Python使用ClickHouse实践与踩坑记
Posted 肖永威
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python使用ClickHouse实践与踩坑记相关的知识,希望对你有一定的参考价值。
ClickHouse是近年来备受关注的开源列式数据库(DBMS),主要用于数据联机分析(OLAP)领域,于2016年开源。目前国内社区火热,各个大厂纷纷跟进大规模使用。
- 今日头条,内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
- 腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从2018年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
- 快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
在国外,Yandex内部有数百节点用于做用户点击行为分析,CloudFlare、Spotify等头部公司也在使用。[2].
ClickHouse最初是为 YandexMetrica 世界第二大Web分析平台 而开发的。多年来一直作为该系统的核心组件被该系统持续使用着。
1. 关于ClickHouse使用实践
首先,我们回顾一些基础概念:
- OLTP:是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统。
- OLAP:是仓库型数据库,主要是读取数据,做复杂数据分析,侧重技术决策支持,提供直观简单的结果。
1.1. ClickHouse 应用于数据仓库场景
ClickHouse做为列式数据库,列式数据库更适合OLAP场景,OLAP场景的关键特征:
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
1.2. 客户端工具DBeaver
Clickhouse客户端工具为dbeaver,官网为https://dbeaver.io/。
dbeaver是免费和开源(GPL)为开发人员和数据库管理员通用数据库工具。[百度百科]
易用性是该项目的主要目标,是经过精心设计和开发的数据库管理工具。免费、跨平台、基于开源框架和允许各种扩展写作(插件)。
它支持任何具有一个JDBC驱动程序数据库。
它可以处理任何的外部数据源。
通过操作界面菜单中“数据库”创建配置新连接,如下图所示,选择并下载ClickHouse驱动(默认不带驱动)。

DBeaver配置是基于Jdbc方式,一般默认URL和端口如下:
jdbc:clickhouse://192.168.17.61:8123
如下图所示。
在是用DBeaver连接Clickhouse做查询时,有时候会出现连接或查询超时的情况,这个时候可以在连接的参数中添加设置socket_timeout参数来解决问题。
jdbc:clickhouse://{host}:{port}[/{database}]?socket_timeout=600000

1.3. 大数据应用实践
环境简要说明:
硬件资源有限,仅有16G内存,交易数据为亿级。
本应用是某交易大数据,主要包括交易主表、相关客户信息、物料信息、历史价格、优惠及积分信息等,其中主交易表为自关联树状表结构。
为了分析客户交易行为,在有限资源的条件下,按日和交易点抽取、汇集交易明细为交易记录,如下图所示。
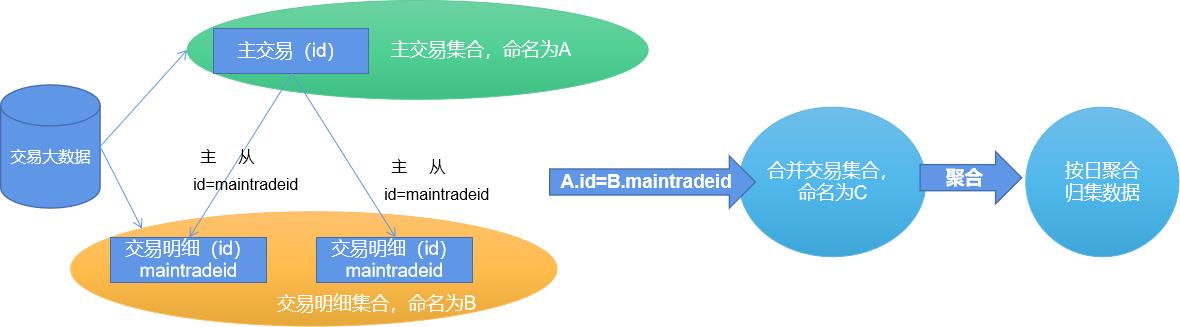
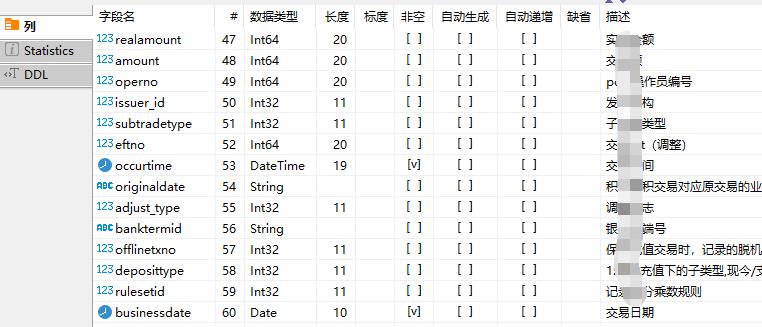
其中,在ClickHouse上,交易数据结构由60个列(字段)组成,截取部分如下所示:
针对频繁出现“would use 10.20 GiB , maximum: 9.31 GiB”等内存不足的情况,基于ClickHouse的SQL,编写了提取聚合数据集SQL语句,如下所示。
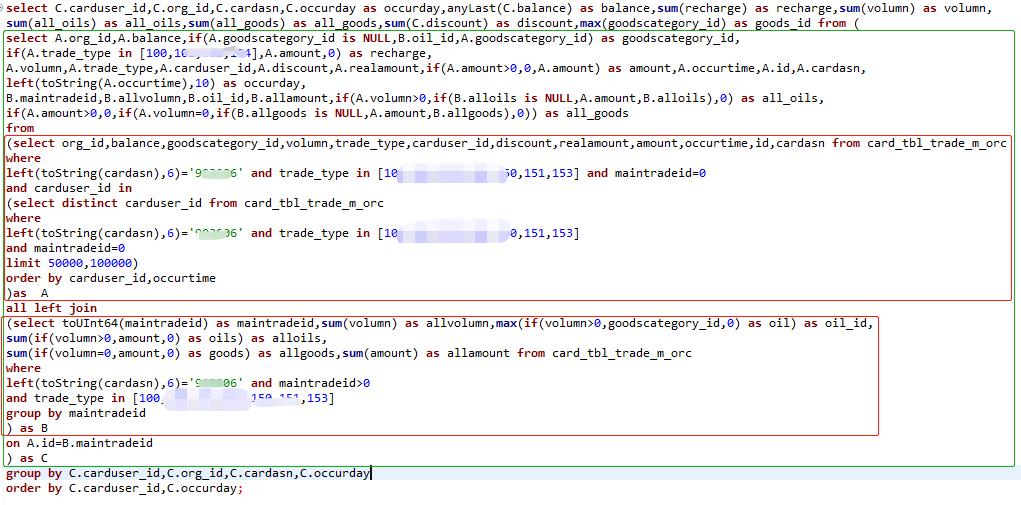
大约60s返回结果,如下所示:

2. Python使用ClickHouse实践
2.1. ClickHouse第三方Python驱动clickhouse_driver
ClickHouse没有提供官方Python接口驱动,常用第三方驱动接口为clickhouse_driver,可以使用pip方式安装,如下所示:
pip install clickhouse_driver
Collecting clickhouse_driver
Downloading https://files.pythonhosted.org/packages/88/59/c570218bfca84bd0ece896c0f9ac0bf1e11543f3c01d8409f5e4f801f992/clickhouse_driver-0.2.1-cp36-cp36m-win_amd64.whl (173kB)
100% |████████████████████████████████| 174kB 27kB/s
Collecting tzlocal<3.0 (from clickhouse_driver)
Downloading https://files.pythonhosted.org/packages/5d/94/d47b0fd5988e6b7059de05720a646a2930920fff247a826f61674d436ba4/tzlocal-2.1-py2.py3-none-any.whl
Requirement already satisfied: pytz in d:\\python\\python36\\lib\\site-packages (from clickhouse_driver) (2020.4)
Installing collected packages: tzlocal, clickhouse-driver
Successfully installed clickhouse-driver-0.2.1 tzlocal-2.1
使用的client api不能用了,报错如下:
File "clickhouse_driver\\varint.pyx", line 62, in clickhouse_driver.varint.read_varint
File "clickhouse_driver\\bufferedreader.pyx", line 55, in clickhouse_driver.bufferedreader.BufferedReader.read_one
File "clickhouse_driver\\bufferedreader.pyx", line 240, in clickhouse_driver.bufferedreader.BufferedSocketReader.read_into_buffer
EOFError: Unexpected EOF while reading bytes
Python驱动使用ClickHouse端口9000。
ClickHouse服务器和客户端之间的通信有两种协议:http(端口8123)和本机(端口9000)。DBeaver驱动配置使用jdbc驱动方式,端口为8123。
ClickHouse接口返回数据类型为元组,也可以返回Pandas的DataFrame,本文代码使用的为返回DataFrame。
collection = self.client.query_dataframe(self.query_sql)
2.2. 实践程序代码
由于我本机最初资源为8G内存(现扩到16G),以及实际可操作性,分批次取数据保存到多个文件中,每个文件大约为1G。
# -*- coding: utf-8 -*-
'''
Created on 2021年3月1日
@author: xiaoyw
'''
import pandas as pd
import json
import numpy as np
import datetime
from clickhouse_driver import Client
#from clickhouse_driver import connect
# 基于Clickhouse数据库基础数据对象类
class DB_Obj(object):
'''
192.168.17.61:9000
ebd_all_b04.card_tbl_trade_m_orc
'''
def __init__(self, db_name):
self.db_name = db_name
host='192.168.17.61' #服务器地址
port ='9000' #'8123' #端口
user='***' #用户名
password='***' #密码
database=db_name #数据库
send_receive_timeout = 25 #超时时间
self.client = Client(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
#self.conn = connect(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
def setPriceTable(self,df):
self.pricetable = df
def get_trade(self,df_trade,filename):
print('Trade join price!')
df_trade = pd.merge(left=df_trade,right=self.pricetable[['occurday','DIM_DATE','END_DATE','V_0','V_92','V_95','ZDE_0','ZDE_92',
'ZDE_95']],how="left",on=['occurday'])
df_trade.to_csv(filename,mode='a',encoding='utf-8',index=False)
def get_datas(self,query_sql):
n = 0 # 累计处理卡客户数据
k = 0 # 取每次DataFrame数据量
batch = 100000 #100000 # 分批次处理
i = 0 # 文件标题顺序累加
flag=True # 数据处理解释标志
filename = 'card_trade_all_{}.csv'
while flag:
self.query_sql = query_sql.format(n, n+batch)
print('query started')
collection = self.client.query_dataframe(self.query_sql)
print('return query result')
df_trade = collection #pd.DataFrame(collection)
i=i+1
k = len(df_trade)
if k > 0:
self.get_trade(df_trade, filename.format(i))
n = n + batch
if k == 0:
flag=False
print('Completed ' + str(k) + 'trade details!')
print('Usercard count ' + str(n) )
return n
# 价格变动数据集
class Price_Table(object):
def __init__(self, cityname, startdate):
self.cityname = cityname
self.startdate = startdate
self.filename = 'price20210531.csv'
def get_price(self):
df_price = pd.read_csv(self.filename)
......
self.price_table=self.price_table.append(data_dict, ignore_index=True)
print('generate price table!')
class CardTradeDB(object):
def __init__(self,db_obj):
self.db_obj = db_obj
def insertDatasByCSV(self,filename):
# 存在数据混合类型
df = pd.read_csv(filename,low_memory=False)
# 获取交易记录
def getTradeDatasByID(self,ID_list=None):
# 字符串过长,需要使用'''
query_sql = '''select C.carduser_id,C.org_id,C.cardasn,C.occurday as
......
limit {},{})
group by C.carduser_id,C.org_id,C.cardasn,C.occurday
order by C.carduser_id,C.occurday'''
n = self.db_obj.get_datas(query_sql)
return n
if __name__ == '__main__':
PTable = Price_Table('湖北','2015-12-01')
PTable.get_price()
db_obj = DB_Obj('ebd_all_b04')
db_obj.setPriceTable(PTable.price_table)
CTD = CardTradeDB(db_obj)
df = CTD.getTradeDatasByID()
返回本地文件为:
3. 总结
ClickHouse在OLAP场景下应用,查询速度非常快,需要大内存支持。Python第三方clickhouse-driver 驱动基本满足数据处理需求,如果能返回Pandas DataFrame最好。
ClickHouse和Pandas聚合都是非常快的,ClickHouse聚合函数也较为丰富(例如文中anyLast(x)返回最后遇到的值),如果能通过SQL聚合的,还是在ClickHouse中完成比较理想,把更小的结果集反馈给Python进行机器学习。
参考:
[1].《Clickhouse中文社区》
[2].《ClickHouse深度揭秘》 知乎,阿里云云栖号 ,2019年12月
[3]《clickhouse-driver API》
《clickhouse-- EOFError: Unexpected EOF while reading bytes》 简书 ,mysimplebook ,2020年9月
《ClickHouse 聚合函数》 流水 flowaters
以上是关于Python使用ClickHouse实践与踩坑记的主要内容,如果未能解决你的问题,请参考以下文章