我妈给我介绍对象了,我大学还没毕业呢,先在婚介市场也这么卷了的吗?Python爬虫实战:甜蜜蜜婚介数据采集
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我妈给我介绍对象了,我大学还没毕业呢,先在婚介市场也这么卷了的吗?Python爬虫实战:甜蜜蜜婚介数据采集相关的知识,希望对你有一定的参考价值。
大家好,我是辣条。
说出来你们可能不信,我一个在校还没毕业的学生家里竟然给我介绍对象了…这么着急的吗?现在结婚市场都这么卷了吗?男孩们女孩们不努力的话是会被家里捉回去结婚的哦。
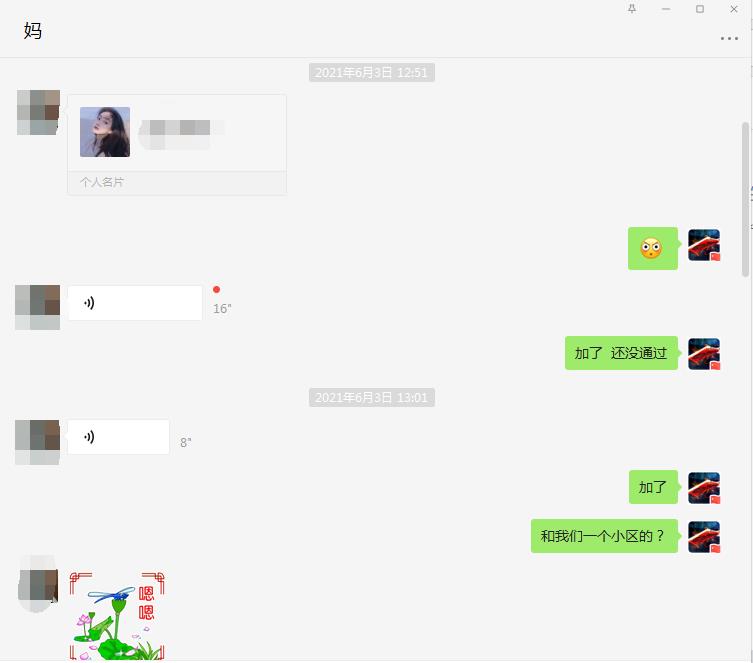
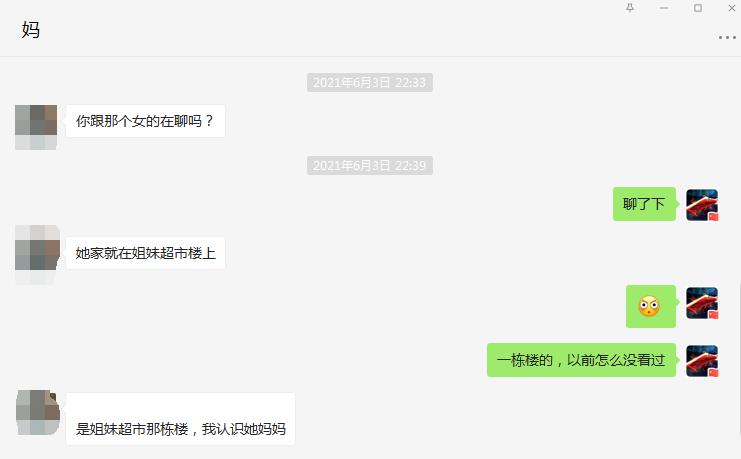
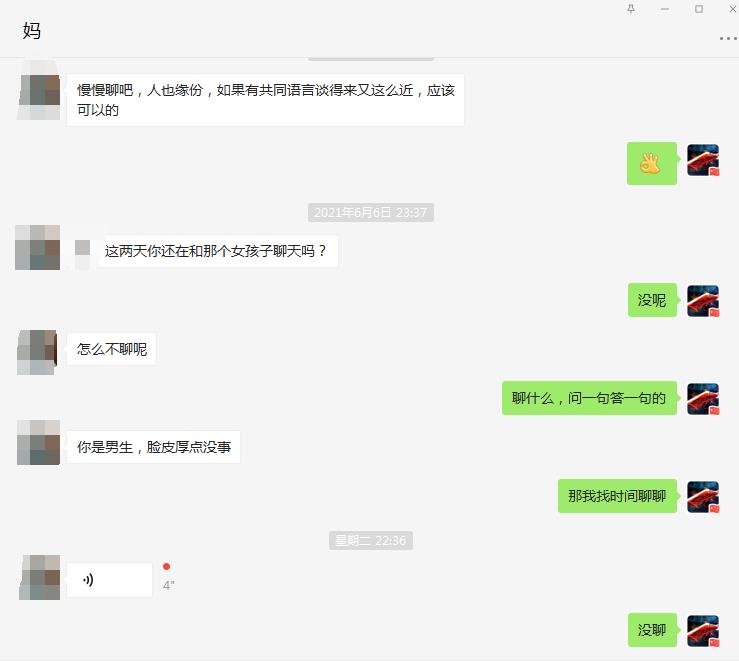
这是和我妈的聊天对话,然后给你看看和这个女生的。
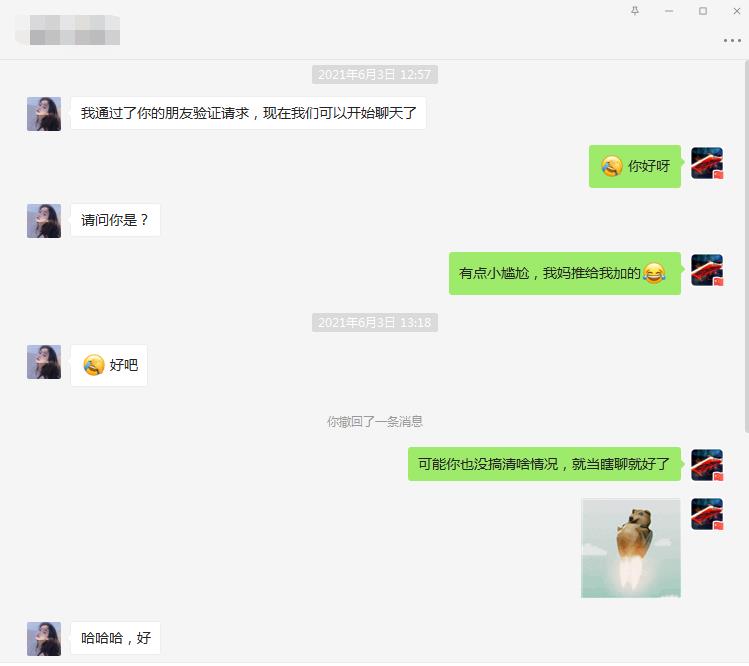
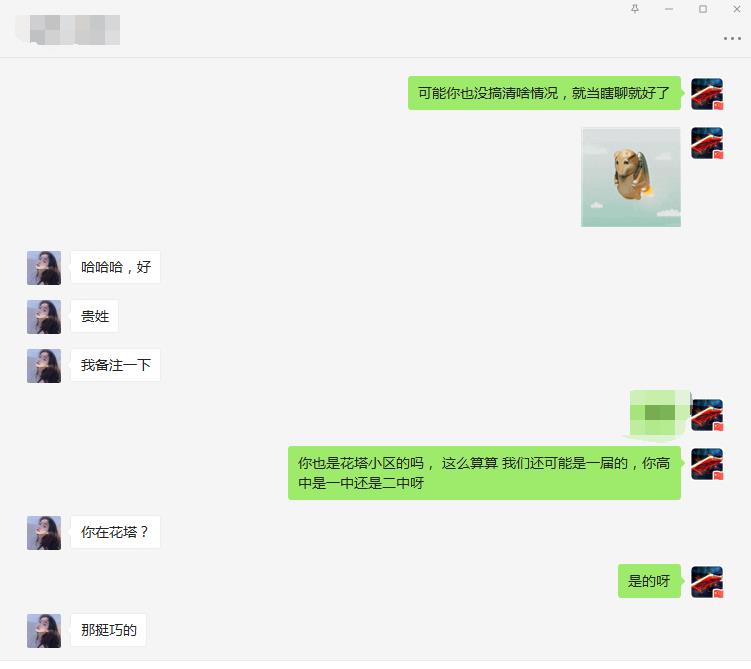
后面就没然后了,我这聊的有问题吗?兄弟们说说我这也不算直男吧,难道要我直接约出来聊?然后我就想到婚介市场了,受此启发想爬取一个婚介市场数据下来看看,既能让大家了解现在的单身男女情况,又能学习技术,何乐而不为呢?直接进入主题吧!
爬虫目标
网址:xxxx婚介
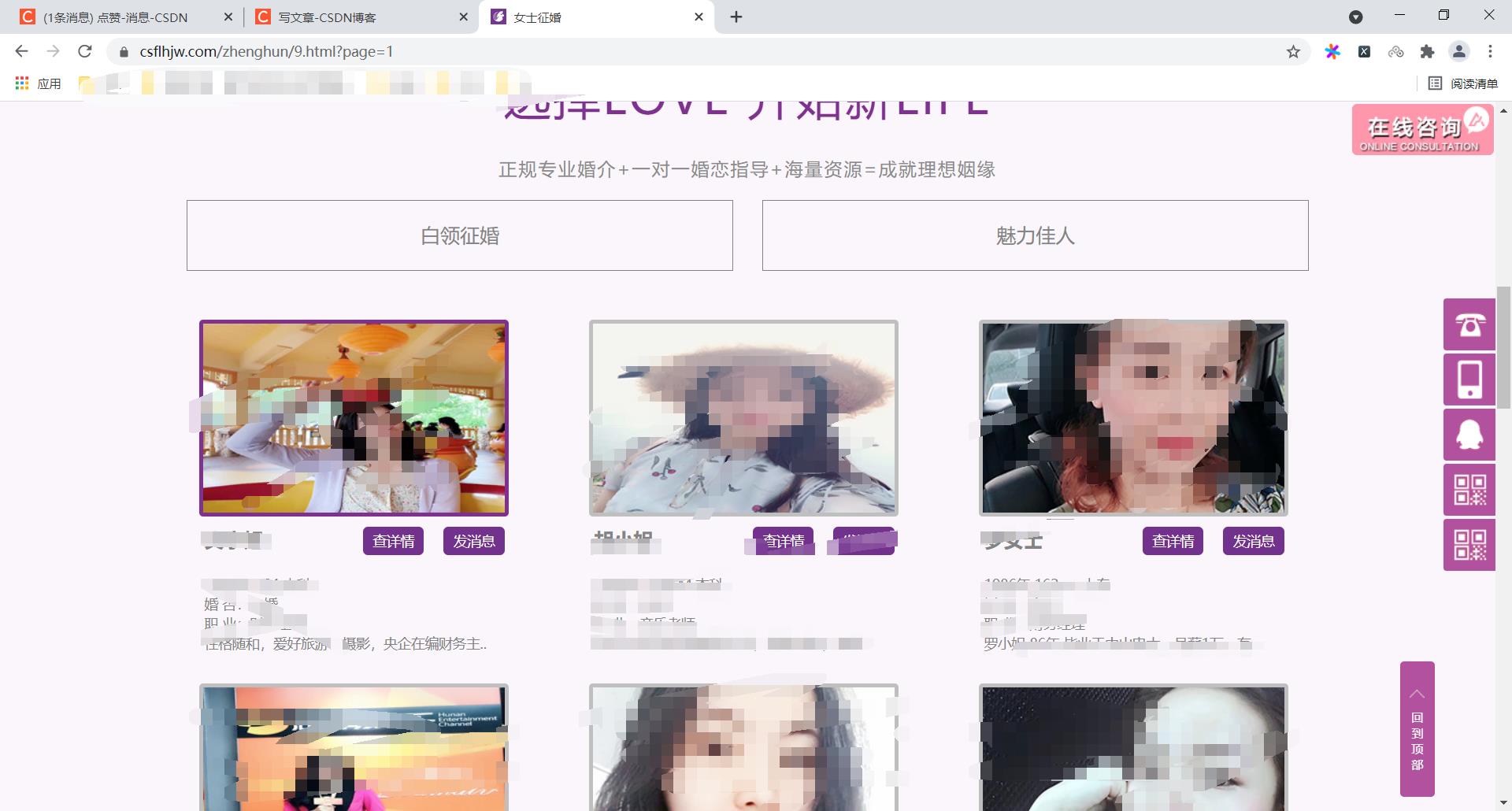
效果展示
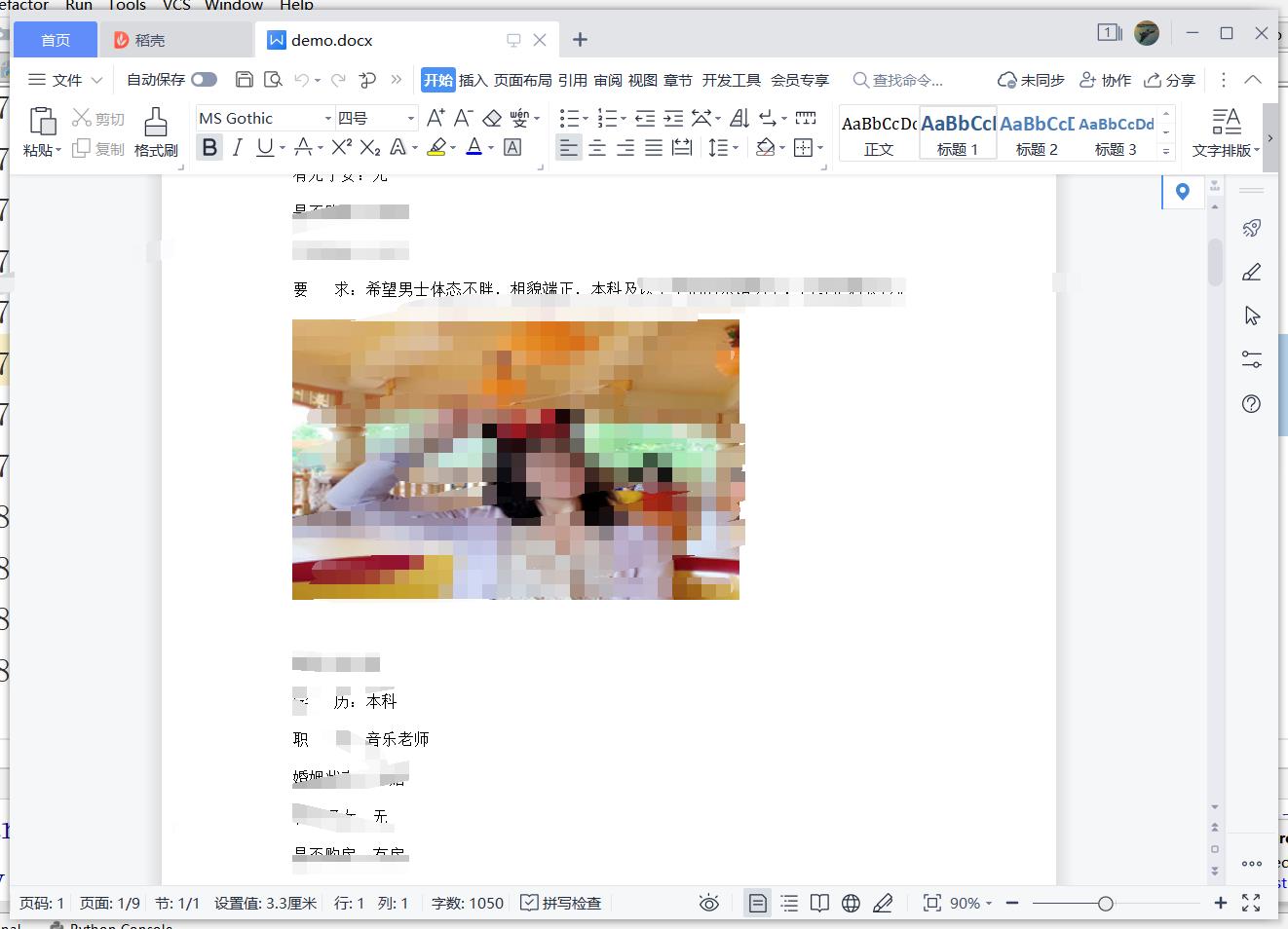
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:requests、docx,lxml
重点学习内容
1.xpath提取数据
2.docx文档数据保存
3.requests的使用
项目思路解析
选取你财富密码的年龄划分

获取到当前页面的网页数据
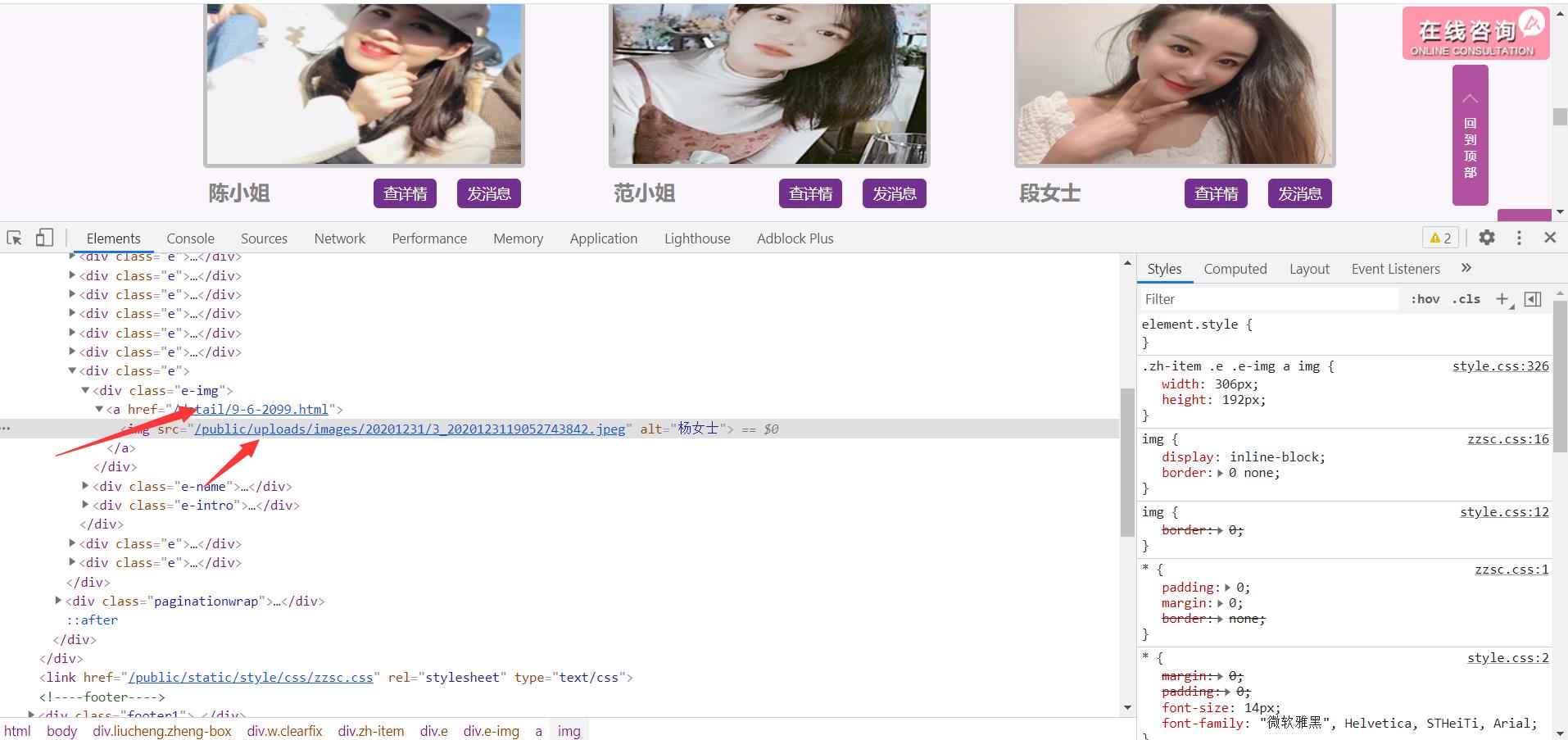
通过xpath的方式提取出对应的超链接
获取到图片地址,用于保存图片
def get_data(url):
response = requests.get(url, headers=headers)
# print(response.text)
data = etree.html(response.text)
href_list = data.xpath("//div[@class='e-img']/a/@href")
img_list = data.xpath("//div[@class='e-img']/a/img/@src")
拼接出详情页面的url地址
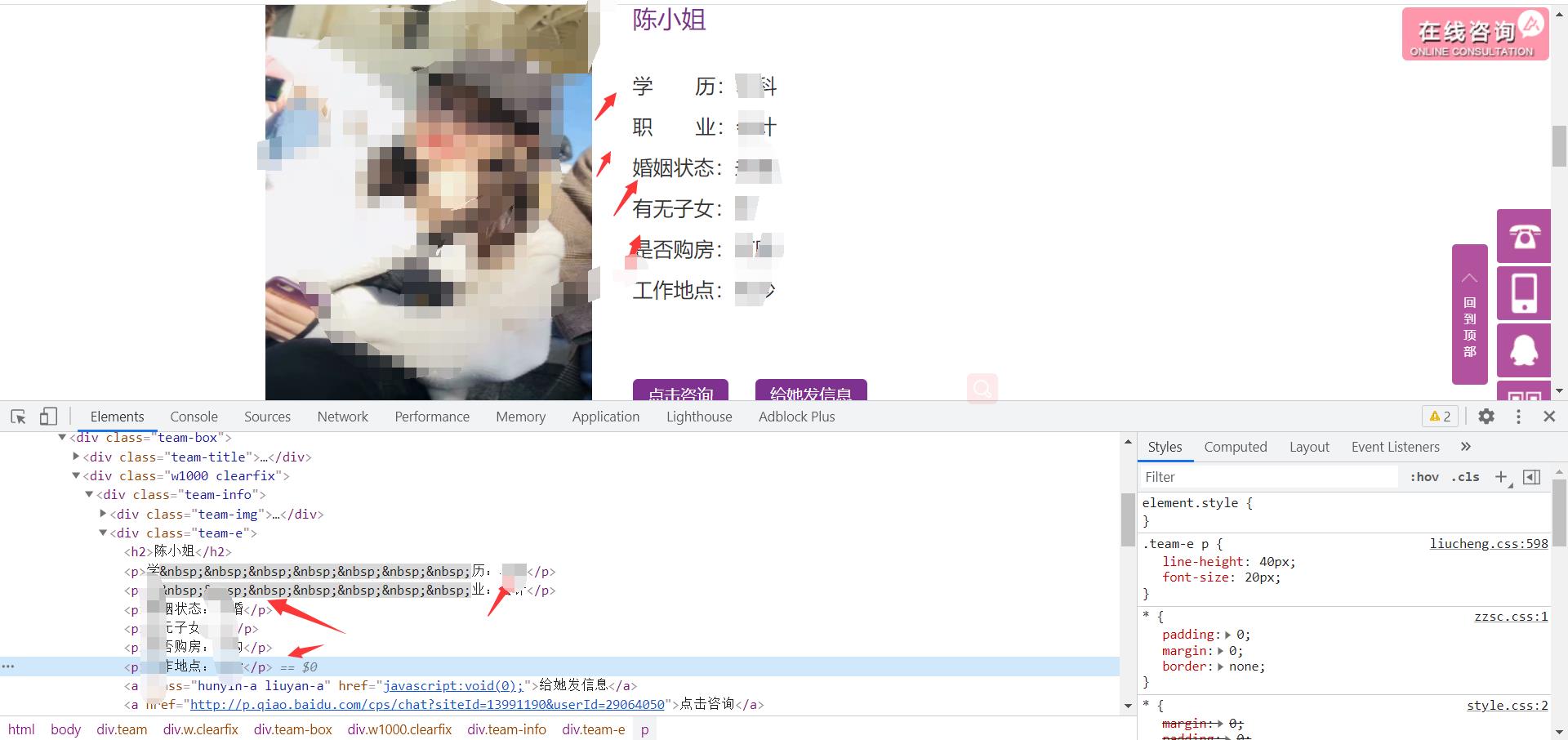
获取详情页面的数据
获取图片数据
- 名字
- 学历
- 职业
- 婚约状况
- 工作地址
- 要求
- 。。。。。
for href, img in zip(href_list, img_list):
img = requests.get("https://www.csflhjw.com" + img, headers=headers).content
print(img)
f = open("1.jpg", "wb")
f.write(img)
res = requests.get("https://www.csflhjw.com" + href, headers=headers)
# print(res.text)
html = etree.HTML(res.text)
name = html.xpath('//div[@class="team-e"]/h2/text()')[0]
edu = html.xpath('//div[@class="team-e"]/p[1]/text()')[0]
profession = html.xpath('//div[@class="team-e"]/p[2]/text()')
sponsa = html.xpath('//div[@class="team-e"]/p[3]/text()')[0]
children = html.xpath('//div[@class="team-e"]/p[4]/text()')[0]
house = html.xpath('//div[@class="team-e"]/p[5]/text()')[0]
add = html.xpath('//div[@class="team-e"]/p[6]/text()')[0]
ask_for = html.xpath('//div[@class="hunyin-1-2"]/p[2]/span/text()')[0]
将数据保存在docx文档
创建文档文件
document = Document()
document.add_heading('甜蜜蜜婚介')
document.add_paragraph("姓名:" + name)
document.add_paragraph(edu)
document.add_paragraph(profession)
document.add_paragraph(sponsa)
document.add_paragraph(children)
document.add_paragraph(house)
document.add_paragraph(add)
document.add_paragraph(ask_for)
document.add_picture("1.jpg")
document.add_paragraph(" ")
简易源码分析
import requests
from docx import Document
from lxml import etree
document = Document()
document.add_heading('甜蜜蜜婚介')
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'
}
def get_data(url):
response = requests.get(url, headers=headers)
# print(response.text)
data = etree.HTML(response.text)
href_list = data.xpath("//div[@class='e-img']/a/@href")
img_list = data.xpath("//div[@class='e-img']/a/img/@src")
# print(href_list)
for href, img in zip(href_list, img_list):
img = requests.get("https://www.csflhjw.com" + img, headers=headers).content
print(img)
f = open("1.jpg", "wb")
f.write(img)
res = requests.get("https://www.csflhjw.com" + href, headers=headers)
# print(res.text)
html = etree.HTML(res.text)
name = html.xpath('//div[@class="team-e"]/h2/text()')[0]
edu = html.xpath('//div[@class="team-e"]/p[1]/text()')[0]
profession = html.xpath('//div[@class="team-e"]/p[2]/text()')
sponsa = html.xpath('//div[@class="team-e"]/p[3]/text()')[0]
children = html.xpath('//div[@class="team-e"]/p[4]/text()')[0]
house = html.xpath('//div[@class="team-e"]/p[5]/text()')[0]
add = html.xpath('//div[@class="team-e"]/p[6]/text()')[0]
ask_for = html.xpath('//div[@class="hunyin-1-2"]/p[2]/span/text()')[0]
document.add_paragraph("姓名:" + name)
document.add_paragraph(edu)
document.add_paragraph(profession)
document.add_paragraph(sponsa)
document.add_paragraph(children)
document.add_paragraph(house)
document.add_paragraph(add)
document.add_paragraph(ask_for)
document.add_picture("1.jpg")
document.add_paragraph(" ")
def main():
for i in range(1, 2):
url = "https://www.csflhjw.com/zhenghun/9.html?page={}".format(i)
html_data = get_data(url)
if __name__ == '__main__':
main()
document.save('demo.docx')
PS:我已经能看到我以后被催婚的场景了,兄弟们加油吧,好好赚钱先立业后成家!文章内容仅供学习交流!如果对你有帮助的话记得给辣条三连啦!
以上是关于我妈给我介绍对象了,我大学还没毕业呢,先在婚介市场也这么卷了的吗?Python爬虫实战:甜蜜蜜婚介数据采集的主要内容,如果未能解决你的问题,请参考以下文章