全网最火的Nacos监控中心——Prometheus+Grafana
Posted 风清扬逍遥子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全网最火的Nacos监控中心——Prometheus+Grafana相关的知识,希望对你有一定的参考价值。
最近公司在做Nacos监控这块,于是我就随手搭建了一台监控中心,虽然是国外的,但是对于功能上足够用了,下面我来介绍下怎么搭建!!!
1、准备环境
- Nacos集群
- 参考地址:https://nacos.io/zh-cn/docs/monitor-guide.html
- Nacos集群搭建地址:https://nacos.io/zh-cn/docs/deployment.html
Nacos集群我已经搭建好过了,具体想知道怎么搭建的,百度下就有了一大堆的帖子!!Nacos 0.8.0版本完善了监控系统,支持通过暴露metrics数据接入第三方监控系统监控Nacos
运行状态,目前支持prometheus、elastic search和influxdb,下面结合prometheus和grafana如何监控Nacos介绍下搭建过程!!如果你们公司有成本可以自研,那是最好不过的。
2、搭建Nacos集群暴露metrics数据
按照上面的地址,搭建好Nacos集群后,我们要在集群的每个节点中的配置文件application.properties中,暴露metric数据,改完记得要重启Nacos每个节点!!
management.endpoints.web.exposure.include=*访问{ip}:8848/nacos/actuator/prometheus,看是否能访问到metrics数据,我这里直接演示下访问效果:
到这第一步我们就搞定了。
3、搭建prometheus采集Nacos metrics数据
下载你想安装的prometheus版本,地址为:https://prometheus.io/download/
我这里选择的版本是:prometheus-2.27.1.linux-amd64.tar.gz(后面会放在云盘里自己下载就好了)
我是在linux下,windows下我没搞过,其实差不多的。
- 解压prometheus压缩包
tar xvfz prometheus-*.tar.gz cd prometheus-*
- 修改配置文件prometheus.yml采集Nacos metrics数据
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] # nacos cluster 这里开始是新加的 - job_name: 'nacos-cluster' scrape_interval: 60s metrics_path: '/nacos/actuator/prometheus' static_configs: - targets: - ip1:8848 - ip2:8848 - ip3:8848 #标签后面会用到 labels: instance: nacos cluster
- 启动prometheus服务
我这里自己写了个脚本,我需要在后台输出日志和运行
脚本内容:
nohup ./prometheus --config.file="prometheus.yml" >> ./nohup.out 2>&1 &然后启动脚本
sh ./start.sh通过访问http://{ip}:9090/graph可以看到prometheus的采集数据,在搜索栏搜索nacos_monitor可以搜索到Nacos数据说明采集数据成功!
你还可以访问这个地址:http://{ip}:9090/targets,看到如下的美景
此时,说明可以收集到Nacos的metric数据了,但是这个数据我需要有个大盘展示!!
4、搭建grafana图形化展示metrics数据
和prometheus在同一台机器上安装grafana,使用 yum 安装grafana
sudo yum install https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.2.4-1.x86_64.rpm sudo service grafana-server start访问grafana: http://{ip}:3000后的结果是这样的:
账号密码默认是:admin/admin
进去后需要你设置下新的密码,这个你随意好了。
然后正式开始我们的配置操作!
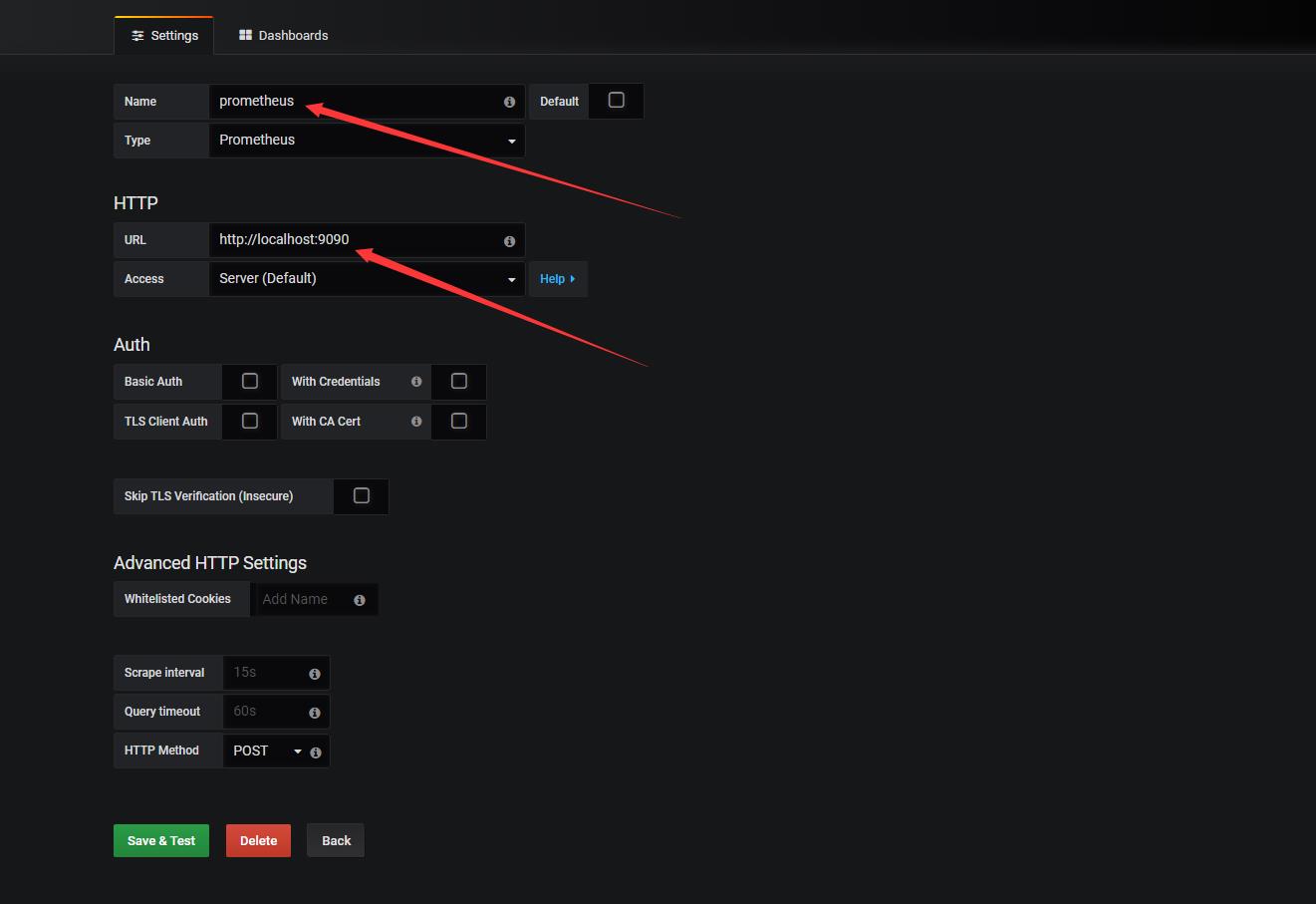
- 配置prometheus数据源
然后你需要记录下本身普罗米修斯(Prometheus)自己的监控。
这个远远不够,目前你只是配置了普罗米修斯本身,但是你的数据来自哪里呢?那么需要再配置一个Nacos的数据源头,将数据采集到Prometheus数据源中!
现在你添加了两个数据源了,点击save保存
- 导入Nacos grafana监控模板
官网这里写的是真的烂,导入什么模板也不讲清楚,我自己摸索了半天,这里导入的模板是来自github的一个json串,我就不展开了,下载地方在这里:
链接:https://pan.baidu.com/s/13w3r5EyKwKSTbvY1bul9Rw 提取码:w7vl下载下来记得解压啊,里面有json文件
点开大屏一看











你会发现没有数据,但是这个时候你要去操作个地方,点击右上角的设置

当然我这里是配好的,点击设置后,点击这里

按照我的图去配置,因为你默认加的label样式,所以这里填写label

然后点击保存就可以!这是最终效果

对于里面的意思,可以参考Nacos官网手册,看下里面的配置意思!
官网地址:https://nacos.io/zh-cn/docs/monitor-guide.html
好了,到此结束,如果过程中有异常,欢迎留言!!
以上是关于全网最火的Nacos监控中心——Prometheus+Grafana的主要内容,如果未能解决你的问题,请参考以下文章