Linux 容器化技术详解(虚拟化容器化Docker)
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 容器化技术详解(虚拟化容器化Docker)相关的知识,希望对你有一定的参考价值。
虚拟化是过去用来充分利用物理资源的最常用方法。早年间,我们可以用一台服务器运行一个操作系统,处理一个任务,带来的问题是资源利用率极其不足,计算机的潜能并不能完全发挥,而后多道批处理系统、分时系统相继出现,Unix、Linux 等操作系统成为了人类 “压榨” 计算机物理资源的神兵利器,而此时,虚拟化技术却并未崭露头角。
目光聚焦到 20 世纪的 90 年代,当时 IT 行业逐渐步入工业化,大量公司部署起了自己内部的 IT 环境,他们使用了多个不同供应商提供的价格相对低廉的服务器、操作系统和应用程序,此时就暴露出了一个严重的问题:大多数企业使用的都是物理服务器或者由单家供应商提供的应用,每台服务器又只能运行一个供应商特定的任务,不同供应商之间硬件也并不兼容,如果这时候再各自为他们配备不同的硬件设备必然也会面临物理硬件利用率不足的问题。此时虚拟化技术才得以大展身手,它主要解决了 可对服务器分区 、 可在同一个主机上运行不同环境的应用 两个主要的问题。
自此,服务器开始得到更高效利用,也降低了企业采购、设置、散热和维护的成本。虚拟化的广泛应用也有助于减少企业对单家供应商的依赖,并为后来云计算的发展奠定了基础。
虚拟化的工作原理
虚拟化技术的实现主要依托于 Hypervisor (虚拟机监控程序) 。它处于计算机物理层与虚拟机之间,能够有效地管理计算机的物理资源并将这些资源分配给不同虚拟环境。作为软件,Hypervisor 可以直接运行在操作系统之上;作为服务器,它也可以直接安装在硬件上,这就是大多数企业使用虚拟化的方式。
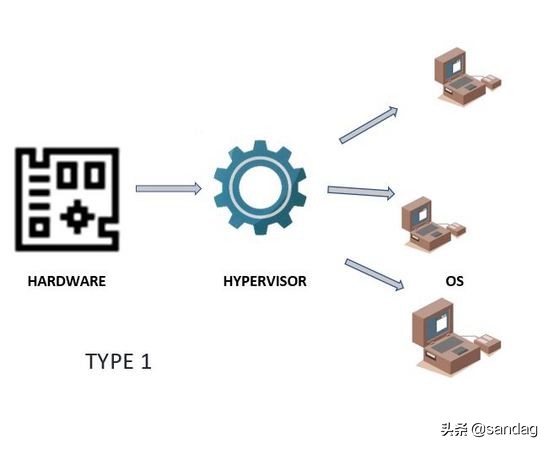
此时,Hypervisor 直接接管物理资源,可以对它们做分区处理,分配给了多个虚拟机使用,而用户在虚拟机中也可以通过它直接和计算机底层交互。当虚拟机运行时,如果用户的程序发出一条硬件指令请求资源,Hypervisor 就会直接将请求传递到物理系统做缓存更改,所有这些操作速度都和本机运行速度几近相同,这种直接运行在物理硬件中的 Hypervisor 即为我们经常听说的 Type1 ,也称为裸机管理程序(Metal Hypervisor),目前市面上常用的 VMware ESXi、MiscroSoft Hyper-V 和 KVM(Kernel-based Virtual Machine)都基于这类 Hypervisor。
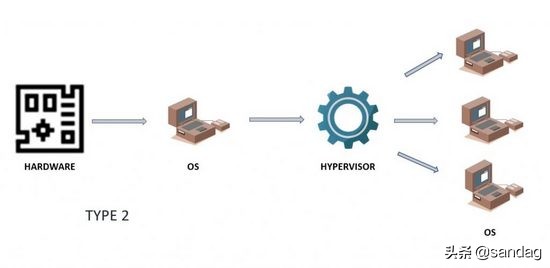
而另一种运行于操作系统之上的 Hypervisor 即为 Type2 ,这种命名方式非常简单粗暴,让人很难忘记,它的处理方式就是使 Hypervisor 不直接与物理层基础,因此也称作托管程序(Hosted Hypervisor),它主要用于面向个体用户,我们经常在本机中安装的 Virtual Box、VMware WorkStation 就属于这种类型。此时,相较于 Type1 ,Type2 显然多了一些延迟。
这样,每个虚拟机在 Hypervisor 之上相互独立,运行不同的操作系统,操作不同的物理资源,这也带来了我们期望了灵活性和可移植性,我们可以将一个虚拟机从一个 Hypervisor 中直接迁移到一个新的 Hypervisor 中,此时就达到了一种 环境复用 的效果。
虚拟化技术应用
虚拟化发展之初主要用于服务器虚拟化,但随着这种方式逐渐普及,也衍生出了许多诸如网络虚拟化,应用程序虚拟化,数据虚拟化以及存储虚拟化等技术。本篇文章就不对他们再做一一介绍了,感兴趣的读者可以查阅底部衍生查阅中的相关资料。
容器化技术
此时,既然虚拟化技术日趋成熟,我们就可以投入生产将它运用起来了,如果希望将自己开发的一个 NodeJs 程序放入虚拟机中,就需要在宿主系统中基于 Hypervisor 安装一个 Linux 虚拟机(单独安装 Linux OS),并在 Linux 中为该服务配置一个完整的 JS 应用运行环境和必要的库,如图所示。
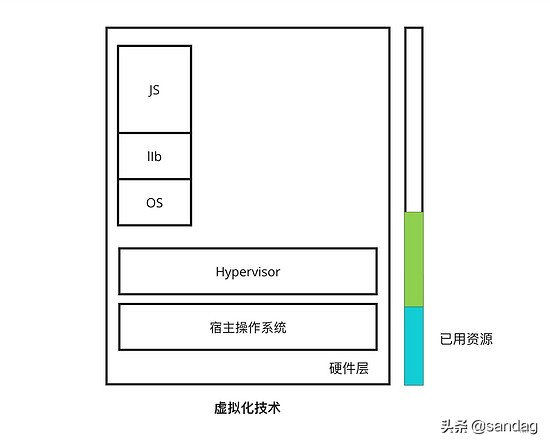
这样做带来的问题也明显,NodeJS 运行时需要的资源可能非常少(10M),而虚拟机本身却占有相当多的资源(>400M),如果继续在该服务器中放入更多的服务,资源消耗程度可见一般,服务器迅速过载。
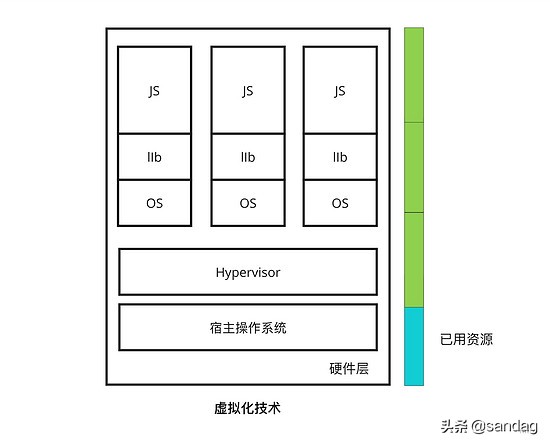
从这方面来看,虚拟化技术虽然做到了在同一宿主系统提供不同的任务,解决了硬件层面的硬件资源共享问题,但在应用上层的资源消耗却仍是一个非常大的问题。同时,在日常开发中,如果我们使用的是自己的个人电脑像 Macbook 开发应用程序时推入服务端也可能存在其他兼容性问题,通常是我的应用程序在本地运行良好,投入生产环境后却病态百出,不利于 DevOps、持续集成和交付。
容器化通过将应用程序代码和运行所需的相关配置文件,库和依赖项捆绑起来解决了上面描述的两个问题。此时,应用程序和其他依赖项俨然成为了一个整体打包在一个文件中,而运行这个文件就会生成一个虚拟容器,程序在这个虚拟容器里运行,就好像在真实的物理机上运行一样。有了容器,就不用担心环境问题。另外,如下图所示,容器也不会捆绑应用环境所依赖的操作系统,轻量级不言而喻。
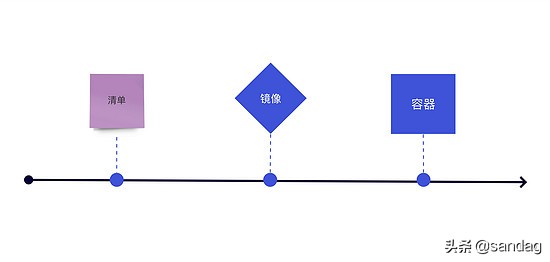
要达到应用程序容器化通常只需三步,首先,定义一个清单文件(如 Docker 中的 Dockerfile 或者 Cloud Fundary 中的 yaml 文件),然后,创建一个镜像文件(如 Docker Image 或者 Rocket 的 ACI),最后生成容器即可,这里就包含了应用运行时所有需要的库、二进制文件等等,在上面的例子中,我们同样可以通过该种方式获得 NodeJS 程序的容器并将放入宿主系统中。
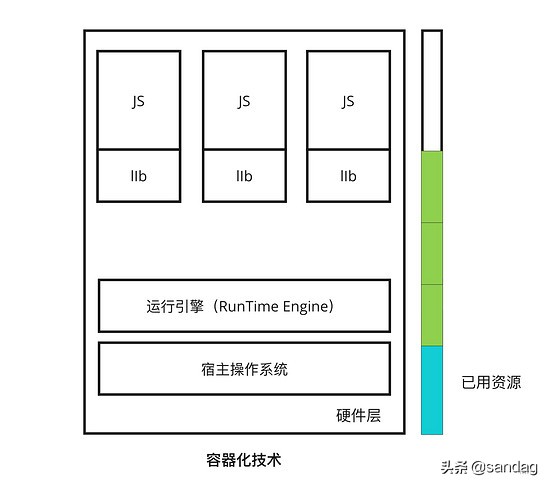
此时,容器化技术也可以摒弃冗余的资源消耗,实现更加轻量级的环境部署。另外,再考虑一个问题,如果在我们的 Nodejs 应用中还需要应用其他环境的库,如需要 python 应用做图像识别、java 应用做数据处理,那么,如果使用虚拟化技术,为了达到云原生的方式就必须在之前的宿主主机中释放出一些资源,然后再将 python 等应用部署进去,而当使用容器化技术时只需要在原服务器中放入一个 python 应用的副本,然后利用剩余的空闲资源做容器之间的共存,这正是容器化技术的伟大之处,它可以实现 容器间隔离的同时做到 CPU 资源共享 。
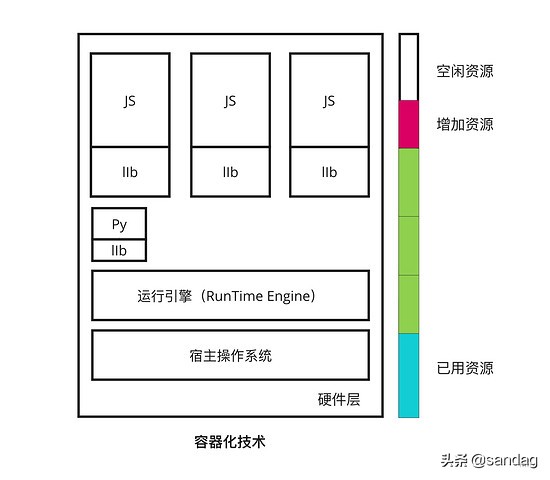
此时,容器引擎(如 Docker 引擎)安装在宿主系统中可以成为所有容器共享同一操作系统资源的渠道。
Linux 容器是我们开发、部署和管理应用方式的又一次飞跃。Linux 容器镜像提供了可移植性和版本控制,确保能够在开发人员的笔记本电脑上运行的应用,同样也能在生产环境中正常运行。相较于虚拟机,Linux 容器在运行时所占用的资源更少,使用的是标准接口(启动、停止、环境变量等),并会与应用隔离开;此外,作为(包含多个容器)大型应用的一部分时更加易于管理,而且这些多容器应用可以跨多个云环境进行编排。
容器化技术应用
容器变得越来越重要,尤其是在云环境中。许多企业甚至在考虑将容器替代 VM 作为其应用程序和工作负载的通用计算平台。但是在如此广泛的范围内,与容器特别相关的关键用例如下:
- 微服务:容器小巧轻便,非常适合微服务体系结构,在微体系结构中,应用程序可以由许多松散耦合且可独立部署的较小服务构成。
- DevOps:微服务作为架构和容器作为平台的结合,是许多团队将 DevOps 视为构建,交付和运行软件的方式的共同基础。
- 混合,多云:由于容器可以在笔记本电脑,本地和云环境中的任何地方连续运行,因此它们是混合云和多云方案的理想基础架构,在这种情况下,组织发现自己跨多个公共云运行与自己的数据中心结合。 应用程序现代化和迁移:使应用程序现代化的最常见方法之一是将它们容器化,以便可以将它们迁移到云中。
容器化技术规范化
随着容器化技术的不断发展,对容器技术和打包软件代码方法的标准化需求也逐渐显现出来,2015 年 6 月,Docker 和其他行业推动者成立了开放容器计划(OCI),目的就是为了促进容器技术的通用,轻量,开放标准和规范,用户也将不会被特定厂商的技术所束缚,而可以利用 OCI 认证的技术,这些技术使用户能够使用多种 DevOps 工具构建容器化的应用程序,并在基础架构上以一致地标准流程运行这些应用程序。
目前,Docker 是应用最广泛的容器引擎技术之一,但它也并不是我们唯一的选择,社区也正在对容器化和其他替代方案(例如 CoreOS rkt,Mesos Containerizer,LXC Linux 容器,OpenVZ和crio-d)进行标准化。虽然他们现在的功能和默认设置可能会有所不同,但是随着规范化的不断发展,利用 OCI 规范将能确保解决方案与特定供应商无关,可以完全在多种环境中使用运行。
Docker
Docker 技术使用的是 Linux 内核和内核功能(例如 Cgroups 和 namespaces)来分隔进程,达到各进程相互独立运行。这种独立性正是采用容器的目的所在;它可以独立运行多种进程、多个应用,更加充分地发挥基础设施的作用,同时保持各个独立系统的安全性。
此外。Docker 技术与传统的 Linux 容器并不完全相同,最初它是基于 LXC (LinuX Containers,Linux 容器) 技术构建(大多数人都会将这一技术与上面介绍的“传统的” Linux 容器联系在一起),但后来它逐渐摆脱了对这种技术的依赖。与虚拟化相比较,LXC 却是独占鳌头,但它并不能提供优秀用户体验,除了运行容器之外,Docker 技术也具备其他多项功能,包括简化用于构建容器、传输镜像以及控制镜像版本的流程等等。
传统的 Linux 容器使用 init 系统来管理多种进程,这表明所有应用都作为一个整体运行,而 Docker 技术正与此相反,它力争让应用各自独立运行在进程中,并提供相应工具,帮助实现这一功能。这种精细化运作模式自有其优势。
Docker 实战
Docker 在各平台安装请参考 官方文档 ,安装之后终端执行下面这条命令可以验证是否安装成功:
$ docker version
Docker 把应用程序及其依赖都打包在 image 文件里面,通过这个文件就能生成 Docker 容器。执行下面这条指令可以列出本机的所有 image 文件:
$ docker image ls
如果是第一次运行 Docker,可以执行下面这条命令启动一个 nginx 服务器测试:
$ docker run -d -p 80:80 --name myserver nginx
这条命令执行完之后,由于这是第一次运行,并且 nginx 镜像还没有下载到本地,因此 Docker 会自动从 Docker Hub 库中拉去该镜像,如果命令成功完成,此时在本地访问 http:// localhost 后就可以查看新服务器的主页了。下面我来以使用 Docker 安装 Hadoop 环境演示 Docker 具体使用的方法。
要将 Hadoop 安装在 Docker 容器中,首先就需要一个 Hadoop Docker 镜像,要想生成镜像,我们可以使用 Github 中的 docker-hadoop 镜像库,执行如下命令拉取该仓库中的代码:
$ git clone https://github.com/big-data-europe/docker-hadoop.git
docker-hadoop 镜像中就含有生成镜像的清单文件 Makefile,此时,执行下面这条命令:
$ docker-compose up -d
docker-Compose 可以用来同时安装多个容器。 -d 参数用于告诉 docker-compos e 在后台运行命令并返回命令提示符。 仅使用上面的一条命令,就可以设置一个 Hadoop 集群了。
如果镜像在本地不可用,docker-Compose 也会尝试从 docker-hub 库中拉去远程镜像,构建镜像并启动容器。 完成后,就可以使用以下命令来检查当前正在运行的容器了:
$ docker image ls
进入 http:// localhost:9870 就可以从名称节点查看系统的当前状态了。
当然,除了使用这种方法使用别人在 docker-hub 或者 Github 开源的镜像,我们也可以自定义镜像,这种方式本篇文章先不做讨论。本篇到这里先结束了,看完后关于虚拟化和容器的概念你是不是都掌握了?大家有任何问题可直接联系我,也可在博客评论区讨论。
以上是关于Linux 容器化技术详解(虚拟化容器化Docker)的主要内容,如果未能解决你的问题,请参考以下文章