TensorFlow2 100 行代码实现 VGG13
Posted 我是小白呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow2 100 行代码实现 VGG13相关的知识,希望对你有一定的参考价值。
概述
VGG13 由是 Oxford 的 Visual Geometry Group 组织提出的经典卷积神经网络. VGG13 由 13 层组成, 可以帮助我们实现图像分类问题.

对卷积神经网络没有基础了解的同学可以参考我的这篇文章:
卷积
卷积是一种特助的加群啊求和, 也是一种混合信息的手段. 通过对输入图片大小相同区块和卷积核进行点乘, 然后对不同通道求和.
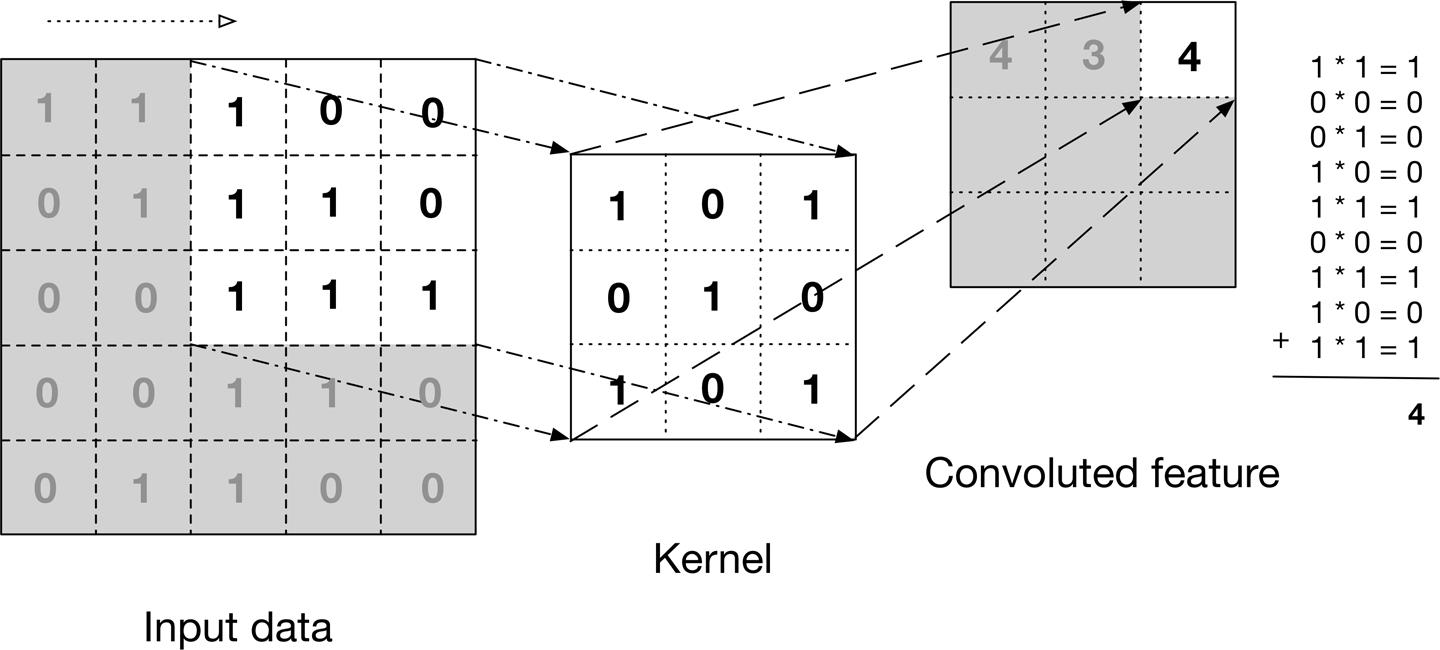
当我们在图像上应用卷积时, 我们分别在 W, L, C 三个维度处理信息. 输入的图像由 R, G, B 三个通道组成, 其中每个通道的元素都是[0, 255] 中的一个数, 例如:

本次我们将使用的 CIFAR 100 数据集就是一个三通道数据集.
代码实现
超参数
# 定义超参数
batch_size = 1024 # 一次训练的样本数目
learning_rate = 0.0001 # 学习率
iteration_num = 5 # 迭代次数
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 优化器
loss = tf.losses.CategoricalCrossentropy(from_logits=True) # 损失
网络模型
# VGG13模型
VGG_13 = tf.keras.Sequential([
# unit 1
tf.keras.layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
tf.keras.layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
tf.keras.layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
tf.keras.layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
tf.keras.layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# 平铺
tf.keras.layers.Flatten(),
# 全连接
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(100)
])
# 调试输出summary
VGG_13.build(input_shape=[None, 32, 32, 3])
print(VGG_13.summary())
获取数据
def pre_process(x, y):
"""
数据预处理
:param x: 特征值
:param y: 目标值
:return: 返回处理好的x, y
"""
x = tf.cast(x, tf.float32) / 255
y = tf.one_hot(y, depth=100)
return x, y
def get_data():
"""
获取数据
:return: 返回分批完的训练集和测试集
"""
# 读取数据
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar100.load_data()
# 压缩目标值
y_train = tf.squeeze(y_train, axis=1) # (50000, 1) => (50000,)
y_test = tf.squeeze(y_test, axis=1) # (10000, 1) => (10000,)
# 分割训练集
train_db = tf.data.Dataset.from_tensor_slices((X_train, y_train))
train_db = train_db.shuffle(10000).map(pre_process).batch(batch_size)
# 分割测试集
test_db = tf.data.Dataset.from_tensor_slices((X_test, y_test))
test_db = test_db.map(pre_process).batch(batch_size)
return train_db, test_db
完整代码
来, 让我们干了这杯酒, 来看完整代码.

完整代码:
import tensorflow as tf
# 定义超参数
batch_size = 1024 # 一次训练的样本数目
learning_rate = 0.0001 # 学习率
iteration_num = 5 # 迭代次数
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 优化器
loss = tf.losses.CategoricalCrossentropy(from_logits=True) # 损失
# VGG13模型
VGG_13 = tf.keras.Sequential([
# unit 1
tf.keras.layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
tf.keras.layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
tf.keras.layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
tf.keras.layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
tf.keras.layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# 平铺
tf.keras.layers.Flatten(),
# 全连接
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(100)
])
# 调试输出summary
VGG_13.build(input_shape=[None, 32, 32, 3])
print(VGG_13.summary())
# 组合
VGG_13.compile(
optimizer=optimizer,
loss=loss,
metrics=["accuracy"]
)
def pre_process(x, y):
"""
数据预处理
:param x: 特征值
:param y: 目标值
:return: 返回处理好的x, y
"""
x = tf.cast(x, tf.float32) / 255
y = tf.one_hot(y, depth=100)
return x, y
def get_data():
"""
获取数据
:return: 返回分批完的训练集和测试集
"""
# 读取数据
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar100.load_data()
# 压缩目标值
y_train = tf.squeeze(y_train, axis=1) # (50000, 1) => (50000,)
y_test = tf.squeeze(y_test, axis=1) # (10000, 1) => (10000,)
# 分割训练集
train_db = tf.data.Dataset.from_tensor_slices((X_train, y_train))
train_db = train_db.shuffle(10000).map(pre_process).batch(batch_size)
# 分割测试集
test_db = tf.data.Dataset.from_tensor_slices((X_test, y_test))
test_db = test_db.map(pre_process).batch(batch_size)
return train_db, test_db
if __name__ == "__main__":
# 获取分割的数据集
train_db, test_db = get_data()
# 拟合
VGG_13.fit(train_db, epochs=iteration_num, validation_data=test_db, validation_freq=1)
输出结果:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 256) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
conv2d_7 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 2, 2, 512) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
conv2d_9 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 1, 1, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 512) 0
_________________________________________________________________
dense (Dense) (None, 256) 131328
_________________________________________________________________
dense_1 (Dense) (None, 128) 32896
_________________________________________________________________
dense_2 (Dense) (None, 100) 12900
=================================================================
Total params: 9,582,116
Trainable params: 9,582,116
Non-trainable params: 0
_________________________________________________________________
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_40 (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv2d_41 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
max_pooling2d_20 (MaxPooling (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_42 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
conv2d_43 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
max_pooling2d_21 (MaxPooling (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_44 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv2d_45 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
max_pooling2d_22 (MaxPooling (None, 4, 4, 256) 0
_________________________________________________________________
conv2d_46 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
conv2d_47 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
max_pooling2d_23 (MaxPooling (None, 2, 2, 512) 0
_________________________________________________________________
conv2d_48 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
conv2d_49 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
max_pooling2d_24 (MaxPooling (None, 1, 1, 512) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 512) 0
_________________________________________________________________
dense_12 (Dense) (None, 256) 131328
_________________________________________________________________
dense_13 (Dense) (None, 128) 32896
_________________________________________________________________
dense_14 (Dense) (None, 100) 12900
=================================================================
Total params: 9,582,116
Trainable params: 9,582,116
Non-trainable params: 0
_________________________________________________________________
None
Epoch 1/100
49/49 [==============================] - 13s 259ms/step - loss: 4.5648 - accuracy: 0.0156 - val_loss: 4.4793 - val_accuracy: 0.0273
Epoch 2/100
49/49 [==============================] - 13s 262ms/step - loss: 4.3417 - accuracy: 0.0350 - val_loss: 4.2377 - val_accuracy: 0.0429
Epoch 3/100
49/49 [==============================] - 13s 267ms/step - loss: 4.1708 - accuracy: 0.0524 - val_loss: 4.1086 - val_accuracy: 0.0644
Epoch 4/100
49/49 [==============================] - 13s 258ms/step - loss: 4.0492 - accuracy: 0.0756 - val_loss: 4.0110 - val_accuracy: 0.0819
Epoch 5/100
49/49 [==============================] - 13s 259ms/step - loss: 3.9544 - accuracy: 0.0937 - val_loss: 3.9223 - val_accuracy: 0.1033
Epoch 6/100
49/49 [==============================] - 13s 263ms/step - loss: 3.8669 - accuracy: 0.1083 - val_loss: 3.8429 - val_accuracy: 0.1153
Epoch 7/100
49/49 [==============================] - 13s 264ms/step - loss: 3.7608 - accuracy: 0.1300 - val_loss: 3.7159 - val_accuracy: 0.1382
Epoch 8/100
49/49 [==============================] - 13s 264ms/step - loss: 3.6600 - accuracy: 0.1489 - val_loss: 3.6569 - val_accuracy: 0.1543
Epoch 9/100
49/49 [==============================] - 13s 262ms/step - loss: 3.5859 - accuracy: 0.1601 - val_loss: 3.5673 - val_accuracy: 0.1631
Epoch 10/100
49/49 [==============================] - 13s 258ms/step - loss: 3.4833 - accuracy: 0.1790 - val_loss: 3.4776 - val_accuracy: 0.1788
Epoch 11/100
49/49 [==============================] - 13s 261ms/step - loss: 3.4113 - accuracy: 0.1901 - val_loss: 3.4237 - val_accuracy: 0.1892
Epoch 12/100
49/49 [==============================] - 13s 268ms/step - loss: 3.3414 - accuracy: 0.2026 - val_loss: 3.3747 - val_accuracy: 0.1944
Epoch 13/100
49/49 [==============================] - 13s 260ms/step - loss: 3.2745 - accuracy: 0.2135 - val_loss: 3.3375 - val_accuracy: 0.2047
Epoch 14/100
49/49 [==============================] - 13s 262ms/step - loss: 3.1998 - accuracy: 0.2260 - val_loss: 3.2875 - val_accuracy: 0.2166
Epoch 15/100
49/49 [==============================] - 13s 259ms/step - loss: 3.1391 - accuracy: 0.2390 - val_loss: 3.2630 - val_accuracy: 0.2232
Epoch 16/100
49/49 [==============================] - 13s 264ms/step - loss: 3.0849 - accuracy: 0.2464 - val_loss: 3.2120 - val_accuracy: 0.2321
Epoch 17/100
49/49 [==============================] - 13s 262ms/step - loss: 3.0213 - accuracy: 0.2593 - val_loss: 3.1813 - val_accuracy: 0.2383
Epoch 18/100
49/49 [==============================] - 13s 263ms/step - loss: 2.9375 - accuracy: 0.2769 - val_loss: 3.1334 - val_accuracy: 0.2462
Epoch 19/100
49/49 [==============================] - 13s 262ms/step - loss: 2.8675 - accuracy: 0.2898 - val_loss: 3.1537 - val_accuracy: 0.2434
Epoch 20/100
49/49 [==============================] - 13s 262ms/step - loss: 2.8046 - accuracy: 0.3033 - val_loss: 3.1310 - val_accuracy: 0.2581
Epoch 21/100
49/49 [==============================] - 13s 262ms/step - loss: 2.7407 - accuracy: 0.3169 - val_loss: 3.0795 - val_accuracy: 0.2618
Epoch 22/100
49/49 [==============================] - 13s 262ms/step - loss: 2.6700 - accuracy: 0.3294 - val_loss: 3.0941 - val_accuracy: 0.2573
Epoch 23/100
49/49 [==============================] - 13s 263ms/step - loss: 2.5897 - accuracy: 0.3472 - val_loss: 3.0497 - val_accuracy: 0.2712
Epoch 24/100
49/49 [==============================] - 13s 263ms/step - loss: 2.5231 - accuracy: 0.3621 - val_loss: 3.0578 - val_accuracy: 0.2677
Epoch 25/100
49/49 [==============================] - 13s 265ms/step - loss: 2.4096 - accuracy: 0.3872 - val_loss: 3.0662 - val_accuracy: 0.2773
Epoch 26/100
49/49 [==============================] - 13s 263ms/step - loss: 2.3433 - accuracy: 0.3992 - val_loss: 3.0665 - val_accuracy: 0.2836
Epoch 27/100
49/49 [==============================] - 13s 261ms/step - loss: 2.2442 - accuracy: 0.4200 - val_loss: 3.0822 - val_accuracy: 0.2854
Epoch 28/100
49/49 [==============================] - 13s 259ms/step - loss: 2.1567 - accuracy: 0.4406 - val_loss: 3.1595 - val_accuracy: 0.2780
Epoch 29/100
49/49 [==============================] - 13s 260ms/step - loss: 2.0649 - accuracy: 0.4603 - val_loss: 3.1404 - val_accuracy: 0.2873
Epoch 30/100
49/49 [==============================] - 13s 259ms/step - loss: 1.9495 - accuracy: 0.4903 - val_loss: 3.2024 - val_accuracy: 0.2835
以上是关于TensorFlow2 100 行代码实现 VGG13的主要内容,如果未能解决你的问题,请参考以下文章