流数据分析技术笔记5 分布式实时处理系统
Posted Lora青蛙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流数据分析技术笔记5 分布式实时处理系统相关的知识,希望对你有一定的参考价值。
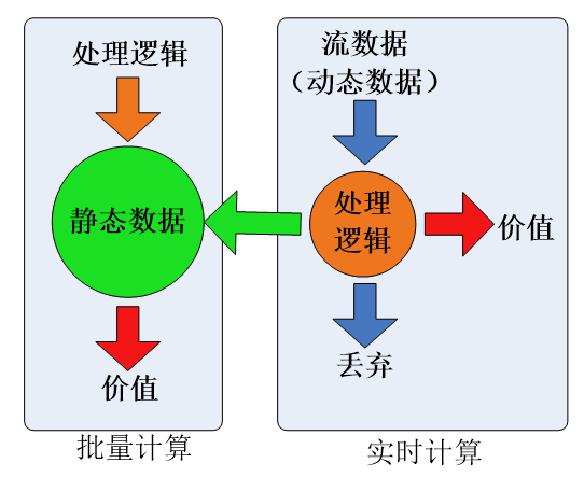
1 分布式流数据处理概述
流处理本质上是一种特殊形式的并行计算,它被设计用于数据只能处理一次的情况。这些并行计算环境多数实现在一个不可靠的网络层之上,这样的网络层会引入高得多的错误率。
• 协调:流框架的核心,存储用于拓扑处理的相关信息,同时处理一些分区任务,Zookeeper。
• 分区和融合:流处理系统的核心元素是分散-收集(scatter-gather)机制的某种实现,流处理应用的各种组件之间的数据交换通常是点对点形式。一个组件知道它必须生成数据供别的组件消费,多数系统会建立 处理单元间的数据传送机制,并在计算的每个阶段控制并行度。
• 事务:实时框架中事务处理的基本机制是回滚和重试,事务的维护会给系统带来巨大开销。如果没有事务也可以运行,那就不要用事务。
对于一个流计算系统来说,它应达到如下需求:
• 高性能:处理大数据的基本要求,如每秒处理几十万条数据
• 海量式:支持TB级甚至是PB级的数据规模
• 实时性:保证较低的延迟时间,达到秒级别,甚至是毫秒级别
• 分布式:支持大数据的基本架构,必须能够平滑扩展
• 易用性:能够快速进行开发和部署
• 可靠性:能可靠地处理流数据。
2 Storm分布式实时处理系统
Map reduce框架:主节点job tracker,从节点task tracker,用户提交任务给job tracker,job tracker分配给task Tracker,我们管这些任务叫job,运行的作业分为两种map 和reduce。
Storm:一个实时计算框架主节点 nimbus 从节点 supervisor用户提交作业给nimbus,nimbus把任务分配给supervisor,这些提交的任务就是topology(拓扑)运行的作业分为两种spout和bolt。Storm是流式的处理既stream,stream的内容是tuple(元组)

“经典”Storm:将应用构造为名为拓扑(topology)的有向无环图(Directed Acyclic Graph,DAG)。
Trident(推荐):是对拓扑的高层次抽象,该模型更聚焦于聚集和持久化这些常见操作
Storm组件
Storm集群由三个服务器守护进程组成,分别是ZooKeeper、nimbus和supervisor,这三个进程都必须正常运行。
ZooKeeper:分布式Storm集群依靠ZooKeeper进行协调,跟踪所有运行着的拓扑,以及所有supervisor的状态;
nimbus:首要组件,负责向集群中的worker分配spout或bolt的任务,在supervisor发生故障时使Storm集群重新平衡;
supervisor:运行于每个worker节点之上的服务器, 负责管理本地任务的运行,每个本地任务可能是一个spout或一个bolt,每个supervisor都可能控制许 多本地任务的运行。
Topology:Storm提交运行的程序, 由Spout和Bolt构成;
Spout:Storm认为每个Stream都有一个源头 , 并把这个源头抽象为Spout; Bolt:在一个Topology中接收数据后 然后执行处理的组件;
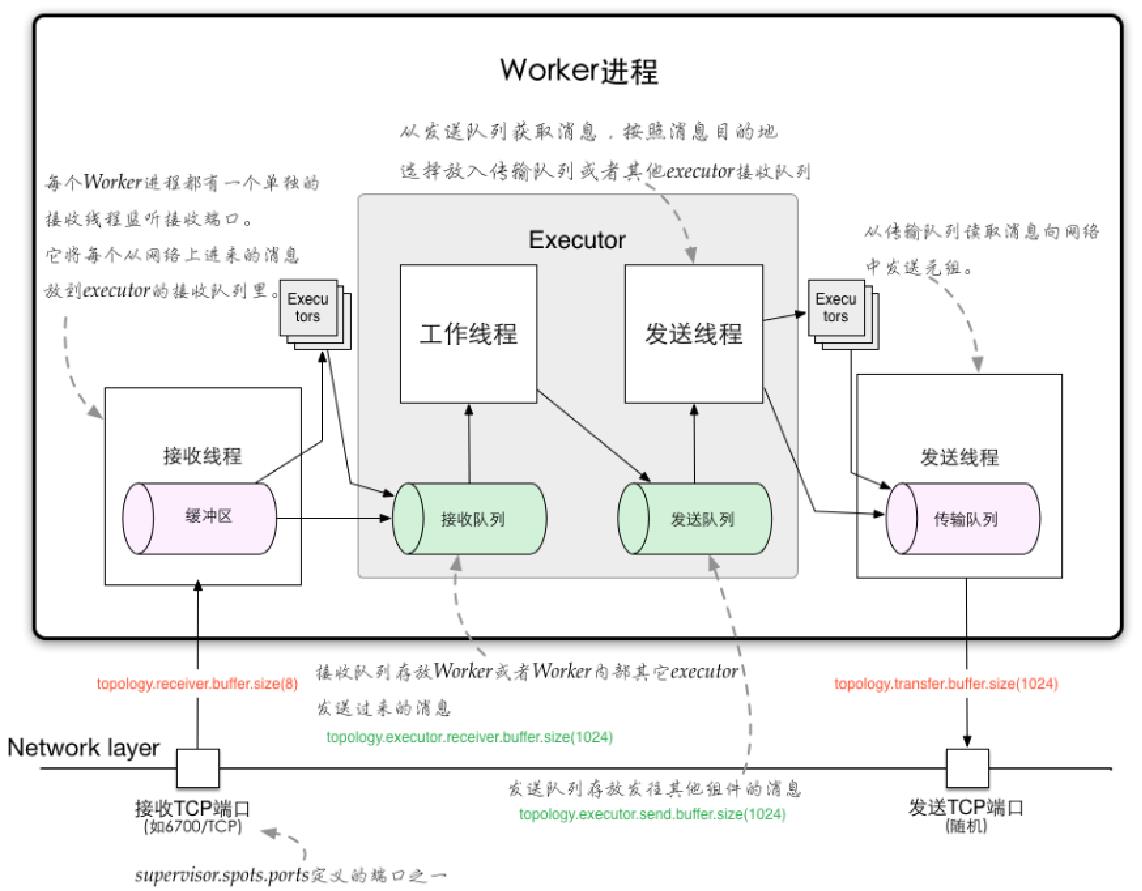
Task:Worker中每一个Spout/Bolt 的线程称为一个Task;
Workers:Topology运行时的物理进 程。每个Worker是一个JVM进程。
Storm是流式的处理既stream,stream的内容是tuple(元组)
Spout生产tuple(元组)发送给bolt处理,bolt处理过的tuple也可以再次发送给其他的tuple处理,最后存入容器。
Storm拓扑
拓扑是Storm的计算组织机制,它是用有向无环图(DAG)来表示的,数据只能沿着边单向流动。如下图,包括一层输入spout和两层bolt。为了保持性能,Storm可以根据需要增加blot的并行性
spout: Strom的数据输入机制。
bolt: Storm的基本计算单元
Topology处理流程:一个Topology的Spout/Bolt对应的多个Task可能分布在多个Supervisor的多个Worker内部;每个Worker内部又存在多个Executor,根据实际对Topology的配置在运行时进行计算并分配。
Storm bolt
bolt从拓扑中的其他bolt或spout接收数据,bolt的实现通过继承BaseBasicBolt或BaseRichBolt类来实现。它们是由事件驱动的,因此不能用来提取数据,提取数据由spout负责。
分布式远程过程调用
Storm具备实现分布式远程过程调用(Distributed Remote Procedure Call,DRPC)的功能,用于简单地实现分布式处理服务,例如进行大量昂贵的计算。通过使用spout和bolt的特殊组合,这些拓扑就能实现跨多台机器运行的复杂过程。
3 Samza分布式实时处理系统
Yarm的特征:速度超快、超级安全、超级可靠
Samza特征:简单API、管理状态、容错、耐久性、可扩展性、可插拔、处理器隔离
Samza 由三层组成:
1)流媒体层:Kafka;2)一个执行层:YARN;3)处理层:Samza API。
Samza提供了一个YARN ApplicationMaster 和一个YARN 作业运行器开箱即用,Samza和YARN 的集成如下(不同的颜色表示不同的主机):
YARN有三个重要的部分:一个资源管理器ResourceManager、一个NodeManager 、一个ApplicationMaster。在一个YARN grid中,每个机器运行着一个 NodeManager,NodeManager负责在这台机器上启动进程。ResourceManager告诉所有NodeManager它们应该运行什么。当应用程序想要在集群上运行的时候,它会与ResourceManager来对话。ApplicationMaster,实际上是一段应用程序指定的运行在YARN集群上的代码,它负责管理应用程序的工作负荷,请求获取container(通常是UNIX进程 ),以及当container出现故障时处理通知。
Samza使用YARN和Kafka为逐级流处理和分区提供了一个框架。Samza客户端使用YARN运行Samza工作:YARN启动并监督一个或多个SamzaContainers,处理代码(使用StreamTask API)在这些容器内运行。Samza StreamTasks的输入和输出来自Kafka代理(通常)位于与YARN NMs相同的计算机上。
Samza的高级概念——流
Samza 处理流。流由相似类型或类别的不可变消息组成。流可以具有任何数量的消费者,并且从流读取不会删除消息(因此每个消息被有效地广播给所有消费者)。消息可以可选地具有用于分区的关联密钥。
Samza支持实现流抽象的可插拔系统:在Kafka中,一个流是一个主题,在数据库中,可以通过在 Hadoop中消耗更新来读取流,可能会拖放HDFS中的文件目录。
Samza的高级概念——分区
Samza作业是对一组输入流执行逻辑变换以将输出消息附加到输出流集合的代码。
为了缩小流处理器的吞吐量,将流和作业分解成更小的并行单元:分区和任务。
每个流被分解成一个或多个分区。流中的每个分区是完全有序的消息序列。该序列中的每个消息都有一个称为偏移量的标识符,每个分区是唯一的。取决于底层的系统实现,偏移量可以是顺序整数,字节偏移量或字符串。
Samza的高级概念——任务
通过将作业分解成多个任务来缩放作业。该任务是任务并行的单位,就像分区到流。每个任务从每个作业的输入流的一个分区中消耗数据。
Samza核心
SamzaContainer:负责管理一个或多个StreamTask 实例的启动,执行和关闭。每个SamzaContainer通常作 为一个独立的Java虚拟机运行。Samza工作可以由几个可能运行在不同机器上的SamzaContainers组成。
序列化:从数据流或持久状态存储器读取或写入的每个消息都需要最终序列化为字节(通过网络发送或写入磁盘)。有不同的地方可以发生序列化和反序列化:
在客户端库中:例如,发布到 Kafka 并从 Kafka 消费的库支持可插拔序列化。
在任务实现中:进程方法可以使用原始字节数组作为输入和输出,并进行任何解析和序列化本身。
两者之间:Samza 提供串行解串器,或构成的层 SERDES 的简称。
定期检查 提供流的容错处理:Samza保证消息不会丢失,即使工作崩溃,如果机器死机,如果有网络故障或其他问题。为了提供这一保证,Samza 希望输入系统满足以下要求:
流可以划分成一个或多个分区。每个分区独立于其他分区,并且跨多台计算机进行复制。
每个分区由固定顺序的消息序列组成。每个消息都有一个偏移量,表示其在该顺序中的位置。消息总是在每个分区内依次消耗。
Samza 作业可以从任何起始偏移开始消耗消息序列。
状态管理:常用的状态处理用例:
窗口聚合:计算每个用户每小时的页面浏览量;
表表连接:通过user_id 将用户配置文件表加入到用户设置表中,并发出连接的流;
流表连接:使用用户的邮政编码来增加一个页面视图流(可能允许在后期通过邮政编码进行聚合);
流流连接:将广告点击次数加入到广告展示流中(将广告展示时间的信息链接到点击的信息)。
如何支持这种状态处理呢?
带检查点的内存状态:在一些流处理系统中常见的一种简单方法是定期将任务的整体内存数据保存到持久存储中;Remote State 用于状态处理的另一种常见模式是将状态存储在外部数据库或键值存储中。传统的数据库复制可用于使数据库容错;Local State 状态存储在磁盘上,所以作业可以保持比适合内存更多的状态。它存储在与处理任务相同的机器上,以避免通过网络进行数据库查询的性能问题。
Samza与Storm
Storm 和 Samza 非常相似。两个系统提供了许多相同的高级功能:分区流模型,分布式执行环境,流处理 API,容错,Kafka集成等。Storm 和 Samza 对于类似的概念使用不同的单词:Storm中的Spout类似于Samza 中的流消费者,Bolt类似于任务,元组类似Samza中的消息。一些额外的构建块,如Trident,Topology等,在Samza 中没有直接的等价物。
4 Flink分布式实时处理系统
Flink 将批处理视作一种特殊的流处理,其核心计算构造是Flink Runtime执行引擎,它是一个分布式系统,能够接受数据流程序并在一台或多台机器上以容错方式执行,可以作为YARN的应用程序在集群上运行,也可以在Mesos集群上运行,还可以在单机上运行。
Flink结构
Deployment层:涉及了Flink的部署模式,Flink支持多种部署模式:本 地、集群(Standalone/YARN),(GCE/EC2)。
Runtime层:提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层:主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层:可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于 Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)
Flink程序与数据流
Flink程序是由Stream和Transformation两个基 本构建块组成,其中Stream是一个中间结果数据,Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
并行数据流:在Flink中,程序天生是并行和分布式的:一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask,每一个Operator Subtask是在不同的线程中独立执行的。一个Operator的并行度,等于Operator Subtask的个数,一个Stream的并行度总是等于生成它的Operator的并行度。
Flink窗口
流处理中的聚合操作(counts,sums等等)不同于批处理,因为数据流是无限,无法在其上应用聚合,所以通过限定窗口(window)的范围,来进行流的聚合操作。
窗口可以由时间驱动 (every 30 seconds) 或者数据驱动(every 100 elements)。如:滚动窗口tumbling windows(无叠加);滑动窗口sliding windows(有叠加);会话窗口session windows(被无事件活动的间隔隔开)
Flink时间
事件时间 Event Time:事件的创建时间,通常通过时间中的一个时间戳来描述
摄入时间 Ingestion time:事件进入Flink 数据流的source的时间
处理时间 Processing Time: Processing Time表示某个Operator对事件进行处理时的本地系统时间(在 TaskManager节点上)
Flink分布式运行
Flink的分布式执行主要分成两个重要进程:master和worker。当一个Flink程序执行时,其有多个进程参与该执行过程,如:
• Job Manager: 就是masters,协调分布式任务的执行。用来调度任务,协调checkpoints,协调错误恢复等等。至少需要一个JobManager,高可用的系统会有多个,一个leader,其他是standby
• Task Manager: 也就是workers,用来执行数据流任务或者子任务,缓存和交互数据流。至少需要一个 TaskManager;
• Job Client: Client不是运行是和程序执行的一部分,它是用来准备和提交数据流到JobManager。之后,可以断开连接或者保持连接以获取任务状态信息
以上是关于流数据分析技术笔记5 分布式实时处理系统的主要内容,如果未能解决你的问题,请参考以下文章