MYSQL DB_CACHE
Posted 海鲨数据库架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MYSQL DB_CACHE相关的知识,希望对你有一定的参考价值。
mysql作为一个存储系统,具有缓冲池(buffer pool)机制,以避免每次查询数据都进行磁盘IO。
As a storage system, MySQL has a buffer pool mechanism to avoid disk IO for every query data
缓存池的结构
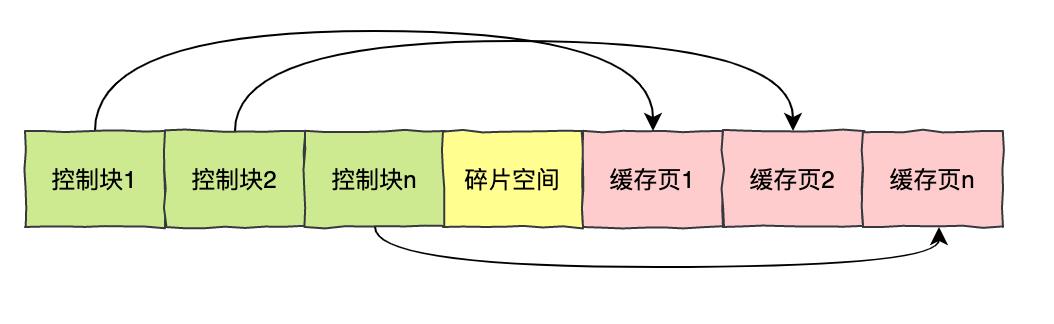
Buffer Pool 是一片连续的内存空间,innodb 存储引擎是通过页的方式对这块内存进行管理的。
可以看到缓存池中包括数据页、索引页、插入缓存、自适应哈希索引、锁信息、数据字段。其中数据页和索引页会用掉多数内存。
You can see that the cache pool includes data pages, index pages, insert cache, adaptive hash index, lock information, and data fields. The data page and index page will use up most of the memory.
但是,innodb 是如何管理缓存池中的这么多页呢?
为了更好的管理这些缓存的页,innodb 为每一个缓存页都创建了一些所谓的控制信息.
In order to better manage these cached pages, InnoDB creates some so-called control information for each cached page
这些控制信息包括该页所属的:
-
表空间编号(sapce id) -
页号(page numeber) -
页在 buffer Pool 的地址 -
一些锁信息以及 LSN 信息日志序列号 -
其他控制信息
每个缓存页对应的控制信息占用的内存大小是相同的,我们把每个页对应的控制信息占用的一块内存称为一个控制块。
The size of the memory occupied by the control information corresponding to each cache page is the same. We call the memory occupied by the control information corresponding to each page a control block.
控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 的后边。
The control block and the cache page are one-to-one correspondence. They are all stored in the buffer pool, in which the control block is stored in the front of the buffer pool and the cache page is stored in the back of the buffer pool.
Buffer Pool 对应的内存空间示意图:
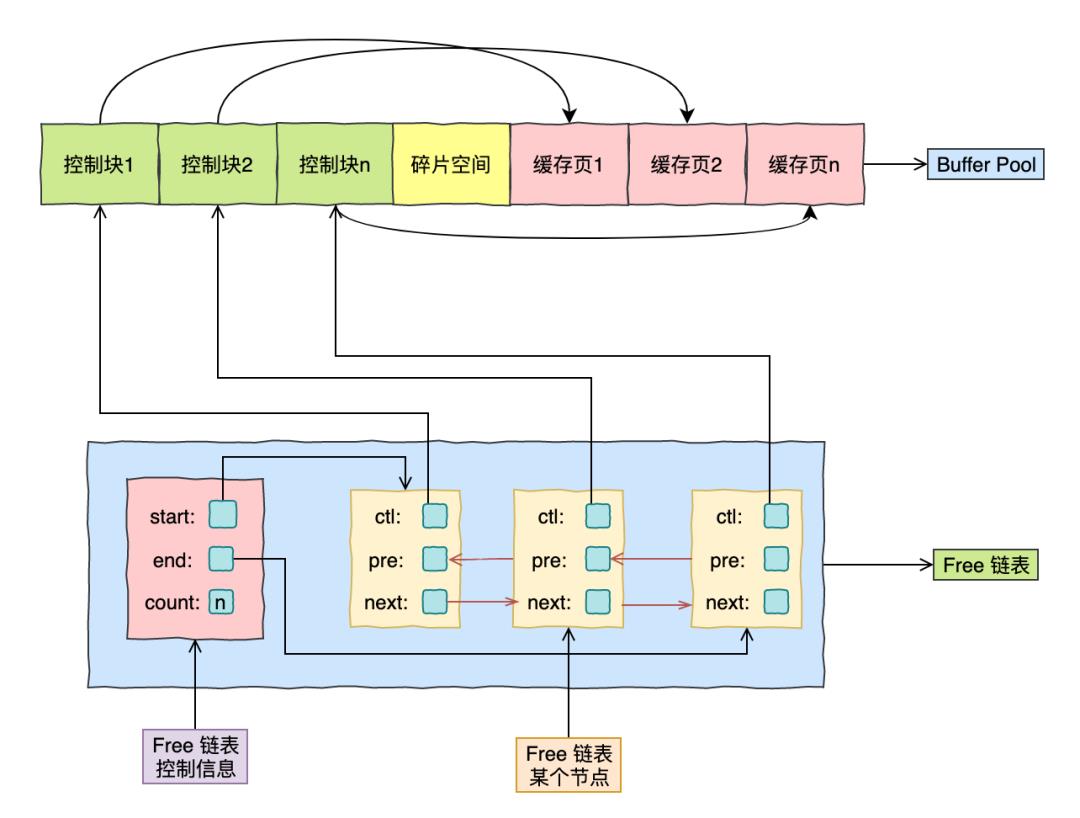
Free 链表
When starting the MySQL server, you need to complete the initialization process of the buffer pool, that is, allocate the memory space of the buffer pool and divide it into several pairs of control blocks and cache pages. However, at this time, no real disk pages are cached in the buffer pool. Later, with the running of the program, the pages on the disk will continue to be cached in the buffer pool. In the use process, in order to record which cache pages are available, we package all free pages into a node to form a linked list, which can be called free linked list. Because all the cache pages in the buffer pool that have just been initialized are idle, every cache page will be added to the free list. In order to facilitate the management of free linked list, some "control information" is specially defined for this linked list, which contains the address of the head node and tail node of the linked list, as well as the number of nodes in the current linked list. In addition, the address of a "cache page control block" is recorded in each free list node, and the corresponding "cache page address" is recorded in each "cache page control block", so each free list node corresponds to an idle cache page.
给大家画了个结构图:
2、Lru 链表
Lru 链表用来管理已经读取的页,当数据库刚启动时,Lru 链表是空的,此时页也都放在 Free 列表中,当需要读取数据时,会从 Free 链表中申请一个页,把从放入到磁盘读取的数据放入到申请的页中,这个页的集合叫做 Lru 链表。
LRU linked list is used to manage the pages that have been read. When the database is just started, the LRU linked list is empty, and the pages are also placed in the free list. When data needs to be read, a page will be applied from the free linked list, and the data read from the disk will be put into the applied page. The set of pages is called LRU linked list.
问题1:传统的LRU是如何进行缓冲页管理?
最常见的玩法是,把入缓冲池的页放到LRU的头部,作为最近访问的元素,从而最晚被淘汰。这里又分两种情况:
(1)页已经在缓冲池里,那就只做“移至”LRU头部的动作,而没有页被淘汰;
(2)页不在缓冲池里,除了做“放入”LRU头部的动作,还要做“淘汰”LRU尾部页的动作;
The most common way to play is to put the page into the buffer pool in the head of the LRU as the most recently accessed element, so that it will be eliminated at the latest. There are two situations
(1) If the page is already in the buffer pool, only move it to the LRU header, and no page is eliminated;
(2) The page is not in the buffer pool. In addition to the action of "putting" the LRU header, the action of "weeding" the LRU tail page is also performed;
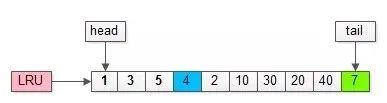
如上图,假如管理缓冲池的LRU长度为10,缓冲了页号为1,3,5…,40,7的页。
假如,接下来要访问的数据在页号为4的页中:
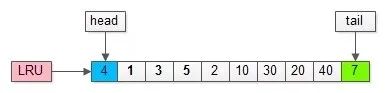
(1)页号为4的页,本来就在缓冲池里;
(2)把页号为4的页,放到LRU的头部即可,没有页被淘汰;
假如,再接下来要访问的数据在页号为50的页中:
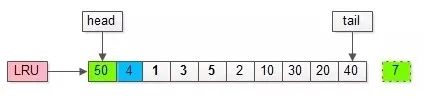
(1)页号为50的页,原来不在缓冲池里;
(2)把页号为50的页,放到LRU头部,同时淘汰尾部页号为7的页;
传统的LRU缓冲池算法十分直观,OS,memcache等很多软件都在用,MySQL为啥这么矫情,不能直接用呢?
这里有两个问题:
(1)预读失效;
(2)缓冲池污染;
什么是预读失效?
由于预读(Read-Ahead),提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
问题2:如何对预读失效进行优化?
要优化预读失效,思路是:
(1)让预读失败的页,停留在缓冲池LRU里的时间尽可能短;
(2)让真正被读取的页,才挪到缓冲池LRU的头部;
以保证,真正被读取的热数据留在缓冲池里的时间尽可能长。
具体方法是:
(1)将LRU分为两个部分:
新生代(new sublist)
老生代(old sublist)
(2)新老生代收尾相连,即:新生代的尾(tail)连接着老生代的头(head);
(3)新页(例如被预读的页)加入缓冲池时,只加入到老生代头部:
如果数据真正被读取(预读成功),才会加入到新生代的头部
如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池
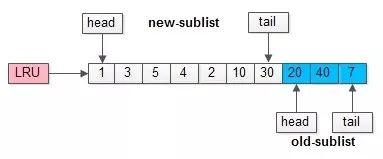
举个例子,整个缓冲池LRU如上图:
(1)整个LRU长度是10;
(2)前70%是新生代;
(3)后30%是老生代;
(4)新老生代首尾相连;
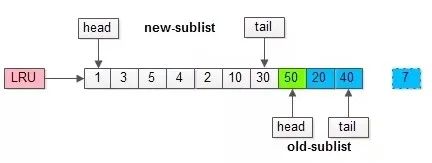
假如有一个页号为50的新页被预读加入缓冲池:
(1)50只会从老生代头部插入,老生代尾部(也是整体尾部)的页会被淘汰掉;
(2)假设50这一页不会被真正读取,即预读失败,它将比新生代的数据更早淘汰出缓冲池;
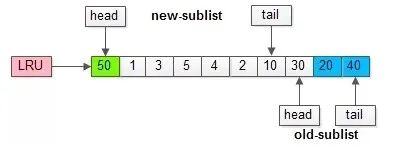
假如50这一页立刻被读取到,例如SQL访问了页内的行row数据:
(1)它会被立刻加入到新生代的头部;
(2)新生代的页会被挤到老生代,此时并不会有页面被真正淘汰;
改进版缓冲池LRU能够很好的解决“预读失败”的问题。
The improved buffer pool LRU can solve the problem of "read ahead failure".
新老生代改进版LRU仍然解决不了缓冲池污染的问题。
问题3:什么是MySQL缓冲池污染?
当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
When a SQL statement needs to scan a large amount of data in batches, it may cause all pages in the buffer pool to be replaced, resulting in a large amount of hot data to be replaced, and MySQL performance drops sharply. This situation is called buffer pool pollution.
例如,有一个数据量较大的用户表,当执行:
select * from user where name like "%shenjian%";
虽然结果集可能只有少量数据,但这类like不能命中索引,必须全表扫描,就需要访问大量的页:
(1)把页加到缓冲池(插入老生代头部);
(2)从页里读出相关的row(插入新生代头部);
(3)row里的name字段和字符串shenjian进行比较,如果符合条件,加入到结果集中;
(4)…直到扫描完所有页中的所有row…
如此一来,所有的数据页都会被加载到新生代的头部,但只会访问一次,真正的热数据被大量换出。
问题7:怎么这类扫码大量数据导致的缓冲池污染问题呢?
MySQL缓冲池加入了一个“老生代停留时间窗口”的机制:
(1)假设T=老生代停留时间窗口;
(2)插入老生代头部的页,即使立刻被访问,并不会立刻放入新生代头部;
(3)只有满足“被访问”并且“在老生代停留时间”大于T,才会被放入新生代头部;
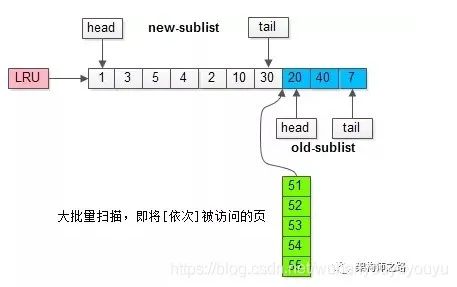
继续举例,假如批量数据扫描,有51,52,53,54,55等五个页面将要依次被访问。
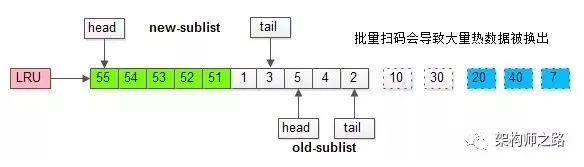
如果没有“老生代停留时间窗口”的策略,这些批量被访问的页面,会换出大量热数据。
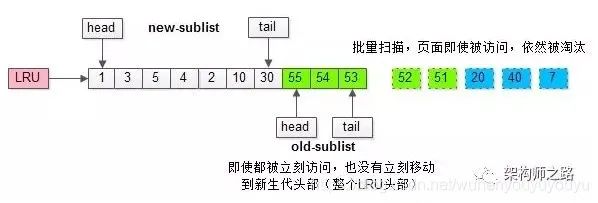
加入“老生代停留时间窗口”策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些,短期内仅仅访问了一次的页。
After adding the "old generation residence time window" strategy, the pages that are loaded a lot in a short time will not be inserted into the new generation header immediately, but the pages that are visited only once in a short time will be eliminated first.
而只有在老生代呆的时间足够久,停留时间大于T,才会被插入新生代头部。
3、Flush 链表
Flush 链表用来管理被修改的页,Buffer Pool 中被修改的页也被称之为「脏页」,脏页既存在于 Lru 链表中,也存在于 Flush 链表中,Flush 链表中存的是一个指向 Lru 链表中具体数据的指针。
因此只有 Lru 链表中的页第一次被修改时,对应的指针才会存入到 Flush 中,若之后再修改这个页,则是直接更新 Lru 链表中的页对应的数据。
The flush linked list is used to manage the modified pages. The modified pages in buffer pool are also called "dirty pages". Dirty pages exist in both LRU linked list and flush linked list. The flush linked list contains a pointer to the specific data in LRU linked list.
Therefore, only when the page in the LRU linked list is modified for the first time, the corresponding pointer will be saved in flush. If the page is modified later, the data corresponding to the page in the LRU linked list will be updated directly.
这三者之间是这么个关系:
Buffer Pool 一个最主要的功能是「加速读」。加速读是当需要访问一个数据页面的时候,如果这个页面已经在缓存池中,那么就不再需要访问磁盘,直接从缓冲池中就能获取这个页面的内容。当我们需要访问某个页中的数据时,就会把该页加载到 Buffer Pool 中,如果该页已经在 Buffer Pool 中的话直接使用就可以了。
One of the most important functions of buffer pool is to speed up reading. Accelerated reading is when you need to access a data page, if the page is already in the cache pool, you no longer need to access the disk, and you can get the content of the page directly from the cache pool. When we need to access the data in a page, we will load the page into the buffer pool. If the page is already in the buffer pool, we can use it directly.
问题:那么如何快速查找在 Buffer Pool 中的页呢?
为了避免查询数据页时扫描 Lru,其实是根据表空间号 + 页号来定位一个页的,也就相当于表空间号 + 页号是一个 key,缓存页就是对应的 value。用表空间号 + 页号作为 key,缓存页作为 value 创建一个哈希表,在需要访问某个页的数据时,先从哈希表中根据表空间号 + 页号看看有没有对应的缓存页。
In order to avoid scanning LRU when querying data pages, a page is actually located according to the table space number + page number, which means that the table space number + page number is a key and the cache page is the corresponding value. Create a hash table with the table space number + page number as the key and the cache page as the value. When you need to access the data of a page, first check whether there is a corresponding cache page from the hash table according to the table space number + page number.
如果有,直接使用该缓存页就好。
如果没有,那就从 Free 链表中选一个空闲的缓存页,然后把磁盘中对应的页加载到该缓存页的位置。每当需要从磁盘中加载一个页到 Buffer Pool 中时,就从 Free 链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上,然后把该缓存页对应的 Free 链表节点从链表中移除,表示该缓存页已经被使用了,并且把该页写入 Lru 链表。
If not, select an idle cache page from the free list, and then load the corresponding page in the disk to the location of the cache page. Whenever you need to load a page from the disk into the buffer pool, take an idle cache page from the free list, fill in the information of the control block corresponding to the cache page, and then remove the free list node corresponding to the cache page from the list, indicating that the cache page has been used, and write the page to the LRU list.
在初始化的时候,Buffer pool 中所有的页都是空闲页,需要读数据时,就会从 Free 链表中申请页,但是物理内存不可能无限增大,数据库的数据却是在不停增大的,所以 Free 链表的页是会用完的。
During initialization, all the pages in the buffer pool are free pages. When you need to read data, you will apply for pages from the free linked list. However, the physical memory cannot be increased infinitely, but the data in the database keeps increasing, so the pages in the free linked list will be used up.
因此需要考虑把已经缓存的页从 Buffer pool 中删除一部分,进而需要考虑如何删除及删除哪些已经缓存的页。假设一共访问了 n 次页,那么被访问的页在缓存中的次数除以 n 就是缓存命中率,缓存命中率越高,和磁盘的 IO 交互也就越少 。
Therefore, we need to consider deleting some cached pages from the buffer pool, and then we need to consider how to delete and which cached pages to delete. Assuming that a total of N pages are accessed, then the number of pages accessed in the cache divided by N is the cache hit rate. The higher the cache hit rate, the less IO interaction with the disk.
为了提高缓存命中率,InnoDB 在传统 Lru 算法的基础上做了优化,解决了两个问题:
1、预读失效 2、缓存池污染写操作
Buffer pool 另一个主要的功能是「加速写」,即当需要修改一个页面的时候,先将这个页面在缓冲池中进行修改,记下相关的重做日志,这个页面的修改就算已经完成了。
被修改的页面真正刷新到磁盘,这个是后台刷新线程来完成的。前面页面更新是在缓存池中先进行的,那它就和磁盘上的页不一致了,这样的缓存页被称为脏页(dirty page)。
Another main function of buffer pool is to speed up writing. When a page needs to be modified, it is first modified in the buffer pool, and the relevant redo log is recorded. The modification of the page is completed.
The modified page is really refreshed to disk, which is completed by the background refresh thread. The previous page update is carried out in the cache pool first, then it is inconsistent with the pages on the disk, such a cache page is called dirty page.
问题3:这些被修改的页面什么时候刷新到磁盘?以什么样的顺序刷新到磁盘?
最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能。所以每次修改缓存页后,不能立即把修改同步到磁盘上,而是在未来的某个时间点进行同步,由后台刷新线程依次刷新到磁盘,实现修改落地到磁盘。
The simplest way is to synchronize every modification to the corresponding page on the disk immediately, but writing data to the disk frequently will seriously affect the performance of the program. Therefore, every time the cache page is modified, the modification cannot be synchronized to the disk immediately. Instead, it will be synchronized at a certain time point in the future. The background refresh thread will refresh to the disk in turn to realize the landing of the modification to the disk.
但是如果不立即同步到磁盘的话,那之后再同步的时候如何判断 Buffer Pool 中哪些页是脏页,哪些页从来没被修改过呢?
InnoDB 并没有一次性把所有的缓存页都同步到磁盘上,InnoDB 创建一个存储脏页的链表,凡是在 Lru 链表中被修改过的页都需要加入这个链表中,因为这个链表中的页都是需要被刷新到磁盘上的,所以这个链表也叫 Flush 链表,链表的构造和 Free 链表一致。
But if you don't synchronize to the disk immediately, how can you judge which pages in the buffer pool are dirty and which have never been modified when you synchronize later?
InnoDB does not synchronize all the cache pages to the disk at one time. InnoDB creates a linked list to store dirty pages. All the modified pages in LRU linked list need to be added to the linked list, because the pages in the linked list need to be refreshed to the disk, so the linked list is also called flush linked list. The structure of the linked list is consistent with the free linked list.
这里的脏页修改指的此页被加载进 Buffer Pool 后第一次被修改,只有第一次被修改时才需要加入 Flush 链表,对于已经存在在 Flush 链表中的页,如果这个页被再次修改就不会再放到 Flush 链表。
Dirty page modification here means that the page is modified for the first time after it is loaded into the buffer pool. Only when it is modified for the first time, it needs to be added to the flush list. For a page that already exists in the flush list, if it is modified again, it will not be added to the flush list.
需要注意,脏页数据实际还在 Lru 链表中,而 Flush 链表中的脏页记录只是通过指针指向 Lru 链表中的脏页。并且在 Flush 链表中的脏页是根据 oldest_lsn(这个值表示这个页第一次被更改时的 lsn 号,对应值 oldest_modification,每个页头部记录)进行排序刷新到磁盘的,值越小表示要最先被刷新,避免数据不一致。
It should be noted that the dirty page data is still in the LRU linked list, while the dirty page records in the flush linked list only point to the dirty pages in the LRU linked list through the pointer. And the dirty pages in the flush list are based on oldest_ LSN (this value represents the LSN number of the page when it was first changed, corresponding to oldest_ The smaller the value is, the earlier it will be refreshed to avoid data inconsistency.
-
innodb_buffer_pool_size:缓存池的大小最多应设置为物理内存的 80% -
innodb_buffer_pool_instance:设置有多少个缓存池,通常建议把缓存池个数设置为 CPU 的个数,多个缓存池可以减少数据库内部的资源竞争,增加数据库并发访问的能力 -
innodb_old_blocks_pct:老生代占整个 LRU 的链长比例,默认是 3:7 -
innodb_old_blocks_time:老生代停留时间窗口,单位是毫秒,默认是 1000,即同时满足“被访问”与“在老生代停留时间超过 1 秒”两个条件,才会被插入到新生代头部
以上是关于MYSQL DB_CACHE的主要内容,如果未能解决你的问题,请参考以下文章