E-MapReduce
Posted 小东子李
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了E-MapReduce相关的知识,希望对你有一定的参考价值。
E-MapReduce
简介
EMR构建于云服务器ECS上,基于开源的Apache Hadoop和Apache Spark,让您可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿里云OSS和RDS等)进行数据传输。
EMR的SmartData组件是EMR Jindo引擎的主要存储部分,为EMR各个计算引擎提供统一的存储优化、缓存优化、计算缓存加速优化和多个存储功能扩展。
E-MapReduce的用途
以往在使用Hadoop和Spark等分布式处理系统时,您通常需要执行如下步骤。
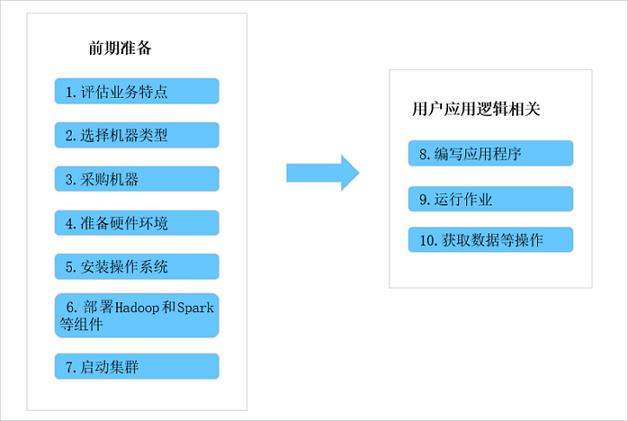
EMR使用流程
在上述使用流程中,真正跟用户的应用逻辑相关的是步骤810,而步骤17都是前期准备工作,但这些前期准备工作都非常冗长繁琐。E-MapReduce提供了集群管理工具的集成解决方案,例如,主机选型、环境部署、集群搭建、集群配置、集群运行、作业配置、作业运行、集群管理和性能监控等。通过E-MapReduce,您可以从繁琐的集群构建相关的采购、准备和运维等工作中解放出来,只关心自己应用程序的处理逻辑即可。
此外,E-MapReduce还为您提供了灵活的搭配组合方式,您可以根据自己的业务特点选择不同的集群服务。例如,如果您的需求是对数据进行日常统计和简单的批量运算,则可以只选择在E-MapReduce中运行Hadoop服务;如果您有流式计算和实时计算的需求,则可以在Hadoop服务基础上再加入Spark服务。
E-MapReduce的组成
E-MapReduce的核心是集群。E-MapReduce集群是由一个或多个阿里云ECS实例组成的Hadoop、Flink、Druid、ZooKeeper集群。以Hadoop为例,每个ECS 实例上通常都运行了一些daemon进程(例如,NameNode、DataNode、ResouceManager和NodeManager),这些daemon进程共同组成了Hadoop集群。
例如,下图是一个包含Master节点、Core节点和Task节点的Hadoop集群和Gateway集群。
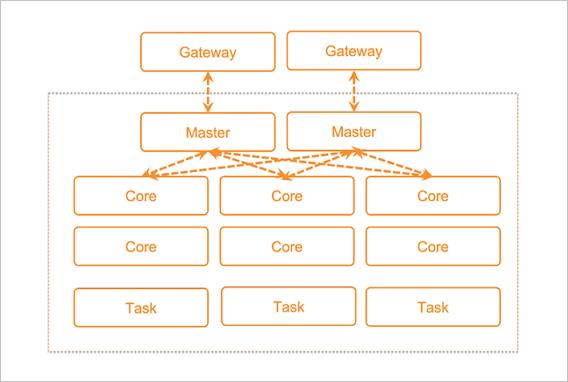
EMR部署架构
Master节点,部署了Hadoop的主节点服务,包括HDFS NameNode、HDFS JournalNode、ZooKeeper、YARN ResourceManager和HBase HMaster等服务,可以根据集群的使用场景,选择高可用集群或非高可用集群。测试环境可以选择非高可用集群,生产环境建议选择高可用集群。高可用集群可以选择2个或3个Master节点,当选择2个Master节点时,HDFS JournalNode和ZooKeeper会部署在Core的emr-worker-1节点。生产环境建议创建高可用集群时选择3个Master节点。
Core节点,部署了HDFS DataNode和YARN Nodemanager,用于HDFS数据的存储和YARN的计算,不可以弹性伸缩。
Task节点,部署了YARN NodeManager,用于YARN计算,可以通过弹性伸缩的方式灵活扩容或缩容。
Gateway集群,部署了Hadoop的客户端文件,您可以通过Gateway提交作业,避免直接登录集群产生的安全和客户端环境隔离问题。您需要先创建Hadoop集群,然后创建Gateway集群关联至Hadoop集群。
以上是关于E-MapReduce的主要内容,如果未能解决你的问题,请参考以下文章