那些年我们忽略未学会的MYSQL知识
Posted 绘空事J
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了那些年我们忽略未学会的MYSQL知识相关的知识,希望对你有一定的参考价值。
欢迎来到【绘空事J】学习屋~
那么~面码藏好了吗?
快来听我讲讲那些年我们仍然未学会的mysql知识!
基础的CRUD相信各位同学已经再熟练不过了~
数据库的事务ACID特性、隔离级别应该已经倒背如流了吧
那么今天我来分享一下一些开发平时很少关注的MYSQL知识点。
1.MYSQL服务器逻辑架构图
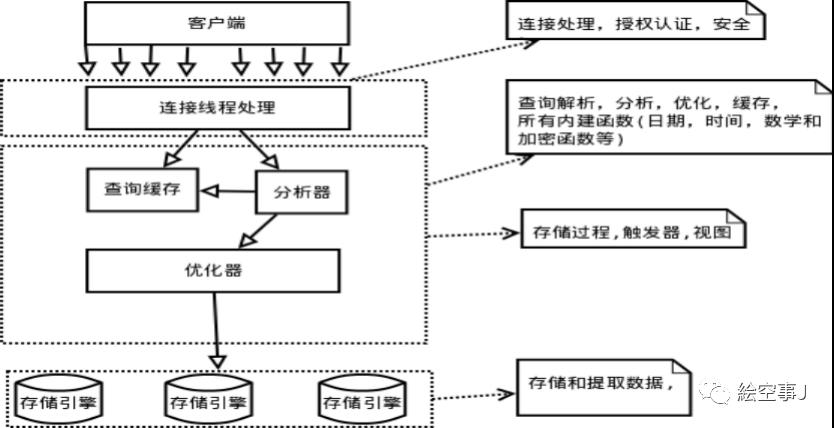
(MYSQL三层架构)
第一层:最上层的服务器不是MYSQL所独有的,大多数基于网络的客户端/服务器工具或者服务都有类似的系统。比如链接处理,授权认证,安全等等。
第二层:大多数的MYSQL的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如:日期,时间,数学和加密函数等)。所有跨存储引擎的功能都在这一层实现:存储过程,触发器,视图。
1.客户端发送一条查询给服务器
2.服务器先检查缓存,如果命中缓存,则立即返回(可以设置缓存开关,更新/命中1:3可开)
3.服务器端进行SQL解析、预处理、再由优化器生成对应执行计划(包括重写查询,决定表的读取顺序,以及选择合适的索引等)。
4.MYSQL根据优化器生成执行计划,调用存储引擎对应执行计划。
5.返回给客户
第三层:包含了存储引擎。存储引擎负责MYSQL中的数据存储和提取。服务器通过API和存储引擎进行通信,这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎API包含了几十个底层函数,用于执行诸如”开始一个事务“或者”根据主键提取一行记录“等操作。但存储引擎不会去解析SQL(INNODB是一个例外,它会解析外键定义,因为MYSQL服务器本身没有实现该功能)
2.多版本并发控制MVCC 与 MYSQL事务
INNODB采用MVCC来支持高并发,并实现了4个标准的隔离级别,并通过间隙锁策略防止幻读。间隙锁不仅仅锁定查询涉及的行,还对索引间隙进行锁定,防止幻读。
实现策略:
通过增加【创建版本号】create_no、【过期版本号】expired_no
版本号为自增序列,每次增删改都会自增1。
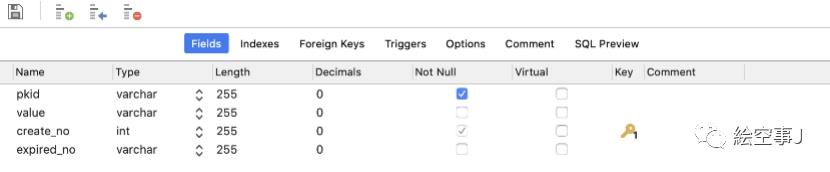

(简单表设计方案)
SELECT:根据2个条件选取某个版本号(x=7)中存活的数据。
(1)创建时间小于等于当前版本号(x)
(2)过期时间为空或者大于当前版本号(x)
select * from MVCC t where t.create_no<=7 and (t.expired_no is null or t.expired_no>7);
INSERT:为新插入的每一行的【创建版本号】保存当前系统的版本号.
DELETE:为删除的每一行的【过期版本号】更新当前系统版本号。
UPDATE:更新数据
(1)插入一条新的数据,为【创建版本号】设置版本号。
(2)更新上一条【过期版本号】为空的数据,设置过期版本号。
3.范式与反范式
第一范式1NF:
所有域都是原子性的,即数据库每一列都是不可分割原子性的。即1NF就是无重复的域。
示范案例:
员工主键 |
性别 |
男性 |
女性 |
第二范式2NF:
在1NF的基础上,要求实体属性完全依赖于关键字。
即col完全依赖于主键,有一个唯一标识,如果仅仅只是部分依赖,则应该分离出新的实体。
例如,在用证件号关联用户身份信息时,应该用证件号而不应该用姓名。
正确示范:
证件号(主键) |
姓名 |
年龄 |
性别 |
籍贯 |
错误示范:
姓名(主键) |
证件号 |
年龄 |
性别 |
籍贯 |
第三范式3NF:
在2NF的基础上,任何非主属性不依赖于其他非主属性。
例如,存在一个部门信息表,其中每个部门有部门编号、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。
示范案例:
员工主键 |
员工年龄 |
员工性别 |
主部id |
主部门 |
次部门 |
巴斯-科德范式BCNF:
在3NF的基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集依赖)
例如,场景一个仓库可以有多个管理员,多个存储物品,每个存储物品有对应数量。
错误示范:消除子列对主键的依赖
仓库号1 |
管理员A |
货物A |
10 |
仓库号1 |
管理员A |
货物B |
5 |
仓库号2 |
管理员B |
货物C |
10 |
正确示范:
仓库号1 |
管理员A |
仓库号2 |
管理员B |
仓库号1 |
货物A |
10 |
仓库号1 |
货物B |
5 |
仓库号2 |
货物C |
10 |
第四范式4NF:
在3NF,BCNF基础下非主属性的,候选键只能存在不超过1个多值属性。要求把同一表内的多对多关系删除。
仓库号 |
管理员id |
管理员名称 |
货物id |
货物名称 |
范式优点:
1.范式的更新操作通常比反范式快
2.有较少的重复数据,更新操作的效率更高
3.表内存占空间更小
4.较少的使用distinct和groupby
反范式优点:
1.数据都在同一张表中,可以避免关联,查询更效率
混用范式设计:
1.最常用的反范式化的schema是复制或者缓存,利用触发器同步更新其他表字段
4.MYSQL分区、分表
分区、分表、分库区别:
分区、分表、分库都可以大幅提升数据库读的性能。
数据库分库可以提升并发写的速度:通过简单暴力的物理方式拆分功能
分区最简单,由数据库自身维护数据关系;分表复杂,需要开发人员指定数据读写在哪张子表;分库最复杂,除了为对应的数据选择对应的数据库以外,还需要解决跨库的分布式事务问题
分区、分表、分库并不冲突,比如在 读写分离的业务场景,对读的数据库的某些表进行分区或者分表。或者对于一些容易编程的表用分表,编程复杂的业务用分区,都是可行的
分区详解:
对用户来说,分区表就是一个独一的逻辑表,但是底层由多个物理字表组成。实现分区的代码实际上是对一组底层表的句柄对象的封装。对分区表的请求,都会通过句柄对象转化成对存储引擎的接口。所以分区对SQL层面是一个完全封装的黑盒。
在数据量超大的时候,B-Tree索引就无法起作用了,除非是覆盖索引,否则数据库服务器需要根据索引扫描的结果回表,查询所有符合条件的记录,如果数据量巨大,这将产生大量随机I/O。
为了保证大数据量可扩展性,一般使用分区有下面两个策略:
全量扫描数据,不要任何索引。
可以使用简单的分区方式存放表,不要任何索引,根据分区的规则大致定位到数据位置。
这个策略使用于以正常的方式访问大量数据的时候。
索引数据,并分离热点
如果数据有明显的‘热点’,而且除了这部分数据,其他数据很少被访问到,那么可以将这部分热点数据单独放在一个分区中,构建索引也能有效缓存。
Create table sales(
Order_date DATETIME not null,
---other columns omitted
)engine=INNODB partition by range(year(order_date))(
Partition p_2019 values less than (2019),
Partition p_2020 values less than (2020),
Partition p_2021 values less than (2021),
Partition p_catchall values less than MAXVALUE);
分表详解:
分表更复杂,但是性能稍微好一点点。但是如果Mysql可以高效的维护各个分区之间的关系的话,其实分表是没有必要的。错误的分表操作,会带来bug
分表的性能更好,不需要查询优化器来选择读取哪张表,但是分表编码更复杂,要通过代码指定数据存储到特定的表
5.高可用MYSQL
刚刚上一节提到了分库的概念,本来打算在上一节一带而过,但发现分库涉及的概念范围特别的广,其中必不可少的会遇到分布式CAP原则,BASE原则,还有数据库的复制、可扩展性和高可用性。
CAP原则:
CAP原则的精髓就是当发生分区异常时,一致性和可用性不能同时实现。
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值,即写操作之后的读操作,必须返回该值。(分为弱一致性、强一致性和最终一致性)
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
BASE原则:
在CAP原则中,在保证可用性和分区容忍性的条件下,既然无法同时实现强一致性,但可以根据每个业务的特点,采用适当的方式实现最终一致性。
基本可用性(BA):在分布式系统中出现不可预知的故障时,允许损失部分可用性
比如:1.响应时间的损失
2.功能降级
软状态(S):允许系统在不同结点的数据副本之间进行同步的过程存在延迟。
比如:跨系统的T+0定时推送
最终一致性(E):系统保证最终数据能够达成一致,而不需要系统保证数据的强一致。
比如:财报系统的T+1数据推送
数据库复制:
复制三个步骤:
1.在主库上把数据更改记录到二进制日志中(Binary log)
2.备库将主库上的日志复制到自己的中继日志
3.备库读取中继日志中的时间,将其重放到备库数据之上
数据库可扩展性:
线性扩展,阿姆达尔扩展Amdahl,USL扩展
扩展方式:
1.增加硬件配置
2.复制,拆分,数据分片
a) 复制:主主复制结构,一主多备结构...
b) 按功能拆分库,用接口对接。如:论坛,新闻,知识库
c) 数据分片:分区,分表
负债均衡:
1.复制上的读写分离
2.修改应用配置文件
3.修改DNS名
6.MYSQL中的Explain
概要描述:
id:选择标识符select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
总结起来发现,下面链接的博主已经总结的很到位,无需我多解释~
具体内容参考:https://www.cnblogs.com/tufujie/p/9413852.html / 高性能MYSQL附录D
参考文献:
1.https://www.cnblogs.com/wzj4858/p/7910340.html 逻辑架构图
2.https://www.jianshu.com/p/71563d6b121d 数据库四大范式
3.https://blog.csdn.net/lixinkuan328/article/details/95535691
CAP原则详解
4.《高性能MYSQL》
5.https://www.cnblogs.com/tufujie/p/9413852.html Explain详解
以上是关于那些年我们忽略未学会的MYSQL知识的主要内容,如果未能解决你的问题,请参考以下文章