流数据分析技术笔记1 流数据简介
Posted Lora青蛙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流数据分析技术笔记1 流数据简介相关的知识,希望对你有一定的参考价值。
1.1 流数据的来源
大数据
大数据概念:大数据技术描述了一个技术和体系更新的新时代,呗设计与从大规模多样化的数据中通过高素捕获、发现和分析技术提取数据的价值
3V定义:高容量(Volume)、高度变化(Velocity)、多样化(Variety)
传统的数据挖掘方式:抽样的数据、准确的数据建模、精确的处理结果
大数据的挖掘方式:精确性不是目标(从抽样到全样、从精确到非精确、从因果到关联)
流数据来源
数据(data)是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的的原始素材,例如声音、图像、符号、文字等。
很多企业为了支持决策分析而构建的数据仓库系统,其中存放的大量历史数据就是静态数据。技术人员可以利用数据挖掘和OLAP(On-Line Analytical Processing)分析工具从静态数据中找到对企业有价值的信息。
近年来,在Web应用、网络监控、传感监测等领域,兴起了一种新的数据密集型应用——流数据,即数据以大量、快速、时变的流形式持续到达。
流数据的来源多种多样,例如数据移动系统,刚开始是为LinkedIn、Yahoo!和Facebook的网站分析与在线广告处理数据,设计这样的处理系统是为了应对Twitter和LinkedIn这样的社交网络所带来的社交媒体数据处理的挑战;再如在线广告,Google公司的商业帝国与在线广告息息相关,其通过深度学习技术利用超大规模神经网络来学习复杂模式。
通过使物联网以及其他高度分布式的数据采集手段经济可行,这些系统甚至正在开辟数据采集和分析的全新领域。目前主要的流数据来源为:运行监控 Web分析 在线广告 社交媒体 移动数据和物联网。
1.2 流数据的特别之处
流数据与静态数据区别包括很多方面:数据快速持续到达;数据来源众多,格式复杂;数据量大,一旦经过处理,要么被丢弃,要么被归档存储;注重数据的整体价值,不过分关注个别数;数据顺序颠倒,或不完整。其中最为重要的三个方面可以总结如下:
始终在线,持续流动
松散结构
高基数的存储
始终在线,持续流动
数据流是流式的,数据始终可得,新数据不断生成,这为数据分析带来了机遇和挑战,一方面,很少会出现数据不足的情况;另一方面,过去80年间所开发的统计工具多数集中于离散实验,许多标准的分析方法并不一定很适合流式数据。
数据的持续抵达将会导致:实时性、易失性、突发性、无序性
因此,流数据采集和分析系统的设计需满足两点要求:
首先,采集系统本身要有非常好的健壮性;
其次,数据是持续流动的这一事实意味着系统的处理要能够跟得上数据的流动速度。
松散结构
与其他许多数据集相比,流数据经常显得结构松散。部分原因似乎在于流环境下所感兴趣的数据类型,有些数据来源有严格的结构,然而还有许多数据来源包含了任意的数据载荷,更难以应付的是,这些数据是自然语言形式的。另一个原因是流数据项目的“厨房水槽”心态。多数项目非常年轻,探索的是未知的领域,随着时间的推移,这会有所改变,也开始使用容易修改的格式。
数据采集的实时属性还意味着每个维度都可能在任何给定时刻存在或消失。例如,将IP地址转换为地理位置的服务可能临时中断。对于批处理系统,这不会带来什么问题,服务再次上线时就可以重新进行分析。流处理系统则不然,它必须能够处理每一维上的变化,并尽力做到最好。
高基数的存储
基数指的是一部分数据可能的不同取值个数。高基数数据经常具有“长尾”特征:对于一个给定的维度(或维度组合),存在一个包含不同数据状态的小集合,这个小集合十分常见,通常占据所观察数据的绝大部分,其他数据状态只占很小的比例,从而形成一个“长尾”。
批处理环境下,通常可以对数据集进行多遍处理。流处理环境下,数据通常是单遍处理的。流处理环境下对存储空间的要求要比批处理环境下更加严格,因为与批处理环境不同,流处理通常必须使用快速的主存储器,而不是速度缓慢的硬盘这样的第三级存储器。随着高性能固态硬盘(SSD)的出现,这种情况有所缓解,但SSD仍然要比主存储器慢好几个数量级。
流数据的概念
流数据是一种实时到达的具有闺蜜的、基数高、统计特征复杂变化特征的数据流
流数据分析模型:对上述这种有时效性要求的时间序列的数据分析模型,如获取模式或进行频繁项统计、聚类、分类及趋势预测等。
流数据处理:考虑到数据流大规模实时持续到达的特征,考虑到数据基数大的特点,针对流数据的分析可能需要我们接受近似解决的方案(滑动窗口处理)
1.3 基础架构与算法
流计算:实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息。
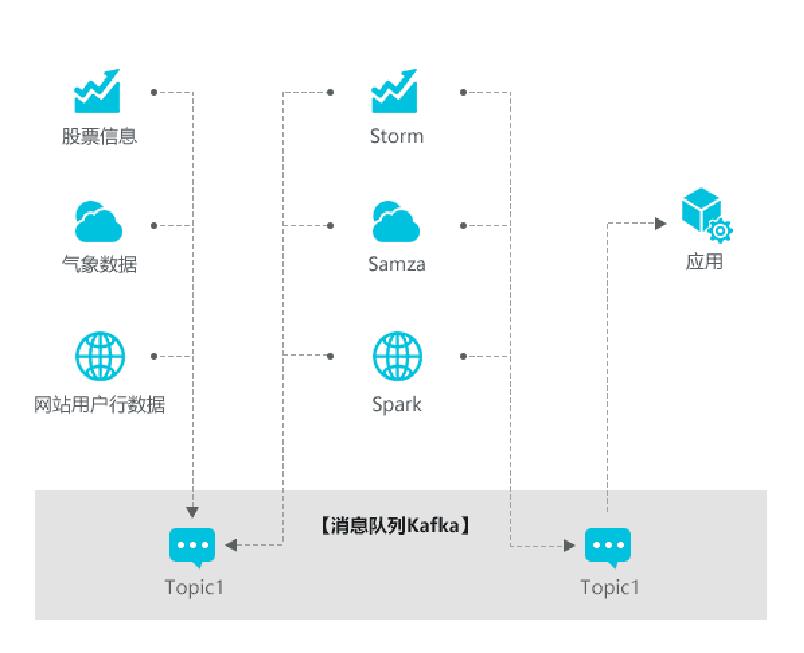
流计算:实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息。
流计算秉持的理念:数据的价值随着时间的流逝而降低
实时流架构设计与构建应满足:高性能、海量式、实时性、分布式、易用性、可靠性。
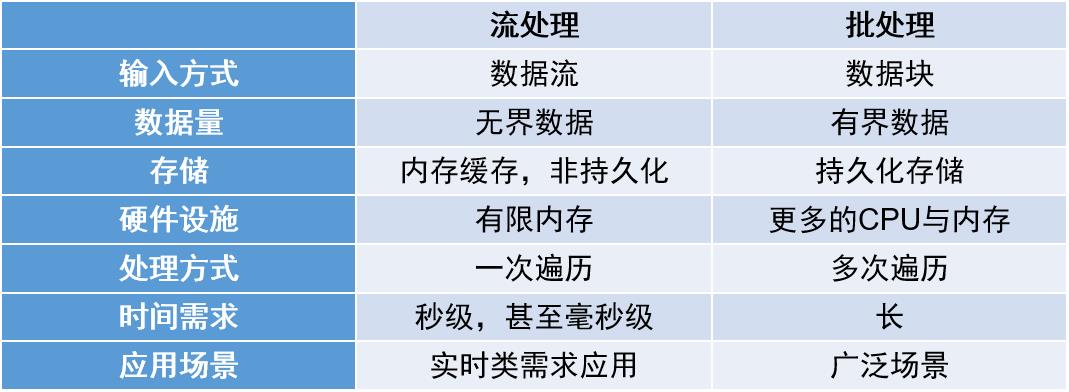
批处理模型:数据先存储,再分析
有界数据:在时间和空间范围上有限的数据
无界数据:在时间和空间范围内趋于无限的数据
流处理模型:数据在线持续处理
窗口模型:固定窗口模型、滑动窗口模型、会话窗口模型
由于流数据具有持续抵达、高基数、统计特征随时间变化等特性,这意味着将数据收全之后再进行数据分析处理是不现实的,也不符合流数据实时计算的需求。
频繁项挖掘算法
频繁项:流数据中指定项目出现的频繁程度
传统算法:Apriori算法、FP-Growth算法,主要针对全量数据或界标类型窗口数据,不能适应流数据的快速变化。
主要挑战:流数据频繁项挖掘算法需要很高的内存效率;需要时间来区分频繁项和不频繁项,频繁项挖掘的实时处理十分困难
常用算法:基于计数的频繁项挖掘、基于抽样的频繁项挖掘、基于草图的频繁项挖掘
聚类算法
聚类分析:把数据按照一定的规则分为几个簇,使得簇内对象具有较高相似度,簇间对象具有较高相异度。
传统算法:K-Means算法、K-Medoids算法,要对数据进行多次遍历和计算,不能适应流数据环境下的聚类分析。
主要挑战:流数据的聚类处理过程必须是增量式,聚类算法必须根据有限的缓存数据和已有的聚类挖掘结果进行聚类中心的更新;离群点的影响。
常用算法:基于划分的聚类方法、基于层次的聚类方法、基于密度的聚类方法、基于网格的聚类方法
分类算法
分类:学习一个分类函数或分类模型,并使用该函数或模型将数据映射到指定类别中的某个类别上;与聚类放啊不同,分类方法并不关心分类后的同类数据项之间是否有相似度,而仅关心被分类的数据项与分类类别的相似性
主要挑战:多数传统分类模型的训练需要先标注数据项的分类;若不希望预先标注数据,而直接从数据中学习并构建模型,会面临流数据持续抵达特性带来的问题;分类器是否能够具有持续更新的能力;一些基于距离的分类算法仅能在一些数据量相对不大、实时性要求不高的场景下使用
常用算法:基于距离的分类方法、基于决策树的分类方法、贝叶斯分类方法
流数据分类性能评价:
传统:将数据随机划分为训练集、评估记、测试集
流数据:固定式、交错式
回归算法
回归:目标是学习一个函数或模型,使该函数或模型能够估计一个或多个自变量与因变量之间的关系,检验这些关系的可信程度,判断自变量是否存在影响,并估计未知参数的取值。本质是使用一个函数或模型对输入样本进行“拟合”
回归、聚类、分类的差异:
目标差异:聚类目标是对已知数据的分布特征规律进行挖掘以获得不同集合;分类强调根据挖掘出的特征规律对新到达数据的归属集合进行判定;回归强调通过学习到的特征规律,或预测未来数据的分布位置(线性回归),或预测未来数据的二分类分布规律(逻辑回归)
特征规律差异:聚类强调类内对象的高相似度和类间对象的高相异度;分类强调类间的区分度及目标对象与类的相似度;回归强调对数据的分布特征函数的拟合。
回归算法分类:参数回归(如线性回归)、非参数回归(如k近邻回归、核回归、局部加权线性回归)、逻辑回归
主要挑战:流数据的持续抵达特性导致流数据的回归处理过程也必须是增量是;离群点的影响;回归同样面临流数据的统计特征变化特征的影响。
常用算法:参数型回归中的线性回归、非参数型回归中的k均值回归、逻辑回归。
以上是关于流数据分析技术笔记1 流数据简介的主要内容,如果未能解决你的问题,请参考以下文章