一文带你了解Java8之Stream
Posted 风在哪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文带你了解Java8之Stream相关的知识,希望对你有一定的参考价值。
Java8 Stream流式编程
简介
Java8中stream是用于对集合迭代器的增强,使之能供完成更高效的聚合操作(例如过滤、排序、统计分组等)或者大批量数据操作。此外,stream与lambda表达式结合后编码效率将会大大提高,并且可以提高可读性。
首先来看一个简单的场景,准备工作如下,编写了一个person类:
public class Person {
/**
* 姓
*/
private String lastname;
/**
* 名
*/
private String name;
private Integer age;
private String sex;
private String address;
// 省略了构造函数、getter和setter方法以及toString()方法,读者可使用idea生成
}
接下来看看我们的一些需求:
- 假如我们要寻找以"王"为姓的人,那么我们该如何做呢?传统方法就是for循环遍历判断,然后加入结果集,但是这里如果用到stream的话,可以一行代码搞定(详细代码稍后列出)
- 假如我们要根据性别统计用户的平均年龄,那么我们该如何做呢?传统方法:首先就是根据不同的性别进行分组,然乎对两个分组求平均值,stream也可以一行代码搞定。
说的这么神奇,来看看具体的代码吧:
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
LearnStream learnStream = new LearnStream();
List<Person> ps = learnStream.searchLastname("王");
ps.forEach(person -> System.out.println(person.toString()));
List<Person> personList = learnStream.searchByParams(person -> person.getLastname().equals("王") && person.getAge() > 22);
personList.forEach(p -> System.out.println(p.toString()));
Map<String, Double> average = learnStream.average();
average.forEach((k, v) -> System.out.println(k + ":" + v));
}
/**
* 查找以lastname为姓的人
* @param lastname
*/
public List<Person> searchLastname(String lastname) {
List<Person> results = persons.stream()
.filter(person -> person.getLastname().equals(lastname))
.collect(Collectors.toList());
return results;
}
/**
* 自定义lambda表达式参数
* @param predicate
* @return
*/
public List<Person> searchByParams(Predicate<? super Person> predicate) {
List<Person> collect = persons.stream().filter(predicate).collect(Collectors.toList());
return collect;
}
/**
* 统计男性或女性的平均年龄
* @return
*/
public Map<String, Double> average() {
// groupingBy按照某个属性分组
Map<String, List<Person>> collect = persons.stream().collect(Collectors.groupingBy(person -> person.getSex()));
// 先分组,然后在分组内按照某个属性计算其平均值
Map<String, Double> res = persons.stream()
.collect(Collectors.groupingBy(person -> person.getSex(), // 基于性别分组
Collectors.averagingDouble(persons -> persons.getAge()))); // 基于年龄求分组平均值
return res;
}
}
代码的运行结果如下:

通过上面的案例是不是可以发现,stream的代码其实很简单,一行搞定我们的需求,比传统的方法要高效很多。
stream出现背景
像这种遍历的方式,我们有没有更简单的实现方法呢?答案肯定是有的,通常情况下,我们的数据是存储在数据库中,当我们使用SQL语句查询数据的时候直接做好处理比在Java程序中写这些代码要简单的多。上面的需求可以通过如下SQL语句实现:
# 获取所有姓王的用户
select * from person where lastname='王';
# 根据性别统计平均年龄
select p.sex, average(p.age) from person as p group by sex;
通过一个sql语句就能实现我们上面Java代码中的功能,而且简单易懂,效率也比较高。
在传统的JavaEE项目中数据源单一且集中,像上面的需求我们可以通过SQL语句进行计算。但是现在互联网项目的数据源多样化,包括:关系数据库、NoSQL、Redis、mongodb、ElasticSerach等。此时,我们需要从各种数据源中聚集数据并进行统计,在stream出现之前,使用传统的for循环遍历非常繁琐,stream出现之后,这种局面就改变了。
Stream大大简化了我们的开发,结合lambda表达式更是效率神器。
lambda表达式
lambda表达式也可以称为闭包,它是推动Java8发布的最重要新特性,lambda允许把函数作为一个方法参数传递给方法。
在Java8之前,如果我们新创建一个线程对象,需要使用匿名内部类传递我们要执行的任务,在Java8我们可以使用lambda简化这种操作,例如:
public static void main(String[] args) {
// 匿名内部类
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("使用匿名内部类");
}
}).start();
// lambda表达式
new Thread(() -> System.out.println("使用lambda")).start();
}
从上面的代码中,我们可以看出lambda的简洁,比匿名内部类少写了很多代码(其实它的底层原理还是匿名内部类)。可以看看编译后的字节码(只包含lambda表达式的代码),从中可以发现它底层还是使用了匿名内部类:

函数式接口
上述的这种直接使用lambda是如何实现的呢?我们来看看Runnable的源码:
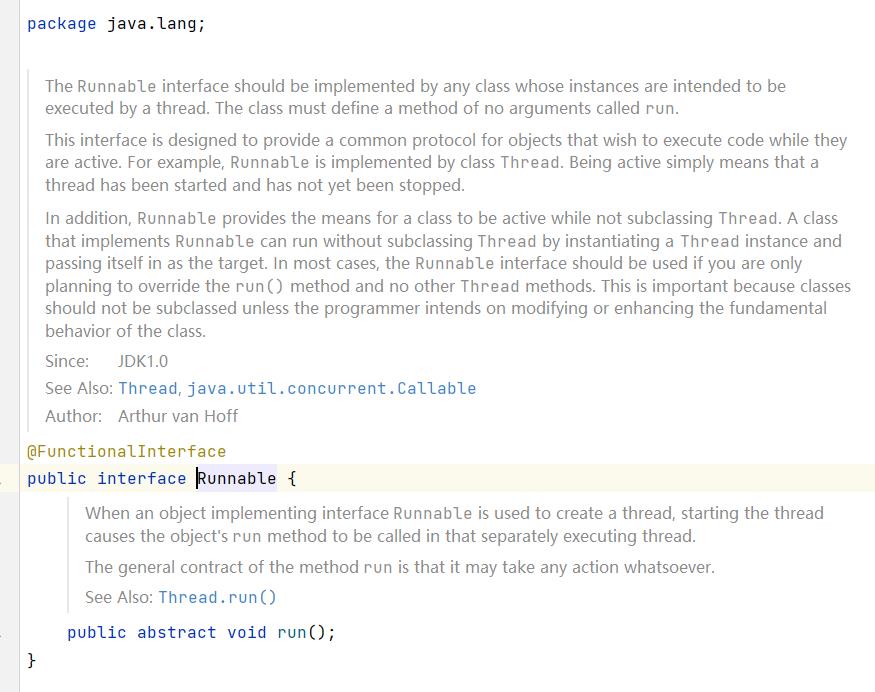
它是一个接口,而且它被注解@FunctionalInterface标注,这证明它是一个函数式接口,通过函数式接口我们可以使用lambda表达式来进行编码。
那么什么是函数式接口呢?它必须满足如下条件:
- 函数式接口只能包含一个方法(想想也对,我们使用lambda表达式不会指定实现哪个方法,所以只能有一个方法,然后lambda表达式就是对这个方法的实现)
- 可以包含多个默认方法(默认方法相当于已经实现的方法,默认方法不会影响lambda表达式对接口方法的实现)
- Object类下的方法不计算在内,例如:toString()、equals()、hashCode()等方法。
满足上述条件的接口就是函数式接口,那么@FunctionalInterface注解的作用是什么呢?
其实只要满足上述条件,没有@FunctionalInterface注解标注也是函数式接口,该注解的作用就是帮我们辨别一个接口是否是函数式接口,如果不是的话,在编译阶段就会报错。
例如:
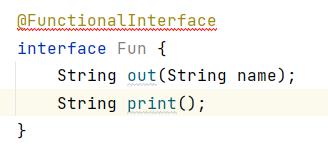
上面这个接口就不是函数式接口,idea会很智能的提示我们编码错误。
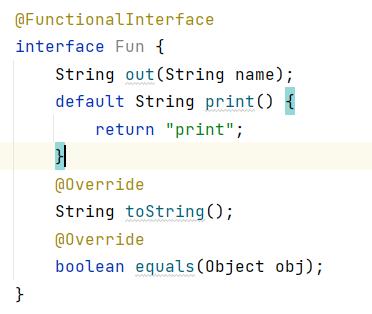
当我们为部分方法提供默认实现,让接口中的方法只有一个时,这个函数式接口就成立了。
函数式接口是lambda表达式的前提,我们需要先编写函数式接口才能继续使用lambda表达式。
编写lambda表达式
在编写lambda之前,我们需要先编写一个函数式接口,如下:
@FunctionalInterface
public interface Function {
/**
* 输出姓名和年龄
* @param name
* @param age
* @return
*/
void print(String name, int age);
}
然后根据函数式接口传递参数,并且使用lambda表达式实现函数式接口:
public class MyLambda {
public static void main(String[] args) {
print((name, age) -> System.out.println(String.format("name: %s, age: %s", name, age)));
}
public static void print(Function function) {
function.print("王大", 23);
}
}
来看看运行结果:

这里的lambda表达式就相当于函数式接口的实现类,我们对函数式接口的方法调用的最终实现就是这个lambda表达式的内容,这里就是将我们传入的姓名和年龄转换为一个固定的格式,然后输出。
当lambda表达式没有参数时,可以直接以print(() -> System.out.println())这种形式书写,以空括号开始即可;如果lambda表达式只有一个参数的话,可以省略括号,例如print(name -> System.out.println(name)),这里的参数可以带类型,也可以不带,看个人习惯;而且使用lambda表达式也可以省略return语句。
lambda表达式的特性:
- 单行表达式,如果有返回值可以省略return,如上面的代码所示
- 代码块
print((name, age) -> {
String format = String.format("name: %s, age: %s", name, age);
System.out.println(format);
});
在多行表达式中,如果有返回值不能省略return
- 方法引用,我们可以将lambda表达式的实现逻辑封装成一个方法,然后直接在lambda表达式函数中调用封装好的方法,称为方法引用,方法引用包括静态方法引用和动态方法引用
public class MyLambda {
public static void main(String[] args) {
// 静态方法引用
print(MyLambda::format);
// 普通方法引用
print(new MyLambda()::f);
}
public static void format(String name, int age) {
System.out.println(String.format("name: %s, age: %s", name, age));
}
public void f(String name, int age) {
System.out.println(String.format("name: %s, age: %s", name, age));
}
public static void print(Function function) {
function.print("王大", 23);
}
}
Stream执行机制
Stream的执行机制就是首先通过数据源生成Stream,然后对这个Stream进行我们需要的操作,例如分组、排序、过滤等,然后采集结果输出最终的数据。
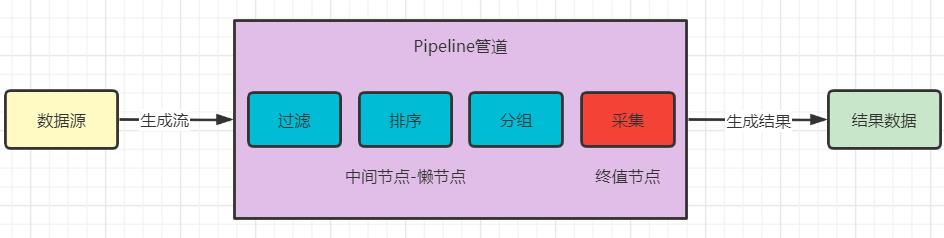
Stream特性
流的特性有哪些呢?
- stream不存储数据
- stream不改变源数据
- stream不可重复使用
首先我们来看看流的产生方式:
persons.stream(); // List<Person> persons = new ArrayList<>();
Arrays.stream(new int[] {1, 2, 3, 4, 5, 6});
Stream.of(1, 2, 3, 4);
接下来可以看看stream是不可重复使用的,当我们使用一次流之后,再重复使用时会报错,例如:
public class StreamFeatures {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
Stream<Person> stream = persons.stream();
Stream<Person> first = stream.filter(person -> person.getLastname().equals("王"));
Stream<Person> second = stream.filter(person -> person.getAge() > 21);
}
}
运行结果如下:

当我们重复使用stream这个流时,就会报IllegalStateException异常,提示我们stream已经被操作过。
为什么stream流不能重复使用呢?因为流是串联起来的,从Stream的执行机制我们可以发现,stream是经过管道操作,刚开始产生的stream会作为输入进行下一次的操作,stream只能顺序执行,不能对同一stream进行不同的操作。所以当我们对stream进行两次不同的操作时会发生异常。
从最初的stream执行机制图中,我们可以发现,stream流在执行的过程中包括中间节点和终值节点;这些不同的节点就代表了不同的操作,对同一stream的所有操作组合在一起就变成了管道,管道中包含如下操作:
- Intermediate(中间操作):调用中间操作方法会产生一个新的stream流,通过连续执行多个操作就组成了Stream中的执行管道,需要注意的是这些管道被添加后并不会真正执行,只有等到调用终值操作后才会执行
- Terminal(终值操作):在调用该方法后会执行之前所有的中间操作,获取返回结果,并结束对流的使用
- Short-circuiting:对于一个 intermediate 操作,如果它接受的是一个无限大(infinite/unbounded)的 Stream,但返回一个有限的新 Stream;对于一个 terminal 操作,如果它接受的是一个无限大的 Stream,但能在有限的时间计算出结果
此外,数据源在stream流中的传递过程是一个一个进行的,就是从第一个数据源开始传递,经过不同的操作,产生不同的结果,例如:
public class StreamFeatures {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
// 上一个节点的操作可以影响下一个节点
persons.stream()
.peek(person -> System.out.println(person.getName())) // peek可以执行一个函数,相当于中间节点
.peek(person -> System.out.println(person.getAge()))
.toArray();
}}
上述代码的执行结果就是名字和年龄交替打印,这就证明了数据源里面的数据是一条条的传递的:
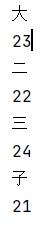
stream流在执行过程中,上一个节点的操作会影响下一个节点,影响方式包括:
- 过滤
- 转换:当我们使用map后,会将person类转变成person类对应的属性或者其他的值等,而且转换后会影响后续操作
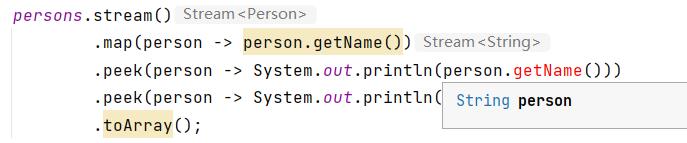
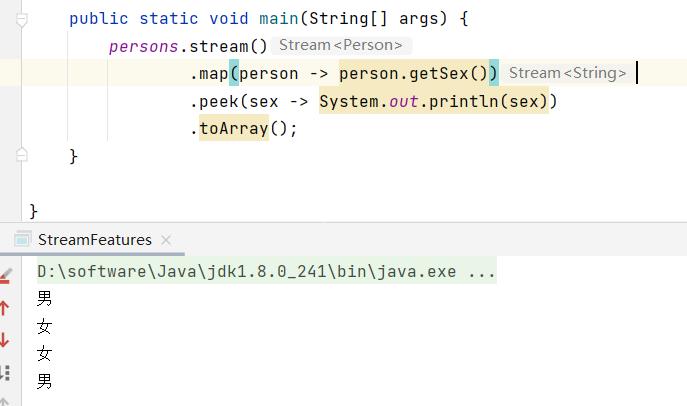
- 去重
首先看看未去重的版本:
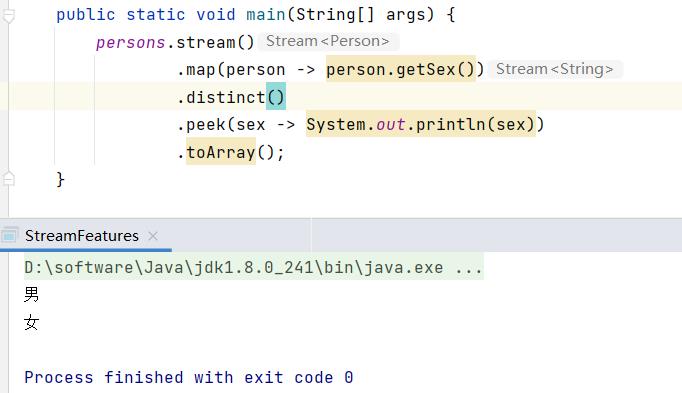
加上distinct函数对stream流进行去重的结果:
我们可以对其进行调试,看看IDEA强大的调试功能:


从上面的调试过程可以看出对Stream流的每一步操作。
Stream实践
常见的流操作的分类如下:
Intermediate
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
Terminal
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Short-circuiting
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
当我们对Stream进行操作时,往往会产生中间结果,这些中间结果就是Optional包装类,所以我们先来了解一下Optional的具体作用。
Optional
Optional通过泛型来包装不同的值,这个值可能为null,也可能不为null,它相当于一个可选值的包装类。
在实际开发中,我们如果使用Optional来包装一个可能的null值的话,可以帮助我们减少大量的if else判断,首先来看看Optional包含哪些方法。
public final class Optional<T> {
// 创造一个包含空值的Optional
private static final Optional<?> EMPTY = new Optional<>();
// Optional包装的值
private final T value;
// 私有构造函数,不对外公开,构造一个包含空值的Optional
private Optional() {
this.value = null;
}
// 暴露给用户使用的静态方法,用于构造一个包含空值的Optional
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
// 私有构造函数,构造一个包含非空值的Optional
private Optional(T value) {
this.value = Objects.requireNonNull(value);
}
// 静态方法,构造一个包含非空值的Optional
public static <T> Optional<T> of(T value) {
return new Optional<>(value);
}
// 静态方法,根据传入的参数是否为空选择创建不同的Optional
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
// 获取Optional包装的值
public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
// 判断Optional包装的值是否为空
public boolean isPresent() {
return value != null;
}