Redis学习笔记
Posted dingwen_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis学习笔记相关的知识,希望对你有一定的参考价值。
文章目录
Redis(Remote Dictionary Server),远程字典服务。官网https://redis.io/。是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。Redis命令不区分大小写,key的名称区分大小写。
互联网的3V3高
海量 Volume
多样 Variety
实时 Velocity
高并发
高可扩
高性能
1.功能特性
- 多样化数据内存存储
- 高速缓存
- 持久化
- 发布订阅
- 事务
- 集群
2.安装
2.1Linux源码包安装
https://blog.csdn.net/qq_38020915/article/details/117625924
2.2Docker安装
https://blog.csdn.net/qq_38020915/article/details/117624725
2.3yum 安装
# 0. 检查redis版本
yum list | grep redis
## 如果版本不符合要求则更新版本repo文件
# 1.安装redis
yum install redis
# 2.修改配置文件
vim /etc/redis.config
bind 配置(表示的是此`redis`服务接收访问的`ip``)
# 3.关闭保护模式
protected-mode no
# 4.启动
systemctl start redis
# 5.客户端测试
redis-cli
3.redis-benchmark性能测试
3.1 参数
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | –csv | 以 CSV 格式输出 | |
| 12 | *-l*(L 的小写字母) | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | *-I*(i 的大写字母) | Idle 模式。仅打开 N 个 idle 连接并等待。 |
3.2案例
# 测试:100个并发连接 100000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
4.基础知识
4.1 客户端相关
redis-cli连接到客户端ping测试若返回PONG表示成功exit退出客户端shutdown关闭redis服务
4.2数据库相关
- 默认有16个数据库,
redis.conf可配置默认databases 16 - 默认使用的是0号数据库
select切换数据库dbsize查看数据库大小flushdb清除当前数据库内容flushall清除所有数据库内容keys *查看所有的key(当前库)
redis是单线程的,基于内存操作。多线程CPU上下文切换会消耗一部分时间。
4.3 Key
set k v设置值get k获取k的值get k获取值exists k判断key是否存在keys *获取当下库所有keymove key db将key移动到db库,注意在本库移动会报错del key删除keyexpire key second设置key的过期时间(秒)ttl key查看key的剩余时间type key查看当前Key的类型
5.五大数据类型
5.1 string
主要应用场景: 对象,数量统计,
string。
append key value向key追加value内容,如果key不存在相当于set key valuestrlen key获取key的字符串长度substr key start end截取从[start,end]的字符串内容getrange key start end获取从[start,end]d的字符串内容[0,-1]表示全部setrange key index value将index处替换为valueincr key整数类型自增1decr key整数类型自减incrby key value设置自增步长自增decrby key value设置自减步长自减setnx key value如果key不存在设置,存在则报错setne key seconds value设置key并且seconds秒后过期值为value,如果key存在则覆盖mset k1 v1 ... ... kn vn同时设置多个mget k1 ... kn同时获取多个值msetnx k1 v1 ... kn vn同时设置多个值,值存在则报错。这是一个原子操作,要么一起成功要么一起失败- 存储对象key:【对象名称】:【ID】value: 【对象值】
set user:100 '{name: dingwen age:24}' getset key value先获取key的值,没有的话设置value
5.2 list
底层是链表实现,压缩列表和双向链表的结合。
lpush key value往key的list中插入value 。从左边插入rpush key value往key的list中从右边插入valuelrange start end获取list中的值,[start,end] [0,-1]表示全部rpop key从右边移除一个元素lpop key从左边移除一个元素lindex key index获取list下标为index的值,从零开始llen key获取list的长度lrem key count value移除list中指定数量的valueltrim key start end将;list[start,end]截取出来,原来的list已经不存在了rpoplpush recources destination将recources中右边最后一个元素移动到destinationd的左边第一个lset key index value将list中指定下标都是值替换,如果值不存在则报错linsert key before || after item value在指定元素item前面或者后面插入新值value
5.3set
HashTable实现,底层数组加链表,set中的值是不能重复的。应用:共同好友、共同关注、共同爱好、二度好友、推荐。
sadd key valueset中添加元素smembers key查看set中的所有元素sismember key value判断set中是否包含这个值scard key获取集合中元素个数srem key value删除集合中指定元素srandmemeber key [count]随机抽取count个元素,count不写默认为1spop key [count]随机删除count个元素,count不写默认为1smove key recources destination将一致指定的值移动到另一个setsdiff key1 key2两个set求差集sinter key1 key2两个set求交集sunion key1 key2两个set求并集
5.4 zset
实现原理和set一致,区别在于给元素加了权重作为排序的依据
zadd key score value添加元素,score表示权重作为排序的依据zrange key [satrt,end]查看指定区间元素,[0,-1]表示全部zrangebyscore key -inf +inf按照score从小到大排序zrevrange key 0 -1按照score从大到小排序zrangebylex key 【- || 空】【开区间 ( || 闭区间】value指定区间排序zrangebyscore key -inf +inf withscores查看所有元素并且加上权重zrangebyscore key -inf value withscores查看所有元素并且加上权重并且小于valuezrem key value删除指定值zadd s1 k1 v1 ... sn kv vn支持多个zcount key [start,end]指定区间的元素个数,注意区间值是权重
5.5 hash
Map集合,key-map! 时候这个值是一个map集合! 本质和String类型没有太大区别,还是一个简单的key-vlaue。底层数据结构是hashtable。
hset key filed value设置值hmset key filed value ...同时设置多个值hget key filed获取值hmget key filed ...同时获取多个值hgetall key获取所有值,包括key以及所有filedhlen key获取哈希的长度(几个filed)hdel key filed删除某个filedhkeys key获取哈希的所有filed字段hexists key filed判断某一个field是否存在hincrby key filed(数字) (+ || -)number在filed基础上进行自增自减hsetnx key field value如果不存在是设置,已存在不能设置
6.三种特殊类型
6.1 Geospatial
地理位置信息。应用:朋友定位、附近的人、打车距离计算
底层是set实现
测试数据:https://jingweidu.bmcx.com/
-
geoadd key longitude latitude member: 添加地理信息(有效经度范围[-180,180] 纬度范围[-85.05112878,85.05112878] , 两级不能添加) -
geopos key member:获取指定成员的经纬度信息 -
geodist key member1 member2 【单位】:计算两点之间的距离- m
- km
- ft 英尺
- mi 英里
-
georadius key longitude latitude radius m|km|ft|mi [ withdist withcoord count number]以给定经纬度为中心查找指定半径内人元素。withdist:显示到目标点的距离,withcoord: 显示经纬度信息 count number 筛选几个 -
georadiusbymember key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]找出位于指定元素周围的其他元素 -
geohash key member [member ...]返回一个或多个位置元素的 Geohash 表示 -
zrange [satrt,end]查看指定区间的元素,[0,-1]表示全部 -
zrem key member移除元素
6.2 Hyperloglog
基数,不重复的数据,允许容错。优点:占用的内存是固定,2^64 不同的元素的技术,只需要废 12KB内存!如果要从内存角度来比较的话 Hyperloglog 首选!应用:网页的 UV (一个人访问一个网站多次,但是还是算作一个人!)。
pfadd key element [element ...]创建一组元素pfcount key [key ...]统计元素的数量pfmerge destkey sourcekey [sourcekey ...]合并两组取交集
6.3 Bitmap
位存储,0|1。应用: 打卡…
setbit key offset value设置值getbit key offset获取值bitcount key [start,end]统计指定范围内的为1的数量
7.事务
Redis事务本质,一组命令的集合,一个事务中的所有命令都会被序列化,按照顺序依次执行。注意:Redis事务没有隔离级别的概念,事务中的所有命令没有直接执行,只有发起执行是才执行。Redis事务单条命令保证原子性,整个事务是没有原子性的。
## 如果在事务指定过程中,某条命令出现了编译错误则该事务的所有命令都不会执行,事务取消,如果出现了运行时错误,则只是错误命令没有执行成功,其他命令也会执行
# 开启事务
multi
命令1
...
命令n
# 取消事务
discard
# 执行事务
exec
6.2.1 监控watch(乐观锁实现)
- 悲观锁:认为什么时候都会出错,任何操作都会加锁
- 乐观锁: 认为什么时候都不会出错,不会上锁。在更新数据的时候去判断一下,看数据是否改变过。
# Redis 监视
set money 100
watch
multi
incrby money 200
get money
# 此期间有其他线程修改了money,执行结果为null
exec
# 解锁从新执行即可
unwatch
# 获取最新的值
watch money
# 开启事务
multi
...
...
# 执行成功
exec
8.配置文件详解
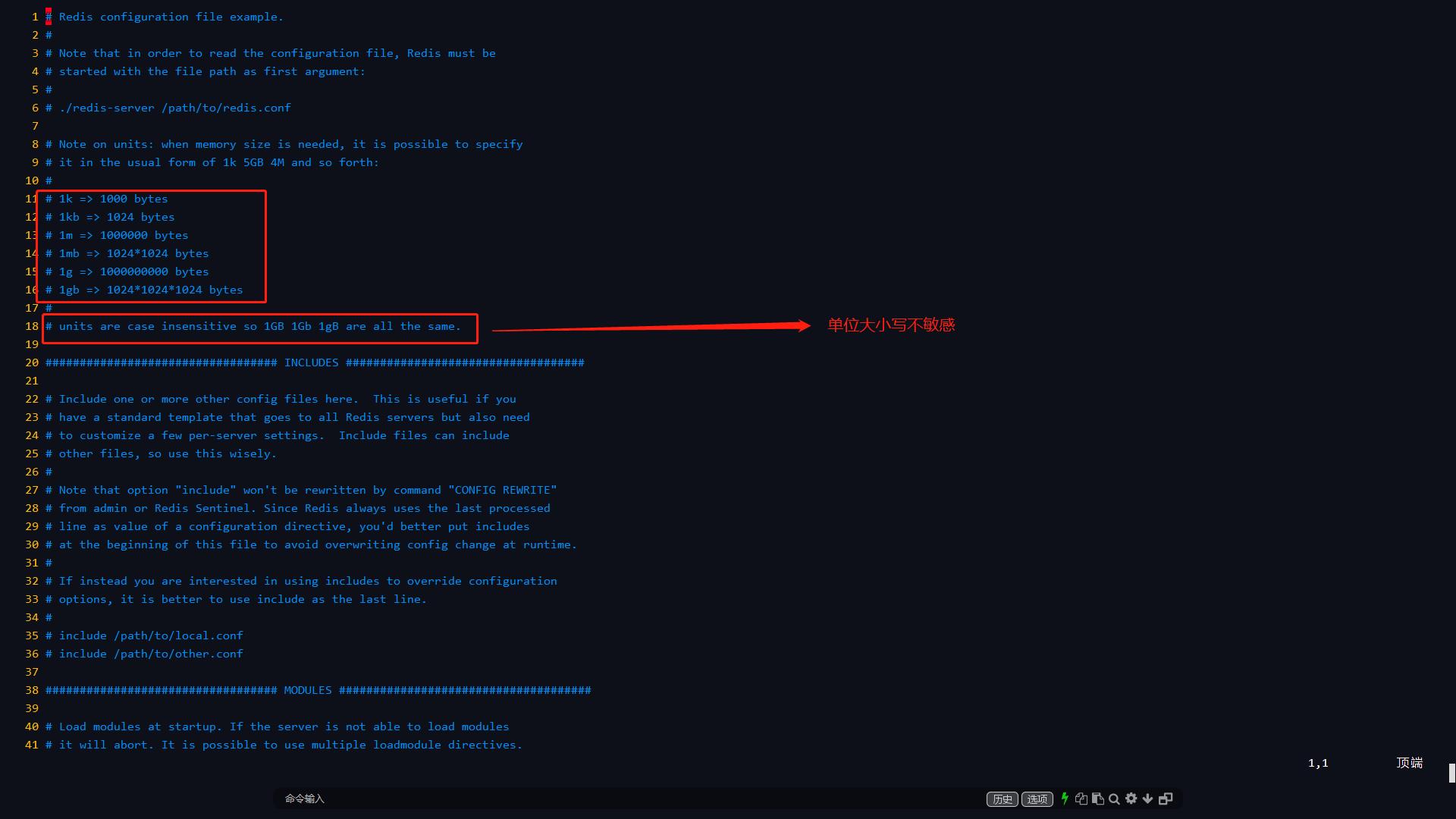
8.1 单位
对大小写不敏感。
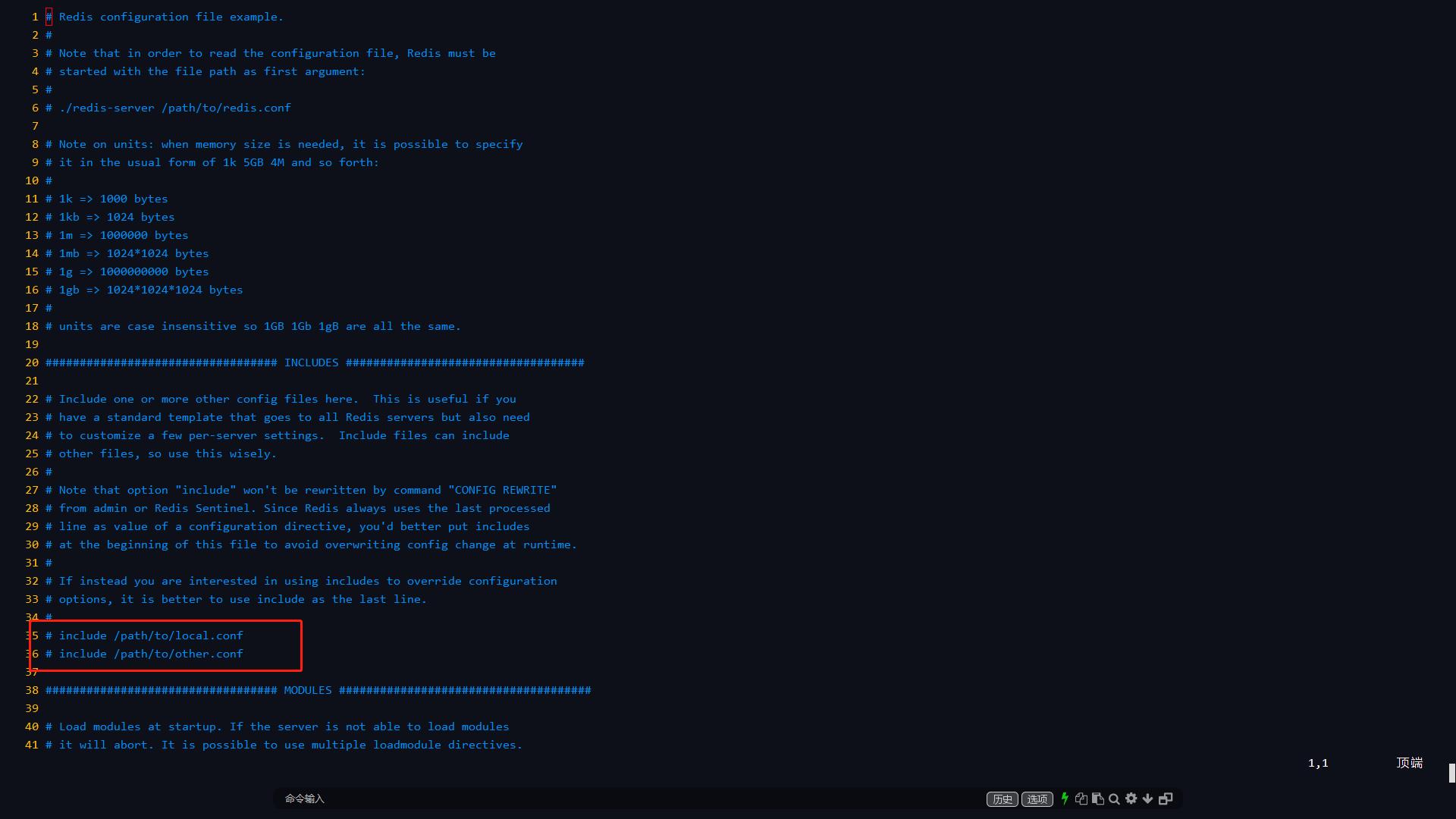
8.2 配置文件包含(include)
可以将多个配置文件进行组合,开发中经常使用这种方式。
8.3 网络相关
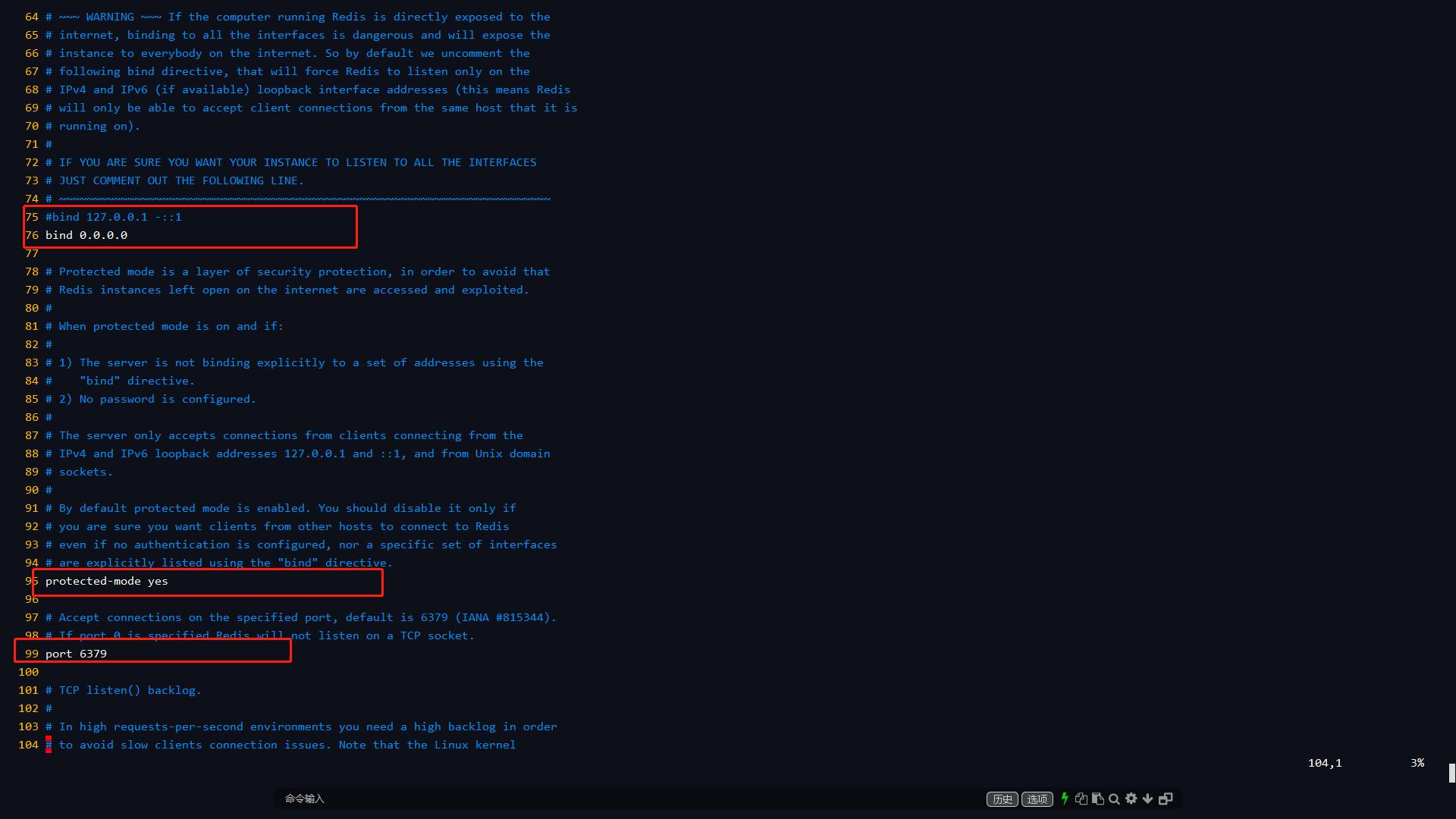
8.3.1 bind
bind的意思不是绑定外部服务器的IP,而是绑定本机可以接受访问的IP。0.0.0.0表示此
redis服务支持所有ip访问。
8.3.2 protected-mode
关闭protected-mode模式,此时外部网络可以直接访问,开启protected-mode保护模式,需配置bind ip或者设置访问密码。
8.3.3 port
端口号
8.4 通用配置(general)
8.4.1 daemonzie
是否以守护进程的方式启动,默认是no。
8.4.2 pidfile
系统进程文件,以后台的方式运行
Redis服务的话必须指定一个进程文件。
8.4.3 logfile
指定日志文件的位置以及名称,注意在基于的环境中需要分别设置记录不同的日志,也包含不同的端口号、进程文件设置。
8.4.4 databases
数据库的数量,默认为16个。
8.4.5 logo
# 是否显示redis logo
always-show-logo yes
8.5 快照(snapshotting)
在规定的时间内,进行了多少次操作就进行持久化。
# 如果900s内,如果至少有一个1 key进行了修改,就进行持久化操作
save 900 1
# 如果300s内,如果至少10 key进行了修改,就进行持久化操作
save 300 10
# 如果60s内,如果至少10000 key进行了修改,就进行持久化操作
save 60 10000
# 持久化如果出错,是否还需要继续工作
stop-writes-on-bgsave-error yes
# 是否压缩 rdb 文件,需要消耗一些cpu资源
rdbcompression yes
# 保存rdb文件的时候,是否进行错误文件的检查
rdbchecksum yes
# rdb 文件保存的目录!
dir ./
8.6 replication
主从配置,后面另起章节说明。
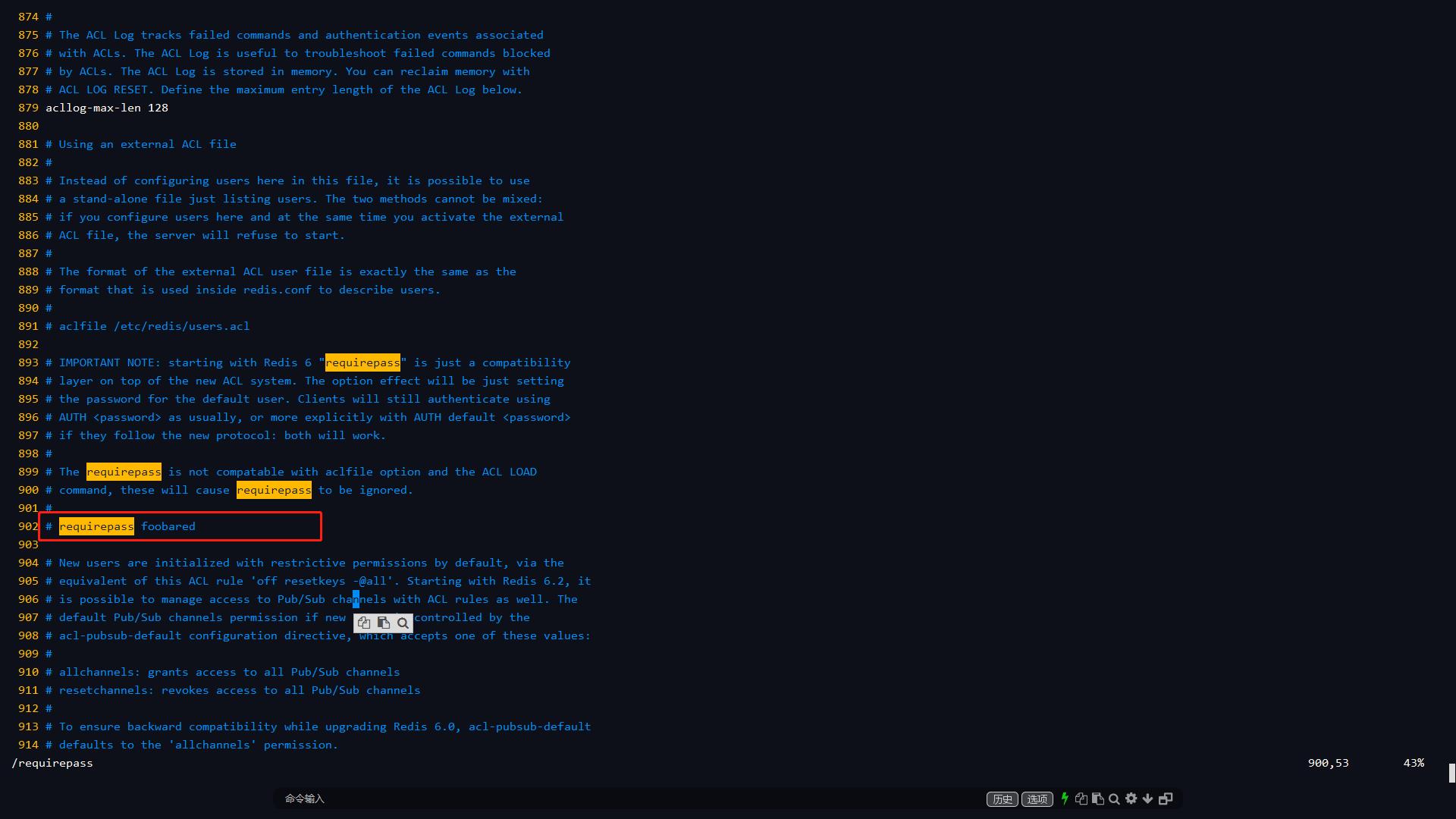
8.7 security
设置访问的密码,默认没有密码,设置之后需要密码才能进行登录。命令暂时设置,和配置文件永久设置都可以。
127.0.0.1:6379> config set requirepass ding
OK
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> exit
[root@dw conf]# redis-cli
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth ding
OK
127.0.0.1:6379> ping
PONG
8.8clients
对客户端的限制配置。
# 设置能连接上redis的最大客户端的数量
maxclients 10000
# redis 配置最大的内存容量
maxmemory <bytes>
# 内存到达上限之后的处理策略
maxmemory-policy noeviction
#1、volatile-lru:只对设置了过期时间的key进行LRU(默认值)
#2、allkeys-lru : 删除lru算法的key
#3、volatile-random:随机删除即将过期key
#4、allkeys-random:随机删除
#5、volatile-ttl : 删除即将过期的
#6、noeviction : 永不过期,返回错误
8.9 持久化配置
8.9.4 RDB
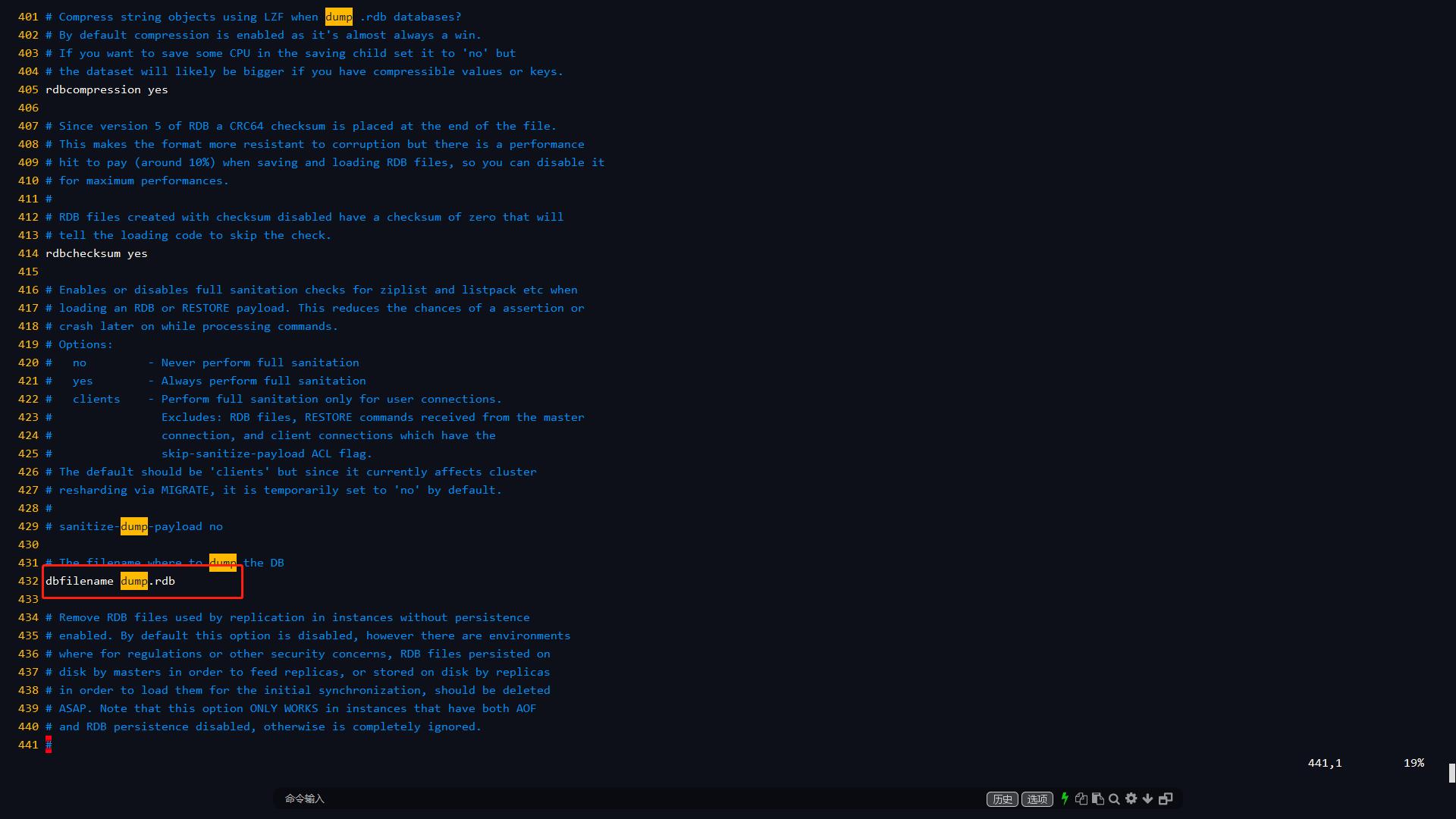
默认为rdb模式,文件名配置为
dbfilename dump.rdb。
8.9.5 AOF
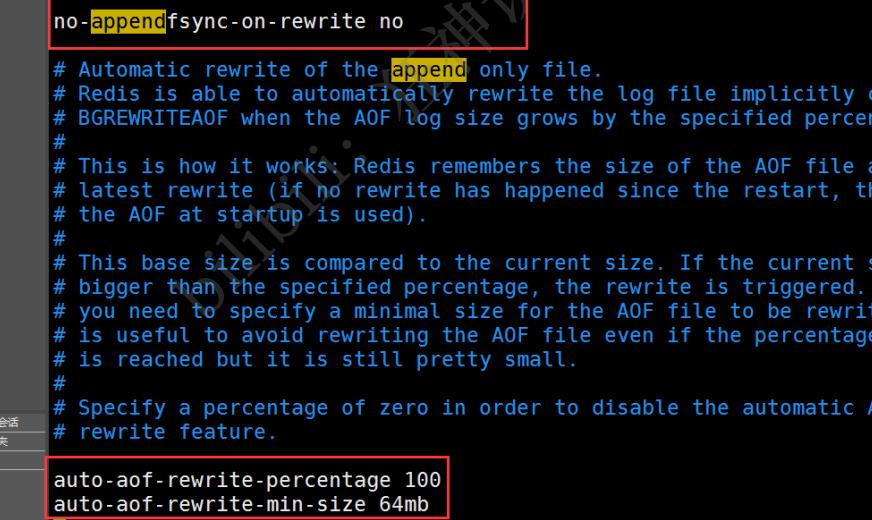
# 默认是不开启aof模式的
appendonly no
# 持久化的文件的名字
appendfilename "appendonly.aof"
# 每次修改都会 sync 消耗性能
# appendfsync always
# 每秒执行一次 sync,可能会丢失这1s的数据!
appendfsync everysec
# 不执行 sync,这个时候操作系统自己同步数据,速度最快!
# appendfsync no
9. Redis持久化
9.1 RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是Snapshot快照,它恢复时是将快照文件直接读到内存里。 Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的。 这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那 RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。我们默认的就是 RDB。
9.1.1 触发机制
- save的规则满足的情况下
- 执行 flushall 命令
- 退出redis
9.1.2 优点
- 适合大规模的数据恢复
- 对数据的完整性要不高
9.1.3 缺点
- redis意外宕机会损失最后一次的数据
- fork进程的时候,会占用一定的内容空间
9.1.4 恢复
只需要将rdb文件放在我们redis启动目录就可以,redis启动的时候会自动检查dump.rdb 恢复其中 的数据
# 查看需要存放的位置
127.0.0.1:6379> config get dir
9.2 AOF
== appendonly.aof ==
将有命令都记录下来,恢复的时候就把这个文件全部在执行一遍。
以日志的形式来记录每个写操作,将Redis执行过的所有指令记录下来(读操作不记录),只许追加文件 但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件 的内容将写指令从前到后执行一次以完成数据的恢复工作。
默认关闭,其他配置见配置章节。
9.2.1 重写规则
aof 默认就是文件的无限追加,如果 aof文件大小超过文件大小则fork一个新的进程来对文件进行压缩重写。
文件大小可以配置。
9.2.2 fix
如果aof文件有错误的命令语法等等,可使用
redis-check-aof --fix修复文件恢复数据。
9.2.3 优点
- 数据完整性好
9.2.4 缺点
- 占内存
- 效率低
10. 与SpringBoot2.X整合基于lettuce
10.1 maven配置文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.dingwen</groupId>
<artifactId>stu-spr-boo-red</artifactId>
<version>1.0.0-SNAPSHOT</version>
<name>stu-spr-boo-red</name>
<description>stu-spr-boo-red</description>
<properties>
<java.version>1.8</java.version>
<jackson.version>2.10.0</jackson.version>
</properties>
<dependencies>
<!--redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--jackson-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
10.2 修改默认配置
package com.dingwen.stusprboored.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.JsonTypeInfo;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* redis 配置类
*
* @author dingwen
* 2021.06.11 15:51
*/
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// 自定义redisTemplate 默认是<Object,Object> 需要类型强转
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 配置连接工厂
template.setConnectionFactory(factory);
//使用Jackson2JsonRedisSerializer来序列化和反序列化redis的value值(默认使用JDK的序列化方式)
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.WRAPPER_ARRAY);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
// 值采用json序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
// 设置hash key序列化模式
template.setHashKeySerializer(new StringRedisSerializer());
// 设置hash value序列化模式
template.setHashValueSerializer(jackson2JsonRedisSerializer);
// 在初始化方法执行之前执行
template.afterPropertiesSet();
return template;
}
}
10.3 完整代码地址,包括工具类封装
https://gitee.com/dingwen-gitee/stu-spr-boo-red.git
11. 发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
# 订阅一个频道
subscribe 【频道名称】
# 发布消息到指定频道
publish 【频道名称】 【消息名称】
12. 主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点 (master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。 Master以写为主,Slave 以读为主。 默认情况下,每台Redis服务器都是主节点; 且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
12.1 作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载
- 高可用(集群)基石:哨兵和集群保证高可用
12.2 查看配置信息
127.0.0.1:6379> info replication # 查看当前库的信息
# Replication
role:master # 角色 master
connected_slaves:0 # 没有从机
master_replid:b63c90e6c501143759cb0e7f450bd1eb0c70882a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
12.3 准备配置文件实现一主二从
12.3.1 服务准备
依次准备三个配置文件,指定配置文件启动三个redis服务。修改内容包括端口号、pid、log、dump.rdb
12.3.2 配置
一般都不在配置文件中配置,命令配置更方便。默认情况下,每台Redis服务器都是主节点; 我们一般情况下只用配置从机。
# 再从机中配置主机
slaveof 【IP】 【端口号】
12.3.3 细节
主机可读可写,从机中只能读。
主机断开连接,从机依旧连接到主机的,但是没有写操作,这个时候,主机如果回来了,从机依 旧可以直接获取到主机写的信息。
12.3.4 复制原理
ave 启动成功连接到 master 后会发送一个sync同步命令 Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行 完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中
- 增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步
只要重新连接master,一次全量复制将自动被执行。
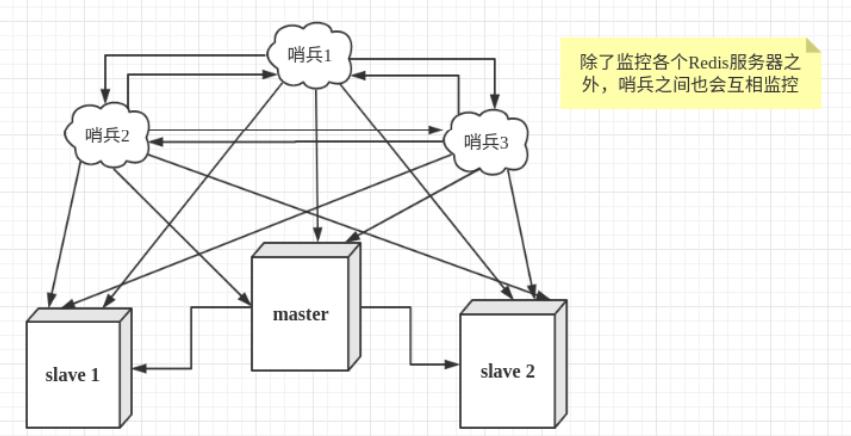
13.哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。我们优先考虑哨兵模式。哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
13.1 作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服 务器,修改配置文件,让它们切换主机
13.2 哨兵集群
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。 各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认 为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一 定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover[故障转移]操作。切换成功后,就会通过
以上是关于Redis学习笔记的主要内容,如果未能解决你的问题,请参考以下文章