对Redis Cluster的理解
Posted jfcat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对Redis Cluster的理解相关的知识,希望对你有一定的参考价值。
Redis Cluster的结构
Cluster结构存在几个部分
- Hash Slot
- Node
- Master-Slave
整体看下图,具体的后面讲
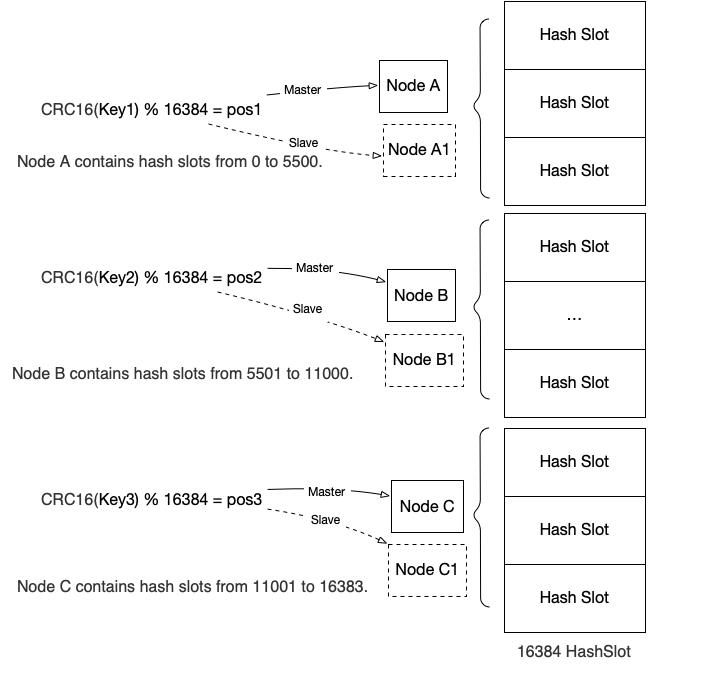
Redis Cluster的数据划分
- 每个Redis集群被划分为16384个Hash Slot
- 每个Key经过CRC16计算,然后模上16384的结果对应到具体的slot
- 每个Redis Cluster的节点负责部分的集群的Hash Slot
节点的添加和删除只需要对相应的槽位进行移动管理就可以,比如要添加D,就将槽位再分配,将A,B,C的槽位部分移动到D就可以。
Key归属槽位有个特殊情况,就是一个命令(事务 or Lua脚本)带多个key,可以被设置为一个一致的槽位,这个技术叫hash tags.
Redis Cluster解决Node失败问题
由于节点A,B,C的结构,存在的单点故障问题,导致如果A失败,A对应的Hash Slot不能访问问题,Redis 集群使用Master-Slave模式,每个槽位可以对应1-N个slave节点。
例如上图中展示的A B C为Master节点, A1 B1 C1展示的为Slave节点,当Master A无法访问时,A1将被选出作为新的Master节点。但是如果A1 和A同时不能访问,Redis集群将无法解决。
Redis Cluster强一致性问题
Redis Cluster无法解决强一致问题,一个原因是由于Redis Cluster使用异步复制,通常数据写入情况如下:
- Client1 请求Master A写入Key=1
- Master A 确认写入返回Client1 写入成功
- Master A同步结果给Slave A1
如果此时MasterA在同步结果前先挂掉了,然后集群选取A1为Master,那么就无法再找回丢弃的数据。如果要解决这问题必须Master A先同步数据给Slave再返回给Client成功,但是这样会导致性能问题。
这事一个数据一致性和性能之间的取舍问题。
Redis Cluster支持同步写操作,可以通过WAIT命令来实现,但是这只能带来更少的数据丢失可能,通用还是存在其他更复杂的情况。
借鉴Redis官方文档的例子:
A,B,C,A1,B1,C1 组成的Redis CLuster,不带1的位Master,其他为Slave,然后有个Z1的client。某个时刻由于网络故障,B和Z1被划分到一个partition,然后无法与A,C,A1,B1,C1等通信,这时Z1还可以写数据到B,等网络恢复的时候B1已经被选为了新的Master,B重新连到Redis Cluster,然后被设置为Slave,期间Z1写的数据就会丢失。
引用:
https://redis.io/topics/cluster-tutorial
以上是关于对Redis Cluster的理解的主要内容,如果未能解决你的问题,请参考以下文章