TensorFlow2 千层神经网络, 始步于此 --ResNet 实现
Posted 我是小白呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow2 千层神经网络, 始步于此 --ResNet 实现相关的知识,希望对你有一定的参考价值。
概述
深度残差网络 ResNet (Deep residual network) 和 Alexnet 一样是深度学习的一个里程碑.
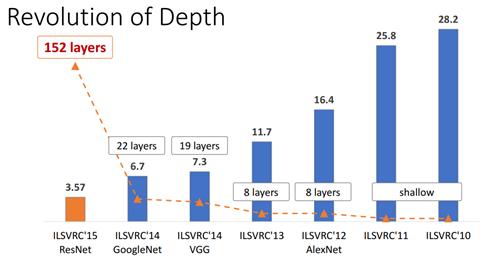
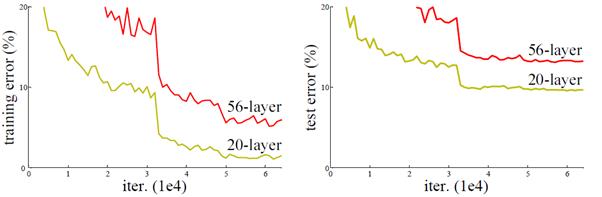
深度网络退化
当网络深度从 0 增加到 20 的时候, 结果会随着网络的深度而变好. 但当网络超过 20 层的时候, 结果会随着网络深度的增加而下降. 网络的层数越深, 梯度之间的相关性会越来越差, 模型也更难优化.
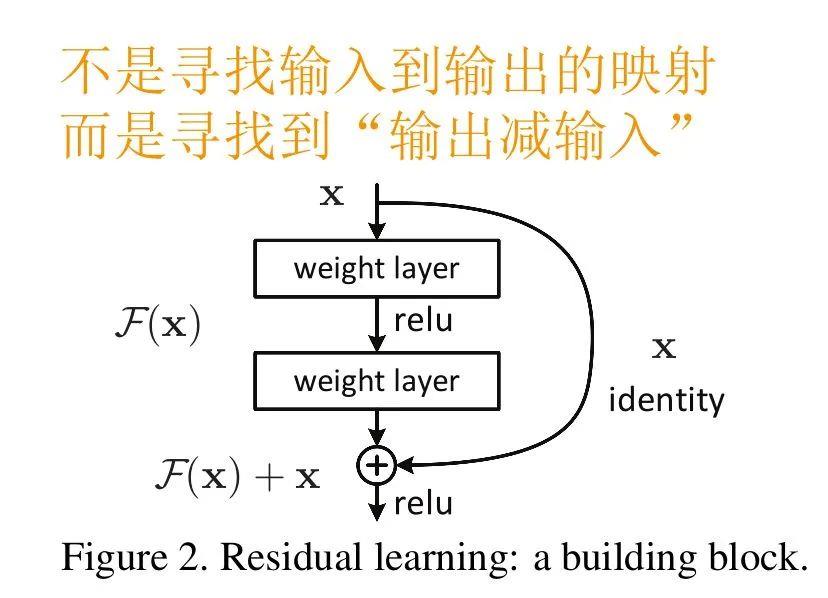
残差网络 (ResNet) 通过增加映射 (Identity) 来解决网络退化问题. H(x) = F(x) + x通过集合残差而不是恒等隐射, 保证了网络不会退化.
代码实现
残差块
class BasicBlock(tf.keras.layers.Layer):
"""
定义残差块
"""
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(filter_num, kernel_size=(3, 3), strides=stride, padding="same")
self.bn1 = tf.keras.layers.BatchNormalization() # 标准化
self.relu = tf.keras.layers.Activation("relu")
self.conv2 = tf.keras.layers.Conv2D(filter_num, kernel_size=(3, 3), strides=1, padding="same")
self.bn2 = tf.keras.layers.BatchNormalization() # 标准化
# 如果步长不为1, 用1*1的卷积实现下采样
if stride != 1:
self.downsample = tf.keras.Sequential(tf.keras.layers.Conv2D(filter_num, kernel_size=(1, 1), strides=stride))
else:
self.downsample = lambda x: x # 返回x
def call(self, inputs, training=None):
# unit1
out = self.conv1(inputs)
out = self.bn1(out, training=training)
out = self.relu(out)
# unit2
out = self.conv2(out)
out = self.bn2(out, training=training)
identity = self.downsample(inputs) # 降采样
output = tf.keras.layers.add([out, identity]) # 相加
output = tf.nn.relu(output)
return output
超参数
# 定义超参数
batch_size = 1024 # 一次训练的样本数目
learning_rate = 0.0001 # 学习率
iteration_num = 5 # 迭代次数
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 优化器
loss = tf.losses.CategoricalCrossentropy(from_logits=True) # 损失
ResNet 18 网络
ResNet_18 = tf.keras.Sequential([
# 初始层
tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1)), # 卷积
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation("relu"),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding="same"), # 池化
# 8个block(每个为两层)
BasicBlock(filter_num=64, stride=1),
BasicBlock(filter_num=64, stride=1),
BasicBlock(filter_num=128, stride=2),
BasicBlock(filter_num=128, stride=1),
BasicBlock(filter_num=256, stride=2),
BasicBlock(filter_num=256, stride=1),
BasicBlock(filter_num=512, stride=2),
BasicBlock(filter_num=512, stride=1),
tf.keras.layers.GlobalAveragePooling2D(), #池化
# 全连接层
tf.keras.layers.Dense(100) # 100类
])
# 调试输出summary
ResNet_18.build(input_shape=[None, 32, 32, 3])
print(ResNet_18.summary())
获取数据
def pre_process(x, y):
"""数据预处理"""
x = tf.cast(x, tf.float32) * 2 / 255 - 1 # 范围-1~1
y = tf.one_hot(y, depth=100)
return x, y
def get_data():
"""获取数据"""
# 读取数据
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar100.load_data()
y_train, y_test = tf.squeeze(y_train, axis=1), tf.squeeze(y_test, axis=1) # 压缩目标值
# 分割数据集
train_db = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(10000).map(pre_process).batch(batch_size)
test_db = tf.data.Dataset.from_tensor_slices((X_test, y_test)).map(pre_process).batch(batch_size)
return train_db, test_db
完整代码
来, 让我们干了这杯酒, 来看完整代码.

完整代码:
import tensorflow as tf
class BasicBlock(tf.keras.layers.Layer):
"""
定义残差块
"""
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(filter_num, kernel_size=(3, 3), strides=stride, padding="same")
self.bn1 = tf.keras.layers.BatchNormalization() # 标准化
self.relu = tf.keras.layers.Activation("relu")
self.conv2 = tf.keras.layers.Conv2D(filter_num, kernel_size=(3, 3), strides=1, padding="same")
self.bn2 = tf.keras.layers.BatchNormalization() # 标准化
# 如果步长不为1, 用1*1的卷积实现下采样
if stride != 1:
self.downsample = tf.keras.Sequential(
tf.keras.layers.Conv2D(filter_num, kernel_size=(1, 1), strides=stride))
else:
self.downsample = lambda x: x # 返回x
def call(self, inputs, training=None):
# unit1
out = self.conv1(inputs)
out = self.bn1(out, training=training)
out = self.relu(out)
# unit2
out = self.conv2(out)
out = self.bn2(out, training=training)
identity = self.downsample(inputs) # 降采样
output = tf.keras.layers.add([out, identity]) # 相加
output = tf.nn.relu(output)
return output
# 定义超参数
batch_size = 1024 # 一次训练的样本数目
learning_rate = 0.0001 # 学习率
iteration_num = 5 # 迭代次数
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 优化器
loss = tf.losses.CategoricalCrossentropy(from_logits=True) # 损失
ResNet_18 = tf.keras.Sequential([
# 初始层
tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1)), # 卷积
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation("relu"),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding="same"), # 池化
# 8个block(每个为两层)
BasicBlock(filter_num=64, stride=1),
BasicBlock(filter_num=64, stride=1),
BasicBlock(filter_num=128, stride=2),
BasicBlock(filter_num=128, stride=1),
BasicBlock(filter_num=256, stride=2),
BasicBlock(filter_num=256, stride=1),
BasicBlock(filter_num=512, stride=2),
BasicBlock(filter_num=512, stride=1),
tf.keras.layers.GlobalAveragePooling2D(), # 池化
# 全连接层
tf.keras.layers.Dense(100) # 100类
])
# 调试输出summary
ResNet_18.build(input_shape=[None, 32, 32, 3])
print(ResNet_18.summary())
# 组合
ResNet_18.compile(optimizer=optimizer, loss=loss, metrics=["accuracy"])
def pre_process(x, y):
"""数据预处理"""
x = tf.cast(x, tf.float32) * 2 / 255 - 1 # 范围-1~1
y = tf.one_hot(y, depth=100)
return x, y
def get_data():
"""获取数据"""
# 读取数据
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar100.load_data()
y_train, y_test = tf.squeeze(y_train, axis=1), tf.squeeze(y_test, axis=1) # 压缩目标值
# 分割数据集
train_db = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(10000).map(pre_process).batch(batch_size)
test_db = tf.data.Dataset.from_tensor_slices((X_test, y_test)).map(pre_process).batch(batch_size)
return train_db, test_db
if __name__ == "__main__":
# 获取分割的数据集
train_db, test_db = get_data()
# 拟合
ResNet_18.fit(train_db, epochs=iteration_num, validation_data=test_db, validation_freq=1)
输出结果:
Model: "sequential_16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_70 (Conv2D) (None, 30, 30, 64) 1792
_________________________________________________________________
batch_normalization_17 (Batc (None, 30, 30, 64) 256
_________________________________________________________________
activation_9 (Activation) (None, 30, 30, 64) 0
_________________________________________________________________
max_pooling2d_26 (MaxPooling (None, 30, 30, 64) 0
_________________________________________________________________
basic_block_8 (BasicBlock) (None, 30, 30, 64) 74368
_________________________________________________________________
basic_block_9 (BasicBlock) (None, 30, 30, 64) 74368
_________________________________________________________________
basic_block_10 (BasicBlock) (None, 15, 15, 128) 230784
_________________________________________________________________
basic_block_11 (BasicBlock) (None, 15, 15, 128) 296192
_________________________________________________________________
basic_block_12 (BasicBlock) (None, 8, 8, 256) 920320
_________________________________________________________________
basic_block_13 (BasicBlock) (None, 8, 8, 256) 1182208
_________________________________________________________________
basic_block_14 (BasicBlock) (None, 4, 4, 512) 3675648
_________________________________________________________________
basic_block_15 (BasicBlock) (None, 4, 4, 512) 4723712
_________________________________________________________________
global_average_pooling2d_1 ( (None, 512) 0
_________________________________________________________________
dense_16 (Dense) (None, 100) 51300
=================================================================
Total params: 11,230,948
Trainable params: 11,223,140
Non-trainable params: 7,808
_________________________________________________________________
None
Epoch 1/20
49/49 [==============================] - 43s 848ms/step - loss: 3.9558 - accuracy: 0.1203 - val_loss: 4.6631 - val_accuracy: 0.0100
Epoch 2/20
49/49 [==============================] - 41s 834ms/step - loss: 3.0988 - accuracy: 0.2525 - val_loss: 4.9431 - val_accuracy: 0.0112
Epoch 3/20
49/49 [==============================] - 41s 828ms/step - loss: 2.5981 - accuracy: 0.3518 - val_loss: 5.2123 - val_accuracy: 0.0150
Epoch 4/20
49/49 [==============================] - 40s 824ms/step - loss: 2.1962 - accuracy: 0.4464 - val_loss: 5.4619 - val_accuracy: 0.0230
Epoch 5/20
49/49 [==============================] - 41s 828ms/step - loss: 1.8086 - accuracy: 0.5450 - val_loss: 5.4788 - val_accuracy: 0.0313
Epoch 6/20
49/49 [==============================] - 41s 827ms/step - loss: 1.4073 - accuracy: 0.6611 - val_loss: 5.6753 - val_accuracy: 0.0386
Epoch 7/20
49/49 [==============================] - 41s 827ms/step - loss: 1.0093 - accuracy: 0.7791 - val_loss: 5.3822 - val_accuracy: 0.0671
Epoch 8/20
49/49 [==============================] - 41s 829ms/step - loss: 0.6361 - accuracy: 0.8905 - val_loss: 5.0999 - val_accuracy: 0.0961
Epoch 9/20
49/49 [==============================] - 41s 829ms/step - loss: 0.3532 - accuracy: 0.9587 - val_loss: 4.7099 - val_accuracy: 0.1366
Epoch 10/20
49/49 [==============================] - 41s 828ms/step - loss: 0.1799 - accuracy: 0.9874 - val_loss: 4.1926 - val_accuracy: 0.1899
Epoch 11/20
49/49 [==============================] - 41s 828ms/step - loss: 0.0964 - accuracy: 0.9965 - val_loss: 3.6718 - val_accuracy: 0.2504
Epoch 12/20
49/49 [==============================] - 41s 827ms/step - loss: 0.0580 - accuracy: 0.9986 - val_loss: 3.3465 - val_accuracy: 0.2876
Epoch 13/20
49/49 [==============================] - 41s 828ms/step - loss: 0.0390 - accuracy: 0.9995 - val_loss: 3.1585 - val_accuracy: 0.3219
Epoch 14/20
49/49 [==============================] - 41s 828ms/step - loss: 0.0286 - accuracy: 0.9996 - val_loss: 3.1677 - val_accuracy: 0.3271
Epoch 15/20
49/49 [==============================] - 41s 830ms/step - loss: 0.0231 - accuracy: 0.9996 - val_loss: 3.1084 - val_accuracy: 0.3384
Epoch 16/20
49/49 [==============================] - 41s 829ms/step - loss: 0.0193 - accuracy: 0.9997 - val_loss: 3.1312 - val_accuracy: 0.3452
Epoch 17/20
49/49 [==============================] - 41s 829ms/step - loss: 0.0165 - accuracy: 0.9997 - val_loss: 3.1519 - val_accuracy: 0.3413
Epoch 18/20
49/49 [==============================] - 41s 828ms/step - loss: 0.0140 - accuracy: 0.9997 - val_loss: 3.1658 - val_accuracy: 0.3435
Epoch 19/20
49/49 [==============================] - 41s 827ms/step - loss: 0.0123 - accuracy: 0.9997 - val_loss: 3.1867 - val_accuracy: 0.3433
Epoch 20/20
49/49 [==============================] - 41s 828ms/step - loss: 0.0111 - accuracy: 0.9997 - val_loss: 3.2123 - val_accuracy: 0.3447
注: 我们可以看出 ResNet18 比 VGG13 的准确率高了一大截.

祝全天下的父亲节日快乐!
以上是关于TensorFlow2 千层神经网络, 始步于此 --ResNet 实现的主要内容,如果未能解决你的问题,请参考以下文章