task数确实有200个,难道真的是存储不同的原因?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~心~~~~~~~~~~~~累~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
中间经历了一系列的弯路,就不再赘述。最后我通过查看他们的物理执行计划,发现了一点不同点。
-
对于
HDFS表

-
对于
cos表

于是我查看两张表的建表语句发现
HDFS表 的存储格式是textfile
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://172.0.0.1:8080/usr/hive/warehouse/bi_ods_real.db/sucx_test1'
cos 表存储格式为 parquet
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\\t',
'serialization.format'='\\t')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'cosn://***/bi/bi_dw_plan/dws_order_****_order_df'
难道是存储格式的问题?
存储格式问题?
于是我又创建了一张 location 在 HDFS,并且存储格式为 parquet 的表,发现读取时并行度也是只有 8 个,于是断定关于上面 spark task 数的问题和 hdfs、cos 无关,和数据的存储格式有关。
spark读取parquet格式文件
由于本地没有 hadoop 环境,为了测试 spark 读取 parquet 文件如何切分文件,我写了一个读取 parquet 文件的方法
@Test
public void test() {
//创建sparkSession
SparkSession sparkSession = SparkSession.builder()
.master("local[1]")
.getOrCreate();
//读取parquet文件
Dataset<Row> parquet = sparkSession.read().parquet("/Users/scx/part-00199-b7613270-858d-4bc8-ad89-badd66bd9c24-c000.snappy.parquet");
//结果显示
parquet.show(false);
}
通过 debug 查看堆栈信息发现程序会走到 FilePartition#maxSplitBytes
def maxSplitBytes(
sparkSession: SparkSession,
selectedPartitions: Seq[PartitionDirectory]): Long = {
val defaultMaxSplitBytes = sparkSession.sessionState.conf.filesMaxPartitionBytes
val openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes
val defaultParallelism = sparkSession.sparkContext.defaultParallelism
val totalBytes = selectedPartitions.flatMap(_.files.map(_.getLen + openCostInBytes)).sum
val bytesPerCore = totalBytes / defaultParallelism
Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
}
解释代码前,先了解几个配置以及变量
spark.sql.files.maxPartitionBytes单个partition能够读取的最大值,默认为128M.spark.sql.files.openCostInBytes为打开文件需要的成本,是一个预估值,。假设打开一个文件需要时间n,那么在给定的时间n范围内能够读取的字节数.默认该值4 * 1024 * 1024(4M)spark.default.parallelism任务的默认并行度,如果该值没有配置,那么该变量得值和spark任务的资源配置(总totalCoreCount)有关,比如配置executor-cores=n executor-nums=m那么该值为m*n,该值最小为2。具体可以进入CoarseGrainedSchedulerBackend#defaultParallelism查看
知道了上面这些值的含义,我们可以查看 maxSplitBytes 方法了。
defaultMaxSplitBytes的值为spark.sql.files.maxPartitionBytes,即128M,-openCostInBytes的值为spark.sql.files.openCostInBytes,即4MdefaultParallelism的值由于我没有配置,所以为集群默认的资源8(可以通过查看spark-defaults.conf计算)
## spark-defaults.conf
spark.executor.instances 2
spark.executor.cores 4
spark.driver.memory 1024m
spark.executor.memory 1024m
totalBytes该值需要注意,其值为:所有文件大小+文件数*openCostInBytes,在我这里,通过上面截图可以发现所有文件大小大概为3M,文件数为200.计算后得知该值为:803MbytesPerCore该值为totalBytes/defaultParallelism为803M/8=100M
然后进入最后一个函数
Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
代入值后
Math.min(128M, Math.max(4M, 100M))=100M
所以FilePartition#maxSplitBytes 最终返回值为 100M
从上面我们获取到了单个文件分片的最大大小为100M,回到函数上一层DataSourceScanExec#createNonBucketedReadRDD
private def createNonBucketedReadRDD(
readFile: (PartitionedFile) => Iterator[InternalRow],
selectedPartitions: Array[PartitionDirectory],
fsRelation: HadoopFsRelation): RDD[InternalRow] = {
//打开文件的代价,同上4M
val openCostInBytes = fsRelation.sparkSession.sessionState.conf.filesOpenCostInBytes
//上面已经计算过大小为100M
val maxSplitBytes =
FilePartition.maxSplitBytes(fsRelation.sparkSession, selectedPartitions)
logInfo(s"Planning scan with bin packing, max size: $maxSplitBytes bytes, " +
s"open cost is considered as scanning $openCostInBytes bytes.")
//selectedPartitions 指的是我们hive表的partition
val splitFiles = selectedPartitions.flatMap { partition =>
//hive 表partition下的所有文件进行切分
partition.files.flatMap { file =>
// getPath() is very expensive so we only want to call it once in this block:
val filePath = file.getPath
//isSplitable一般都为true,除非你使用了某些不支持分割的压缩算法,在我这里对于parquet表并没有指定压缩算法所以为true。
val isSplitable = relation.fileFormat.isSplitable(
relation.sparkSession, relation.options, filePath)
//第一步:大文件文件切分
PartitionedFileUtil.splitFiles(
sparkSession = relation.sparkSession,
file = file,
filePath = filePath,
isSplitable = isSplitable,
maxSplitBytes = maxSplitBytes,
partitionValues = partition.values
)
}
}.sortBy(_.length)(implicitly[Ordering[Long]].reverse)
//第二步:小文件合并
val partitions =
FilePartition.getFilePartitions(relation.sparkSession, splitFiles, maxSplitBytes)
new FileScanRDD(fsRelation.sparkSession, readFile, partitions)
}
上面代码主要是遍历 hive 表指定分区下的文件,然后对文件进行切分。
大文件切分
下面具体看下 PartitionedFileUtil#splitFiles
def splitFiles(
sparkSession: SparkSession,
file: FileStatus,
filePath: Path,
isSplitable: Boolean,
maxSplitBytes: Long,
partitionValues: InternalRow): Seq[PartitionedFile] = {
//文件是否可以切分
if (isSplitable) {
//如果可以切分则对大文件进行切分,每次的步长为FilePartition#maxSplitBytes获取的100M
(0L until file.getLen by maxSplitBytes).map { offset =>
val remaining = file.getLen - offset
val size = if (remaining > maxSplitBytes) maxSplitBytes else remaining
val hosts = getBlockHosts(getBlockLocations(file), offset, size)
PartitionedFile(partitionValues, filePath.toUri.toString, offset, size, hosts)
}
} else {
Seq(getPartitionedFile(file, filePath, partitionValues))
}
}
def getPartitionedFile(
file: FileStatus,
filePath: Path,
partitionValues: InternalRow): PartitionedFile = {
val hosts = getBlockHosts(getBlockLocations(file), 0, file.getLen)
PartitionedFile(partitionValues, filePath.toUri.toString, 0, file.getLen, hosts)
}
该方法主要是对单大文件进行切分,如果某个文件文件的大小为250M,则切分成3个PartitionedFile。分别为100M,101-200M,201-250M
当然,如果文件不可切分,直接返回该文件。
小文件合并
DataSourceScanExec#createNonBucketedReadRDD 函数里不只做了大文件切分,还为小文件做了合并,真可谓是对 parquet 等文件优化到了极致(为啥 text 格式没这种待遇呢?🤔️)
对于小文件合并就是在FilePartition.getFilePartitions 函数里面做的
def getFilePartitions(
sparkSession: SparkSession,
partitionedFiles: Seq[PartitionedFile],
maxSplitBytes: Long): Seq[FilePartition] = {
val partitions = new ArrayBuffer[FilePartition]
val currentFiles = new ArrayBuffer[PartitionedFile]
var currentSize = 0L
/** Close the current partition and move to the next. */
def closePartition(): Unit = {
if (currentFiles.nonEmpty) {
// Copy to a new Array.
//主要是将多个小文件合并成一个大的partition来供task操作
val newPartition = FilePartition(partitions.size, currentFiles.toArray)
partitions += newPartition
}
currentFiles.clear()
currentSize = 0
}
// 同样是4M
val openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes
// Assign files to partitions using "Next Fit Decreasing"
//在这里的操作主要是对于小于maxSplitBytes大小文件进行合并,对每个文件合并的时候会加上打开文件的代价
partitionedFiles.foreach { file =>
if (currentSize + file.length > maxSplitBytes) {
closePartition()
}
// Add the given file to the current partition.
currentSize += file.length + openCostInBytes
currentFiles += file
}
closePartition()
partitions
}
总结
其实看到这里,我们就能知道为什么我们总文件数为 200,总文件大小为3M 的 parquet 表生成的task数为8个了。为了加深大家的印象,在这里计算下。
首先maxSplitBytes 的大小为 100M,而我们的 200 个文件总大小才为3M,所以在第一步的大文件切分 PartitionedFileUtil#splitFiles 直接返回 200个PartitionedFile,主要是在第二步的小文件合并。3M/200=16K,所以平均每个文件的大小为 16k,相比较于maxSplitBytes的 100M,可以忽略不计,我们主要要考虑的是打开文件的代价openCostInBytes。所以在FilePartition#getFilePartitions 里大概会有 25 个文件合并成一个新的FilePartition(25*openCostInBytes=100M)。
最终形成的FilePartition 个数为200/25=8,该值也就是我们的 task 数
思考
兄弟们,分析完了,开心了。然而学习就要知其然,知其所以然。来思考几个问题
Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))分 区文件的最大大小为什么如此定义?
按照我的理解,如果一个人想要最快的执行完成他的任务,那么他肯定想最大限度的利用集群所有的
core的能力,但是我们的core个数是有限制的,文件的大小是不可控的。所以此时需要一个defaultMaxSplitBytes来控制单个core处理的最大文件大小,避免单个core处理的数据量太大导致频繁full gc或者oom.
PartitionedFileUtil#splitFiles已经对大文件进行切分了,为啥下面还要FilePartition#getFilePartitions对小文件合并?
首先,文件可能由于上游任务reduce task处理的数据量不同生成的文件大小可能不均匀,第二点,大文件切分后可能会生成小文件。综上,需要对小文件进行合并。
spark为啥不对默认的text格式做小文件合并操作?
这个问题我也很疑问,
debug后发现spark对于text格式表的文件读取会生成hadoop rdd,最后使用FileInputFormat读取。而FileInputFormat是属于hadoop-mapreduce包的类,也就是说spark是无法控制的。
- 文件在什么情况下是可分割的(
isSplitable=true)?
一般来说不同格式的非压缩文件都是可分割的,使用了压缩算法后,部分压缩算法不支持分割,比如我们常用的
snappy,而lzo还是支持的分割的
扫码关注,获取最新文章

以上是关于spark剖析:spark读取parquet文件会有多少个task的主要内容,如果未能解决你的问题,请参考以下文章