OLAP实践 —— OLAP基本概念理解总计小记
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OLAP实践 —— OLAP基本概念理解总计小记相关的知识,希望对你有一定的参考价值。
1. 什么是OLAP
OLAP是OnLine Analytical Processing的缩写,即联机分析处理。OLAP对业务数据执行多维分析,并提供复杂计算、趋势分析和复杂数据建模的能力。OLAP主要用于支持企业决策管理分析,是许多商务智能(BI)应用程序背后的技术。OLAP使最终用户可以对多个维度的数据进行即席分析,从而获取他们所需知识,以便更好地制定决策。OLAP技术已被定义为实现 “ 快速访问共享的多维信息 ” 的能力。
2. 为什么要多维分析?
业务其实是一个多维活动。企业通过考虑许多变量来跟踪其业务活动,在电子表格上跟踪这些变量时,将它们设置在x轴 和 y轴上。
例如,可以在一年的时间内按月跟踪销售额,其中可以在y轴上显示销售指标,而在x轴上可以显示月份。而要分析业务的健康状况并计划未来的活动,必须连续跟踪许多变量组或参数。
例如,一个业务至少要考虑以下方面:客户,地点,期间,销售人员和产品。这些维度构成了公司计划,分析和报告活动的基础。它们共同代表了“整个”业务状况,为所有业务计划、分析和报告活动奠定了基础。
3. OLAP的起源
OLAP这个名词最早是在1993年,由被称为 “ 关系数据库之父 ” 的Edgar F. Codd在他的白皮书《Providing OLAP to User-Analysts: An IT Mandate》中首次提出的。在这个白皮书中,他为OLAP产品建立了12条评估规则:
多维概念视图(Multidimensional Conceptual View):在用户分析师看来,企业相关数据天然是多维的。 例如,可以按地区,产品,时间段或方案(例如实际,预算或预测)查看利润。多维数据模型使用户能够更直接,更直观地处理数据,包括“分片和分块”。透明性准则(Transparency):OLAP应该是开放系统体系结构的一部分,该体系结构可以嵌入到用户期望的任何位置,而不会影响宿主工具的功能。不应把OLAP工具的数据源暴露给用户,数据源可能是同构的或异构的。存取能力推测(Accessibility):OLAP工具应该能够应用自己的逻辑结构来访问异构数据源,并执行向用户呈现连贯视图所需的任何转换。工具(而不是用户)应关注物理数据的来源。稳定的报表性能(Consistent Reporting Performance):随着维度数量的增加,OLAP工具的性能不会受到显著影响。客户/服务器架构(Client-Server Architecture):OLAP工具的服务器组件应该足够通用,各种客户端可以轻松地连接它。服务器应该能够在不同的数据库之间映射和合并数据。维的等同性准则(Generic Dimensionalityc):每个数据维度的结构和操作能力都应相同。动态的稀疏矩阵处理准则(Dynamic Sparse Matrix Handling):OLAP服务器的物理结构应具有最佳的稀疏矩阵处理。多用户支持能力准则(Multi-User Support):OLAP工具必须提供并发检索和更新访问,完整性和安全性。非受限的跨维操作(Unrestricted Cross-dimensional Operations):计算设施必须允许跨任意数量的数据维度进行计算和数据处理,并且不得限制数据单元之间的任何关系。直观的数据操作(Intuitive Data Manipulation):合并路径中固有的数据操作,例如向下钻取或缩小,应通过对分析模型单元的直接操作来完成,而不需要使用菜单或跨用户界面多次行程。灵活的报告生成(Flexible Reporting):报告工具应以用户想要查看的任何方式显示信息。不受限的维度和聚合层次(Unlimited Dimensions and Aggregation Levels)
4. OLAP的发展历史
虽然OLAP的概念是在1993年才提出来的,但是支持OLAP相关产品的发展历史,最早可追溯到1975年
- 1975年,第一款OLAP产品Express于问世,随着被Oracle收购后繁荣发展了30余年,最后由继任者Oracle 9i替代。
- 1979年,第一个电子表格应用程序VisiCalc投放市场。 VisiCalc具有当今大多数电子表格应用程序中标准的基本行和列结构。
- 1982年,Comshare开发了一种新的决策支持系统软件(System W),这是第一个金融领域的OLAP工具,也是第一个在其多维建模中应用hypercube方法的工具。
- 1983年,IBM推出了Lotus 1-2-3。 它的结构类似于Visicalc,并迅速取代了Visicalc。 Lotus 1-2-3成为Windows之前的主流电子表格应用程序。
- 1984年,第一款ROLAP产品Metaphor发布。该多维产品建立了新概念,例如客户/服务器计算,关系数据的多维处理,工作组处理,面向对象的开发等。
- 1985年,Excel 1.0诞生。微软在Excel中集成了数据透视表功能可能是Excel产品最重要的增强功能之一,因为数据透视表已成为多维分析中最流行和使用最广泛的工具。
- 1989年,SQL语言标准诞生,它可以从关系数据库中提取和处理业务数据。这可能是个转折点。在1980‘s年代,电子表格在OLAP应用中占绝对主导地位;而1990’s年代以后,越来越多的基于数据库的OLAP应用开始出现:
- 1992年:Hyperion Solution发布Essbase(扩展电子表格数据库),在1997年成为市场上主要的OLAP服务器产品。
- 1997年:PARIS Technologies推出PowerOLAP:集成电子表格和事务数据库,以便在电子表格应用程序(例如Excel)中即时更新数据。
- 1999年:Microsoft OLAP服务发布,并于2000年成为Microsoft Analysis Services
- 2012年:PARIS Technologies发布了OLATION,它将关系和多维数据库技术(在SQL Server,SAP HANA,Oracle等中)融合在一起,确保对实际数据和计划数据进行“真正的在线”数据更新。
5. OLAP的核心概念
立方体(Cube):由维度构建出来的多维空间,包含了所有要分析的基础数据,所有的聚合数据操作都在立方体上进行。这里所说的立方其实就是多维模型中间的事实表(Fact Table),它会引用所有相关维的维主键作为自身的联合主键,加上度量(Measure)和计算度量(Calculated Measure)就组成了立方的结构。维度(Dimension):维度是描述与业务主题相关的一组属性,单个属性或属性集合可以构成一个维。如时间、地理位置、年龄和性别等都是维度。维度可以理解为立方体的一个轴。要注意的是有一个特殊的维度,即度量值维度。维的层次(Level of Dimension):一个维往往可以具有多个层次,例如时间维度分为年、季度、月和日等层次,地区维可以是国家、地区、省、市等层次。这里的层次表示数据细化程度,对应概念分层。后面介绍的上卷操作就是由低层概念映射到高层概念。概念分层除了可以根据概念的全序和偏序关系确定外,还可以通过对数据进行离散化和分组实现。维的成员(Member of Dimension):构成维度的基本单位,若维是多层次的,则不同的层次的取值构成一个维成员。部分维层次同样可以构成维度成员,例如“某年某季度”、“某季某月”等都可以是时间维的成员。度量(Measure):表示事实在某一个维成员上的取值。度量是用于描述事件的数字尺度,例如开发部门汉族男性有39人,就表示在部门、民族、性别三个维度上,企业人数的事实度量。计算度量是通过度量计算得到的。事实表(Fact Table):存放度量值的表,同时存放了维表的外键。所有的分析用的数据最终都是来自与事实表。维表(Dimension table):一个维度对应一个或者多个维表。一个维度对应一个维表时数据的组织方式就是采用的星型模式,对应多个维表时就是采用雪花模式。雪花模式是对星型模式的规范化。简言之,维表是对维度的描述。
6. OLAP和基本操作
OLAP的操作是查询,也就是数据库的 SELECT 操作为主,但是查询可以很复杂,比如基于关系数据库的查询可以多表关联,可以使用COUNT、SUM、AVG 等聚合函数。OLAP 正是基于多维模型定义了一些常见的面向分析的操作类型是这些操作显得更加直观。
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),下面还是以数据立方体为例来逐一解释下:
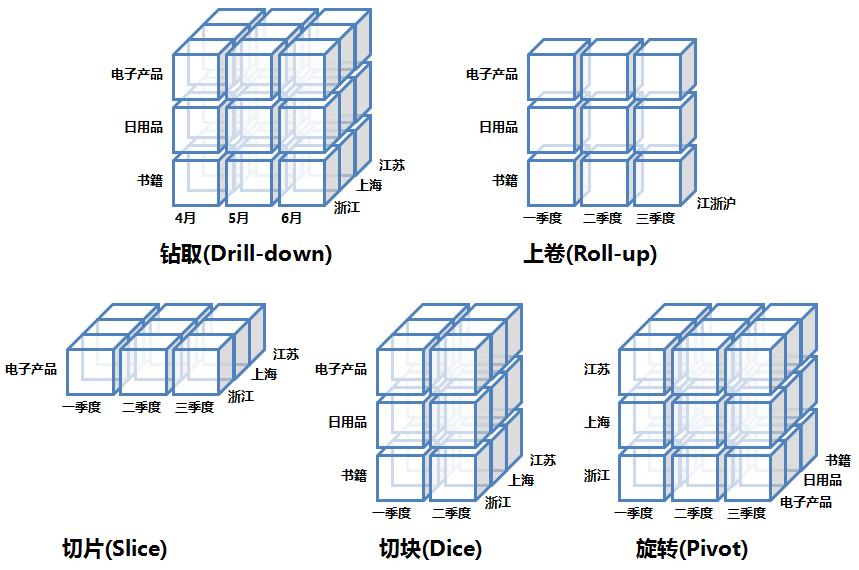
6.1 钻取(Drill-down)
在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,
比如通过对2010年第二季度的总销售数据进行钻取来查看第二季度4、5、6每个月的消费数据,
如下图;当然也可以钻取北京市来查看朝阳区、海淀区、大兴……这些区的销售数据。
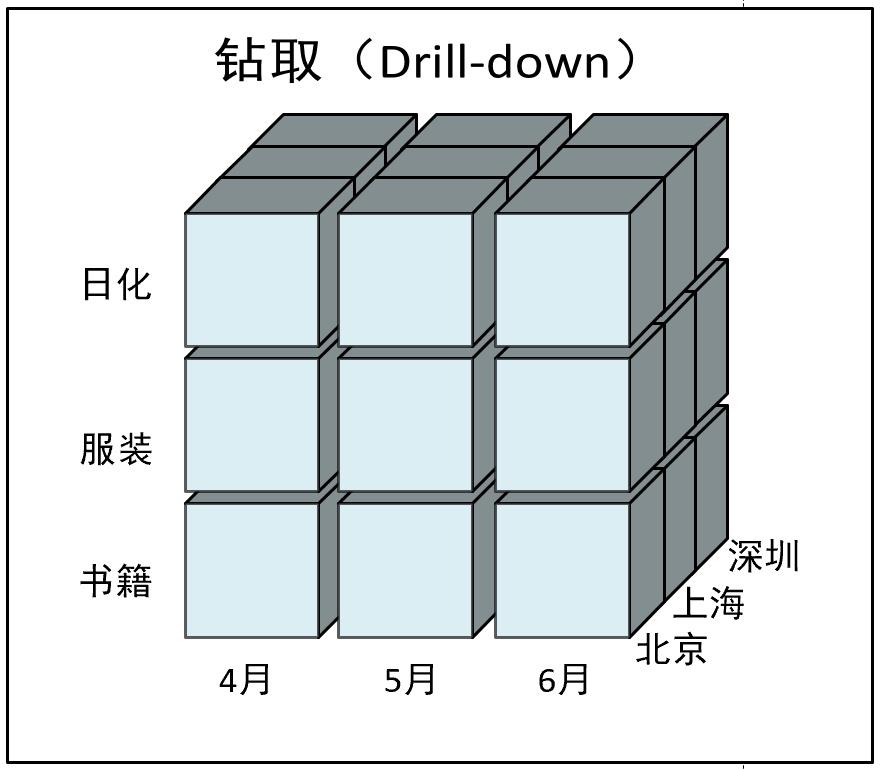
6.2 上卷(Roll-up)
钻取的逆操作,即从细粒度数据向高层的聚合,如将北京、上海和深圳的销售数据进行汇总来查看京沪深地区的销售数据,如下图。
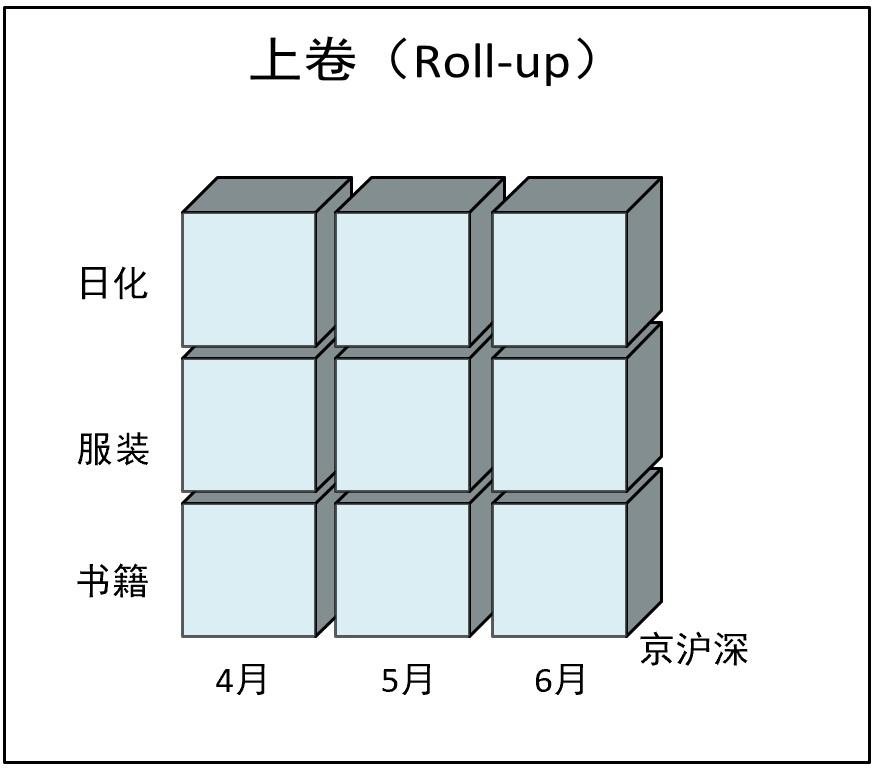
6.3 切片(Slice)
选择维中特定的值进行分析,比如只选择书籍产品的销售数据。
6.4 切块(Dice)
与切片类似,只是将单个特定值变成多个特定值,比如选择书籍和服装的销售数据。
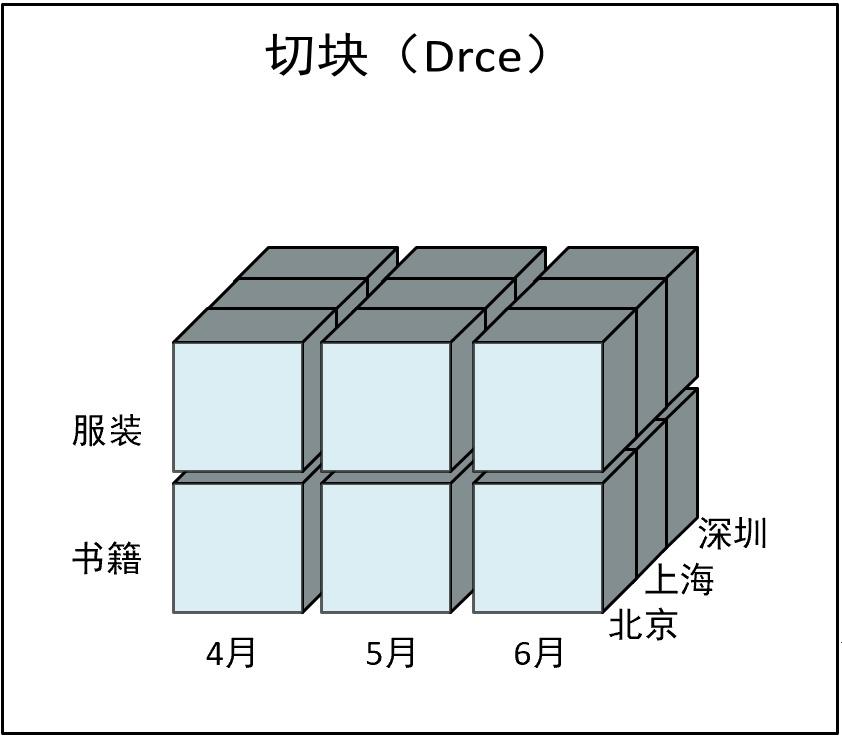
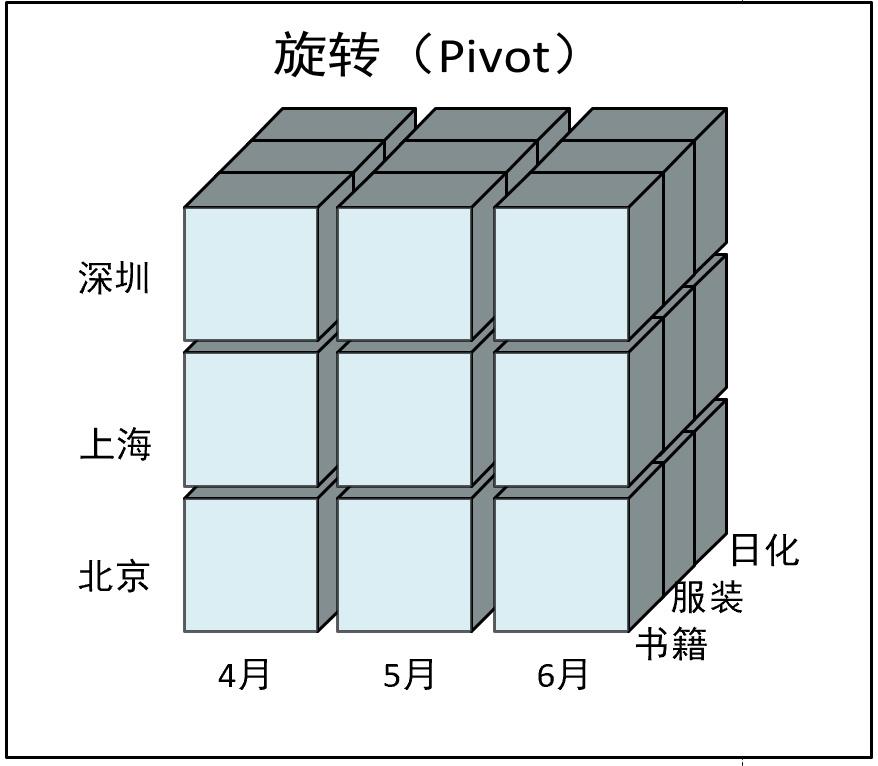
6.5 旋转(Pivot)
即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
7. OLAP的分类
按数据存储方式(建模类型)分类,可分为 MOLAP、ROLAP、HOLAP等。
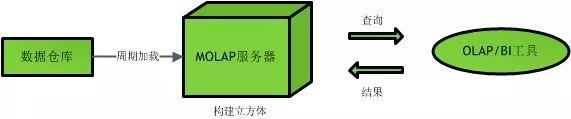
7.1 MOLAP(Multidimensional (多维的 )OLAP)
-
MOLAP:Multidimensional (多维的 )OLAP -
OLAP是OLAP的经典形式。MOLAP将数据存储在优化的多维数组中,而不是关系数据库中。 -
维的属性值被映射成多维数组的下标值或下标的范围,而度量数据作为多维数组的值存储在数组的单元中。
-
由于
MOLAP采用了新的存储结构,从物理层实现,因此又称为物理OLAP(PhysicalOLAP)。 -
一些
MOLAP工具要求对数据进行预计算和存储,这样的MOLAP工具通常利用被称为 “数据立方体” 的预先计算的数据集。 -
数据立方体包含给定范围的问题的所有可能答案。因此,它们对查询的响应非常快。另一方面,根据预计算的程度,更新可能需要很长时间。预计算也可能导致所谓的数据爆炸。
7.2 ROLAP(Relational (关系型) OLAP)
-
ROLAP:Relational (关系型) OLAP。 -
ROLAP将分析用的多维数据存储在关系数据库中。这种方式依赖SQL语言实现传统OLAP的切片和切块功能,本质上,切片和切块等动作都等同于在SQL语句中添加“WHERE”子句。 -
ROLAP工具不使用预先计算的多维数据集,而是对标准关系数据库及其表进行查询,以获取回答问题所需的数据。 -
ROLAP工具具有询问任何问题的能力,因为该方法(SQL)不仅限于多维数据集的内容。 -
尽管
ROLAP使用关系数据库作为底层存储,但这些数据库一般要针对ROLAP进行相应优化,比如并行存储、并行查询、并行数据管理、基于成本的查询优化、位图索引、SQL的OLAP扩展(cube,rollup)等等。 -
专为
OLTP设计的数据库不能像ROLAP数据库一样正常工作。 -
ROLAP主要通过一些软件工具或中间软件实现,物理层仍采用关系数据库的存储结构,因此称为虚拟OLAP(VirtualOLAP)。

7.3 HOLAP(Hybrid(混合型) OLAP)
-
HOLAP:Hybrid(混合型) OLAP。 -
HOLAP被为了使用一种 OLAP 工具解决 MOLAP和ROLAP 两者的缺点而提出的。 -
HOLAP工具通过
允许同时使用多维数据库(MDDB)和关系数据库(RDBMS)作为数据存储来弥合这两种产品的技术差距。 -
HOLAP允许模型设计者决定将哪些数据存储在MDDB中,哪些存储在RDBMS中, 例如,将大量详单数据存储在关系表中,而预先计算的聚合数据存储在多维数据集中。 -
目前整个行业对于“混合OLAP”的还没有达成明确的共识。
7.4 其他
7.4 .1 Web OLAP (WOLAP):
它是基于Web浏览器的技术。- 在传统的OLAP应用程序中,客户端/服务器可以访问该OLAP应用程序Web浏览器不可以访问该OLAP应用程序,但是WOLAP解决了这个问题。
- 它是一个
三层体系结构,由客户端,中间件和数据库服务器组成。 - 这种OLAP风格最吸引人的功能是
客户端方面的投资大大减少,并且增强了连接数据的可访问性。 - 基于Web的应用程序不需要在客户端计算机上进行部署。 所需要的只是一个Web浏览器和到Intranet或Internet的网络连接。
7.4.2 Desktop(桌面)OLAP (DOLAP):
DOLAP代表桌面分析处理。- 该用户可以从源下载数据并使用数据集,也可以在其桌面上使用。
- 与其他OLAP应用程序相比,功能受到限制。
- 它的价格便宜。
7.4.3 Mobile(移动)OLAP (MOLAP):
MOLAP是一种无线功能或移动设备。- 用户正在工作,并通过移动设备访问数据。
7.4.4 Spatial(空间)OLAP (SOLAP):
- 将地理信息系统(GIS)和OLAP的功能合并到单个用户界面SOLAP出口中。
- 之所以创建SOLAP,是因为数据以字母数字,图像和矢量的形式出现。 这样可以轻松快速地浏览空间数据库中的数据。
7.5 MOLAP与ROLAP对比分析
| 对比项 | MOLAP | ROLAP |
|---|---|---|
| 存储方式 | 专为OLAP设计和优化的存储,支持多维索引和缓存。 | 沿用现有的关系数据库的技术。 |
| 查询性能 | 具有较高的查询性能,响应速度快。 | 响应速度一般比MOLAP慢。 |
| 数据装载 | 数据装载速度慢。 | 加载速度通常比MOLAP加载要快得多。 |
| 维数限制 | 需要进行预计算,可能导致数据爆炸,维数有限制。 | 存储空间耗费小,维数没有限制。 |
| 访问接口 | 缺乏数据模型和数据访问的标准接口。 | 可以通过SQL实现详细数据与汇总数据的查询。 并且可以由任何SQL报告工具访问。 |
| 冗余存储 | MOLAP方法引入了数据冗余。 | 没有冗余数据。可与数据仓库共享同一份数据。 |
| 计算支撑 | 支持高性能的决策支持计算。 | 由于依赖数据库来执行计算,因此专用功能上有更多限制。 |
| 操作维护 | 维护困难 | 管理简便 |
8. OLAP与其他概念的关系
8.1 OLAP vs OLTP
两者设计的目标是完全不同的:
OLTP(On-Line Transaction Processing),联机事务处理,一般用于业务系统。OLTP对事务性处理的要求非常高,一般都是高可用的在线系统,主要基于传统的关系型数据库。其上的应用,一般以小的事务以及小的查询为主。评估其系统的时候,一般看其每秒执行的Transaction以及SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction(增、删、改)往往达到几百上千个,Select查询语句的执行量每秒几千甚至几万个。OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作。典型的OLTP系统有电子商务系统、银行交易系统、证券交易系统等。OLAP,有的时候也叫DSS决策支持系统,就是我们说的数据仓库。一般用于分析系统。强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。其上的应用。一般以大数据量的查询为主,修改和删除的操作较少。在这样的系统中,SQL语句的执行量不是考核指标,因为一条语句的执行时间可能会很长,读取的数据也非常多。所以,评估其系统的时候,往往是看系统的吞吐量、复杂查询响应时间、数据装载性能等。磁盘子系统的吞吐量则往往取决于磁盘的个数,这个时候,Cache基本是没有效果的,数据库的读写类型基本上是db file scattered read与direct path read/write。应尽量采用个数比较多的磁盘以及比较大的带宽,如4Gb的光纤接口。
| OLTP | OLAP | |
|---|---|---|
| 用户 | 操作人员 | 数据分析师、业务分析师、决策人员、高管 |
| 目的 | 操作处理,支持基本业务运行 | 发现和分析问题,支持决策 |
| 设计 | 面向应用,如银行业、零售业 | 面向主题,如销售、库存 |
| 特点 | 处理大量的小交易 | 使用复杂查询处理大量数据 |
| 数据内容 | 当前的、最新的业务交易数据 | 历史的、聚集的、统一的多维数据 |
| 查询类型 | 简单的、标准化的查询 | 复杂查询 |
| 数据操作 | 频繁的增、删、改操作;读取数据量不大 | 很少修改和删除操作;以读为主,读取数据量大。 |
| 时间要求 | 实时性要求高,通常是毫秒级 | 时间要求不严格,根据数据查询量,可以是秒级、分钟级甚至小时级 |
| 空间要求 | 通常较小,MB到GB级 | 由于要聚合大量数据,通常较大,GB到PB级 |
| 模型设计 | 为了保证数据修改的原子性,通常是规范化的数据模型,至少满足第三范式。 | 为了查询性能,通常是非规范化的数据模型 |
| 存储格式 | 修改操作频繁,通常是行存储 | 查询数据量大,通常是列式存储 |
| 主要应用 | 数据库 | 数据仓库 |
8.1.1 OLTP系统最容易出现瓶颈的地方就是CPU与磁盘子系统。
- CPU出现瓶颈常表现在逻辑读总量与计算性函数或者是过程上,逻辑读总量等于单个语句的逻辑读乘以执行次数,如果单个语句执行速度虽然很快,但是执行次数非常多,那么,也可能会导致很大的逻辑读总量。设计的方法与优化的方法就是减少单个语句的逻辑读,或者是减少它们的执行次数。另外,一些计算型的函数,如自定义函数、decode等的频繁使用,也会消耗大量的CPU时间,造成系统的负载升高,正确的设计方法或者是优化方法,需要尽量避免计算过程,如保存计算结果到统计表就是一个好的方法。
- 磁盘子系统在OLTP环境中,它的承载能力一般取决于它的IOPS处理能力. 因为在OLTP环境中,磁盘物理读一般都是db file sequential read,也就是单块读,但是这个读的次数非常频繁。如果频繁到磁盘子系统都不能承载其IOPS的时候,就会出现大的性能问题。
8.1.2 OLTP比较常用的设计与优化方式为Cache技术与B-tree索引技术
Cache决定了很多语句不需要从磁盘子系统获得数据,所以,Web cache与Oracle data buffer对OLTP系统是很重要的。另外,在索引使用方面,语句越简单越好,同时因为并发量很高,批量更新时要分批快速提交,以避免阻塞的发生。 这样执行计划也稳定 . 所以需要注意以下几点:
- 使用绑定变量
- 减少语句解析
- 尽量减少表关联
- 尽量减少分布式事务
- 基本不使用分区技术
- MV技术
- 并行技术
- 位图索引
OLTP 系统是一个数据块变化非常频繁,SQL 语句提交非常频繁的系统。对于数据块来说,应尽可能让数据块保存在内存当中,对于SQL来说,尽可能使用变量绑定技术来达到SQL重用,减少物理I/O 和重复的SQL解析,从而极大的改善数据库的性能。这里影响性能除了绑定变量,还有可能是热快(hot block)。 当一个块被多个用户同时读取时,Oracle为了维护数据的一致性,需要使用Latch来串行化用户的操作。当一个用户获得了latch后,其他用户就只能等待,获取这个数据块的用户越多,等待就越明显。这就是热快的问题。 这种热快可能是数据块,也可能是回滚端块。对于数据块来讲,通常是数据库的数据分布不均匀导致,如果是索引的数据块,可以考虑创建反向索引来达到重新分布数据的目的,对于回滚段数据块,可以适当多增加几个回滚段来避免这种争用。
8.1.3 在OLAP系统中,常使用分区技术、并行技术。
-
分区技术
在OLAP系统中的重要性主要体现在数据库管理上,比如数据库加载,可以通过分区交换的方式实现,备份可以通过备份分区表空间实现,删除数据可以通过分区进行删除,至于分区在性能上的影响,它可以使得一些大表的扫描变得很快(只扫描单个分区)。另外,如果分区结合并行的话,也可以使得整个表的扫描会变得很快。总之,分区主要的功能是管理上的方便性,它并不能绝对保证查询性能的提高,有时候分区会带来性能上的提高,有时候会降低。 -
并行技术
除了与分区技术结合外,在Oracle 10g中,与RAC结合实现多节点的同时扫描,效果也非常不错,可把一个任务,如select的全表扫描,平均地分派到多个RAC的节点上去。
在OLAP系统中,不需要使用绑定(BIND)变量,因为整个系统的执行量很小,分析时间对于执行时间来说,可以忽略,而且可避免出现错误的执行计划。但是OLAP中可以大量使用位图索引,物化视图,对于大的事务,尽量寻求速度上的优化,没有必要像OLTP要求快速提交,甚至要刻意减慢执行的速度。
绑定变量真正的用途是在OLTP系统中,这个系统通常有这样的特点,用户并发数很大,用户的请求十分密集,并且这些请求的SQL 大多数是可以重复使用的。
对于OLAP系统来说,绝大多数时候数据库上运行着的是报表作业,执行基本上是聚合类的SQL 操作,比如group by,这时候,把优化器模式设置为all_rows是恰当的。 而对于一些分页操作比较多的网站类数据库,设置为first_rows会更好一些。 但有时候对于OLAP 系统,我们又有分页的情况下,我们可以考虑在每条SQL 中用hint。 如:
Select a.* from table a; -
分开设计与优化
在设计上要特别注意,如在高可用的OLTP环境中,不要盲目地把OLAP的技术拿过来用。
如分区技术,假设不是大范围地使用分区关键字,而采用其它的字段作为where条件,那么,如果是本地索引,将不得不扫描多个索引,而性能变得更为低下。如果是全局索引,又失去分区的意义。
并行技术也是如此,一般在完成大型任务时才使用,如在实际生活中,翻译一本书,可以先安排多个人,每个人翻译不同的章节,这样可以提高翻译速度。如果只是翻译一页书,也去分配不同的人翻译不同的行,再组合起来,就没必要了,因为在分配工作的时间里,一个人或许早就翻译完了。
位图索引也是一样,如果用在OLTP环境中,很容易造成阻塞与死锁。但是,在OLAP环境中,可能会因为其特有的特性,提高OLAP的查询速度。MV也是基本一样,包括触发器等,在DML频繁的OLTP系统上,很容易成为瓶颈,甚至是Library Cache等待,而在OLAP环境上,则可能会因为使用恰当而提高查询速度。
对于OLAP系统,在内存上可优化的余地很小,增加CPU 处理速度和磁盘I/O 速度是最直接的提高数据库性能的方法,当然这也意味着系统成本的增加。
比如我们要对几亿条或者几十亿条数据进行聚合处理,这种海量的数据,全部放在内存中操作是很难的,同时也没有必要,因为这些数据快很少重用,缓存起来也没有实际意义,而且还会造成物理I/O相当大。 所以这种系统的瓶颈往往是磁盘I/O上面的。
对于OLAP系统,SQL 的优化非常重要,因为它的数据量很大,做全表扫描和索引对性能上来说差异是非常大的。
8.2 OLAP vs 数据仓库/数据集市
数据仓库建设好以后,用户就可以编写SQL语句对其进行访问并对其中数据进行分析。但每次查询都要编写SQL语句的话,未免太麻烦,而且对维度建模数据进行分析的SQL代码套路比较固定。于是,便有了OLAP工具,它专用于维度建模数据的分析。在规范化数据仓库中OLAP工具和数据仓库的关系大致是这样的:
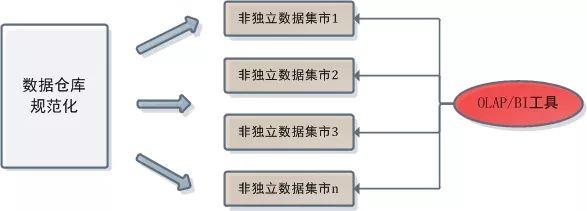
这种情况下,OLAP不允许访问中心数据库。一方面中心数据库是采取规范化建模的,而OLAP只支持对维度建模数据的分析;另一方面规范化数据仓库的中心数据库本身就不允许上层开发人员访问。
数据仓库的建模方式有多种:
8.2.1 ER模型(实体-关系模型)
ER模型,全称为实体联系模型、实体关系模型或实体联系模式图(ERD)(英语:Entity-relationship model)由美籍华裔计算机科学家陈品山发明,是概念数据模型的高层描述所使用的数据模型或模式图。 [1]
ER模型常用于信息系统设计中;比如它们在概念结构设计阶段用来描述信息需求和/或要存储在数据库中的信息的类型。但是数据建模技术可以用来描述特定论域(就是感兴趣的区域)的任何本体(就是对使用的术语和它们的联系的概述和分类)。在基于数据库的信息系统设计的情况下,在后面的阶段(通常叫做逻辑设计),概念模型要映射到逻辑模型如关系模型上;它依次要在物理设计期间映射到物理模型上。注意,有时这两个阶段被一起称为“物理设计”。
实体联系模式图(ERD)有一些约定。本文的余下部分描述经典概念,并且主要与概念建模有关。有一些概念更加典型的在逻辑和物理数据库设计中采用,包括信息工程、IDEF1x(ICAM DEFinition Language)和空间建模。
8.2.2 Data Vault模型
Data Vault是一种数据仓库建模方法,最早由Dan Linstedt在20世纪90年代提出,主要应用于企业级数据仓库建模。- 不同于三范式数据仓库模型、维度模型,
Data Vault模型主要用于存储来自多个业务系统的完整的历史数据。它不区分数据在业务层面的准确与否,装载数据也不做验证和清洗,因此,Data Vault模型可用于跟踪所有数据的来源。 - 它的每一行数据都需要包含来源系统和装载时间戳,用于审计和跟踪数据来源的源系统。
8.2.3 Anchor模型
Anchor模型是对Data Vault模型做了进一步规范化处理,设计初衷是设计一个高度可扩展的模型,其核心思想是所有的扩展只是添加而不是修改,因此将模型规范到6NF,基本上变成了k-v结构化模型。
前面三种模型主要致力将各个业务系统中的数据整合到统一的数据仓库中,并进行一致性处理,提供满足第三范式或更高范式的数据模型和原子数据。这种数据仓库被称为CIF(Corporate Information Factory,企业信息工厂)架构下的企业数据仓库。这种数据仓库架构是数据仓库之父Inmon所推崇的。但由于使用了规范化模型,这使得对这些原子数据进行查询变得很困难,这种架构并不能很好地直接用于支撑分析决策。为了更好的支持分析,在这种架构下,通常需要在数据仓库的基础上,按主题建立一些数据子集,也就是数据集市。这些数据集市通常采用维度模型,OLAP工具就可以基于数据集市而工作。数据集市通常就是基于OLAP系统而构建。
8.2.4 维度模型
维度建模从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速的完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下使用雪花模型。
维度模型另一位数据仓库领域的大师Kimball提出的,是目前数据仓库领域最流行的建模方式。维度模型可以很好地支撑分析决策需求,同时还有较好的大规模复杂查询的响应性能。维度模型可以直接使用OLAP工具与其对接。Kimball所推崇的数据仓库架构如下,基于这种架构建立的数据仓库,可以直接提供OLAP能力。这样建立的数据仓库本身也就成为了一个OLAP系统。
8.3 OLAP vs 数据仓库的概念模型
最流行的数据仓库概念是多维数据模型。这种模型可以以星型模式,雪花模式,或事实星座模式的形式存在。
星型模式(Star schema):
事实表在中心,周围围绕地连接着维表(每维一个),事实表包含有大量数据,没有冗余。
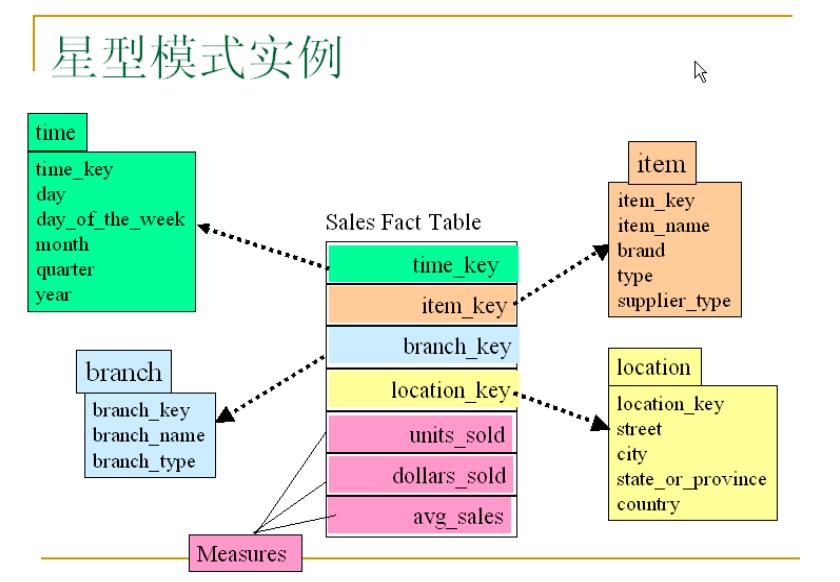
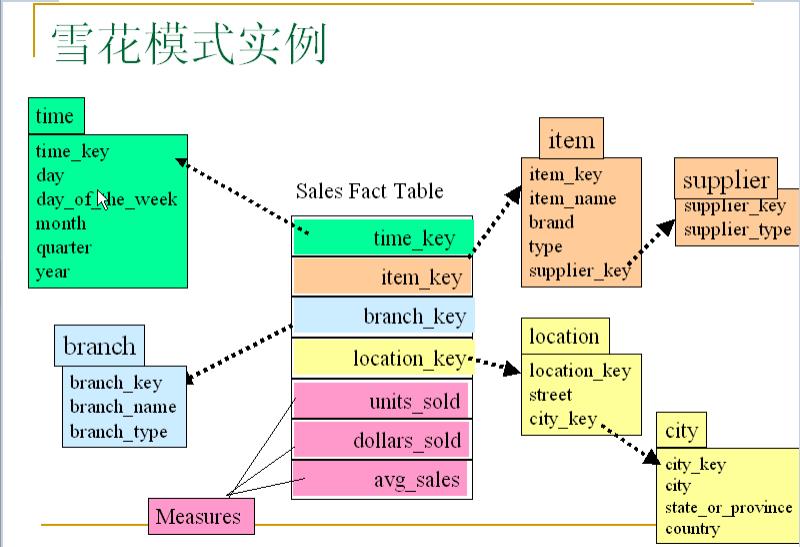
雪花模式(Snowflake schema):
是星型模式的变种,其中某些维表是规范化的,因而把数据进一步分解到附加表中。结果,模式图形成类似雪花的形状。雪花模型相较于星座模型,是把维表进行了规范化。
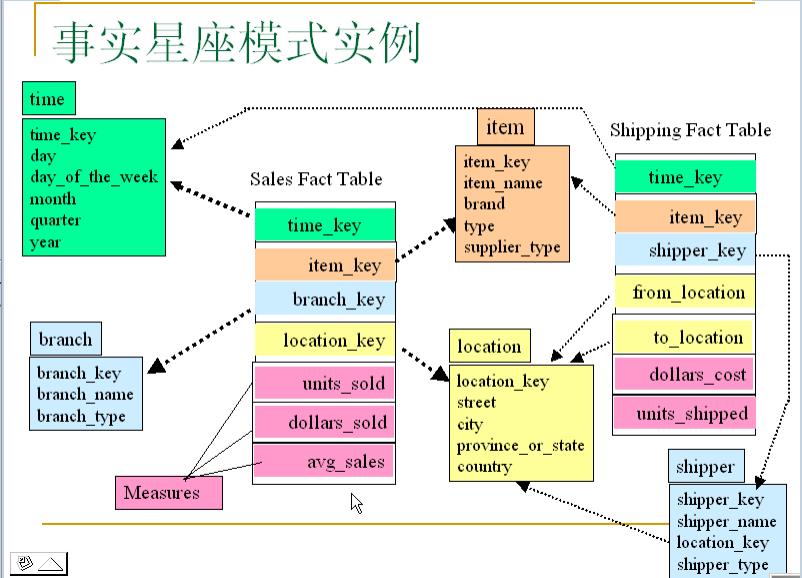
事实星座(Fact constellations):
多个事实表共享维表,这种模式可以看作星座模式集,因此称作星系模式(galaxy schema),或者事实星座(fact constellation)。事实星座模式是把事实间共享的维进行合并。对概念进行分层,有利于数据的汇总。
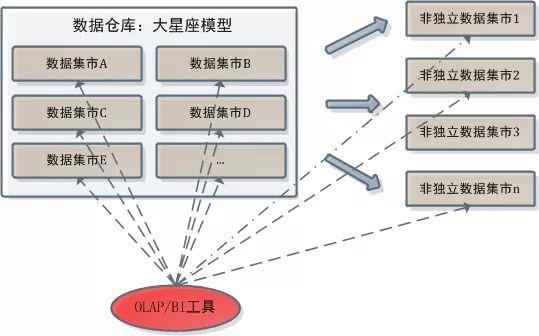
8.4 OLAP vs BI工具
BI是Business Intelligence的英文缩写,中文解释为商务智能,是利用数据提高决策质量的技术集合,是从大量的数据中钻取信息与知识的过程。OLAP和BI常常在一起出现,OLAP是BI工具的一种底层技术。BI工具通常可以对接OLAP系统,但不限于此,也可以直接与其他数据库、存储系统对接。在维度建模数据仓库中,OLAP/BI工具和数据仓库的关系则是这样的:
8.5 OLAP vs 即席查询
Ad hoc是一个拉丁文常用短语,意思是“特设的、特定目的的(地)、临时的、专案的”。即席查询(Ad Hoc Queries)是指用户根据自己的需求动态创建的查询,与预定义查询相反。
即席查询对数据模型没有要求,只要能提供动态查询的能力即可;而OLAP系统,一般要求数据模型是多维数据模型。对于ROLAP系统,通常都能提供即席查询能力,二者之间差别很小,所以经常混用。
以上是关于OLAP实践 —— OLAP基本概念理解总计小记的主要内容,如果未能解决你的问题,请参考以下文章