TensorFlow2 大幅提高模型准确率的神奇操作
Posted 我是小白呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow2 大幅提高模型准确率的神奇操作相关的知识,希望对你有一定的参考价值。
过拟合
当训练集的的准确率很高, 但是测试集的准确率很差的时候就, 我们就遇到了过拟合 (Overfitting) 的问题. 如图:
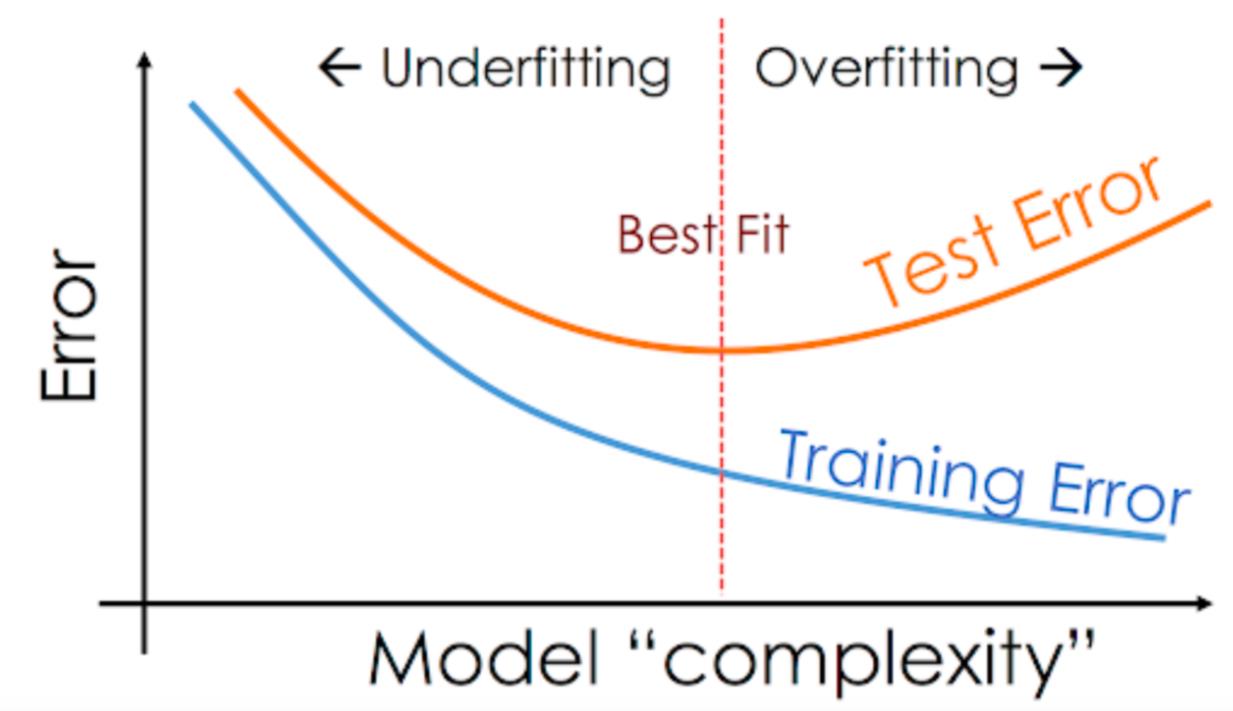
过拟合产生的一大原因是因为模型过于复杂. 下面我们将通过讲述 5 种不同的方法来解决过拟合的问题, 从而提高模型准确度.
Regulation
Regulation 可以帮助我们通过约束要优化的参数来防止过拟合.
公式
未加入 regulation 的损失:
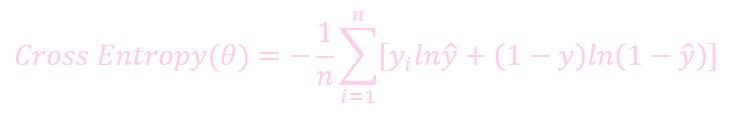
加入 regulation 的损失:
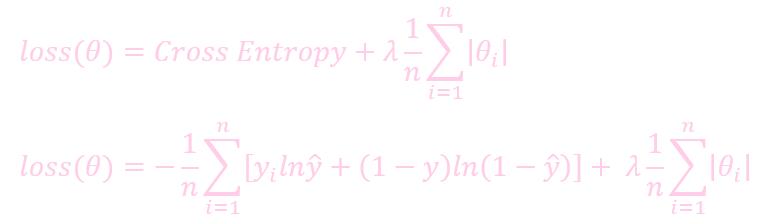
λ 和 lr (learning rate) 类似. 如果 λ 的值越大, regularion 的力度也就越强, 权重的值也就越小.
例子
添加了 l2 regulation 的网络:
network = tf.keras.Sequential([
tf.keras.layers.Dense(256, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(128, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(64, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(32, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(10)
])
动量
动量 (Momentum) 是指运动物体的租用效果. 在梯度下降的过程中, 通过在优化器中加入动量, 我们可以减少摆动从而达到更优的效果.
未添加动量:
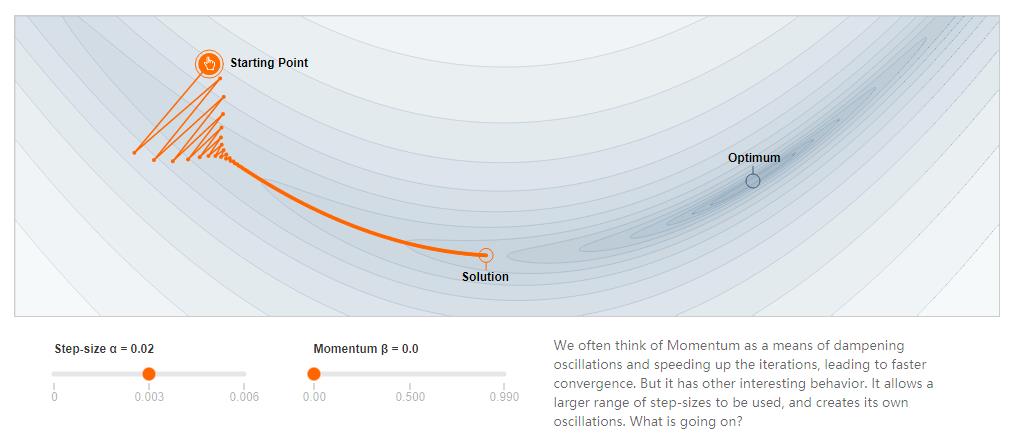
添加动量:
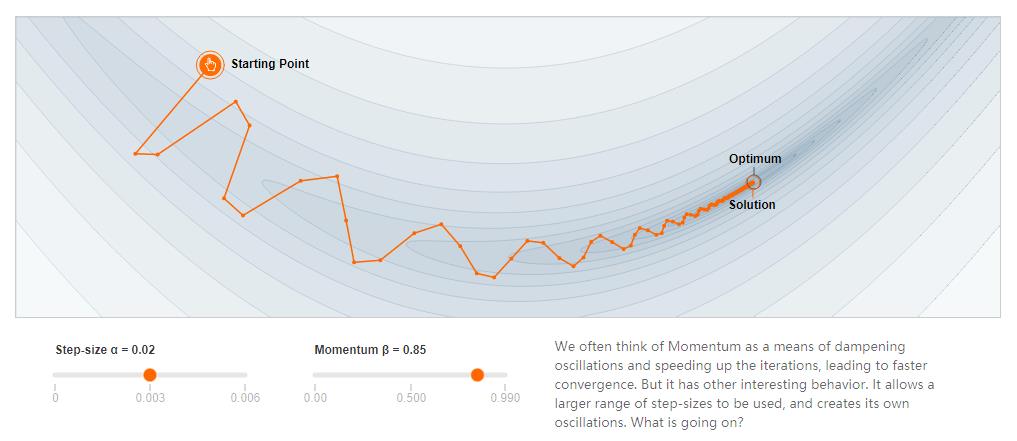
公式
未加动量的权重更新:
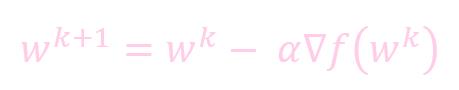
- w: 权重 (weight)
- k: 迭代的次数
- α: 学习率 (learning rate)
- ∇f(): 微分
添加动量的权重更新:
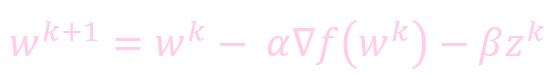
- β: 动量权重
- z: 历史微分
例子
添加了动量的优化器:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.02, momentum=0.9)
optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.02, momentum=0.9)
注: Adam 优化器默认已经添加动量, 所以无需自行添加.
学习率递减
简单的来说, 如果学习率越大, 我们训练的速度就越大, 但找到最优解的概率也就越小. 反之, 学习率越小, 训练的速度就越慢, 但找到最优解的概率就越大.
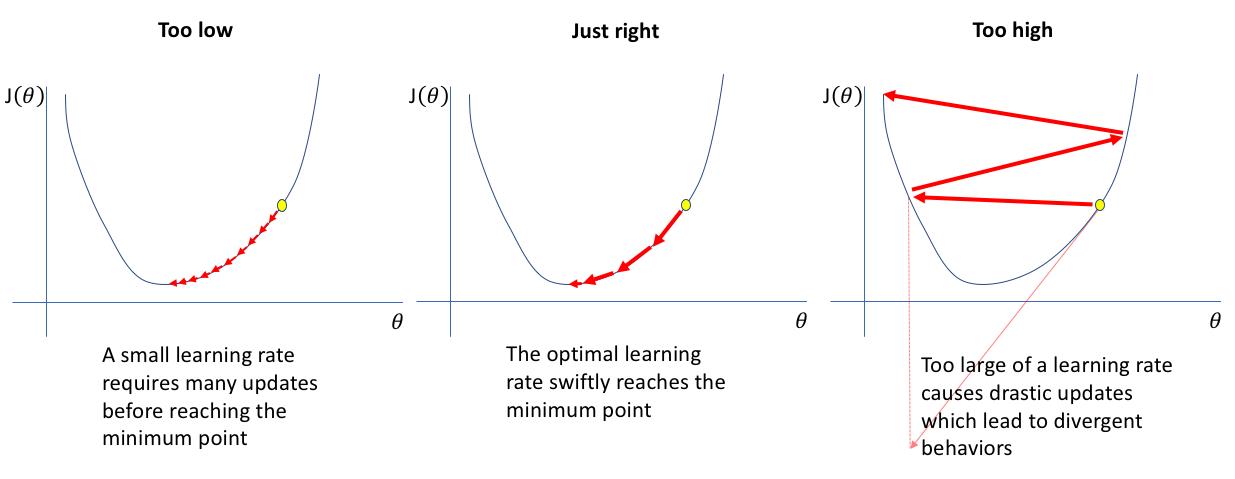
过程
我们可以在训练初期把学习率调的稍大一些, 使得网络迅速收敛. 在训练后期学习率小一些, 使得我们能得到更好的收敛以获得最优解. 如图:
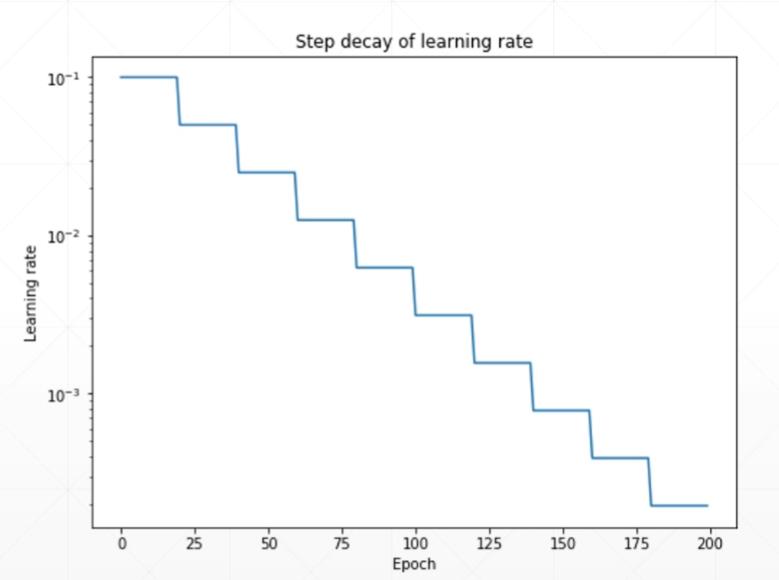
例子
learning_rate = 0.2 # 学习率
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9) # 优化器
# 迭代
for epoch in range(iteration_num):
optimizer.learninig_rate = learning_rate * (100 - epoch) / 100 # 学习率递减
Early Stopping
之前我们提到过, 当训练集的准确率仍在提升, 但是测试集的准确率反而下降的时候, 我们就遇到了过拟合 (overfitting) 的问题.
Early Stopping 可以帮助我们在测试集的准确率下降的时候停止训练, 从而避免继续训练导致的过拟合问题.
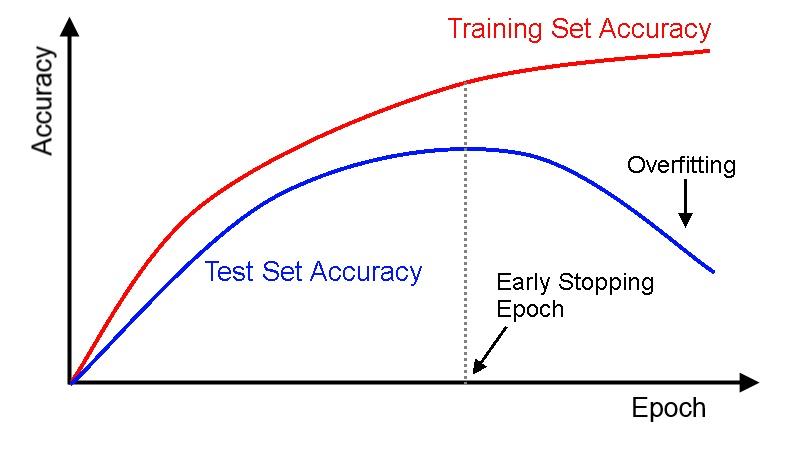
Dropout
Learning less to learn better
Dropout 会在每个训练批次中忽略掉一部分的特征, 从而减少过拟合的现象.
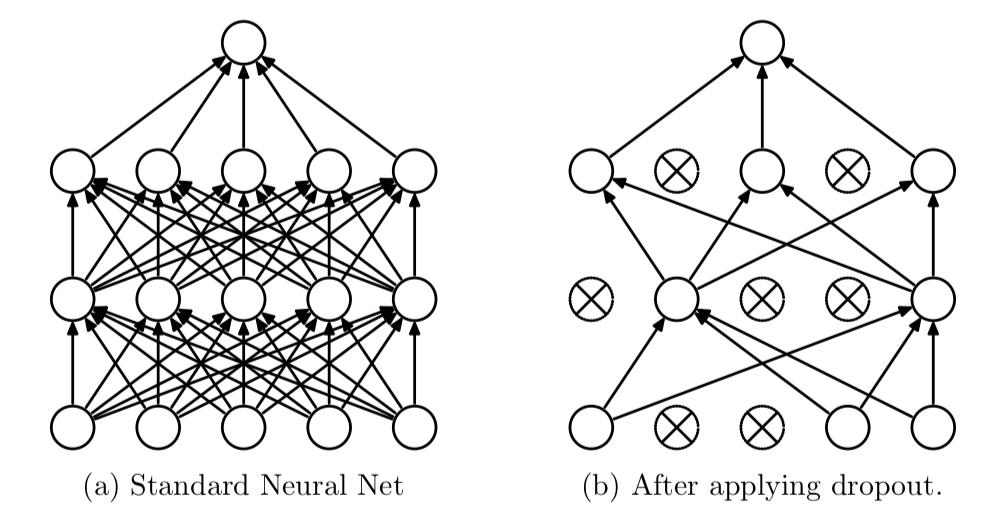
dropout, 通过强迫神经元, 和随机跳出来的其他神经元共同工作, 达到好的效果. 消除减弱神经元节点间的联合适应性, 增强了泛化能力.
例子:
network = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(32, activation=tf.nn.relu),
tf.keras.layers.Dense(10)
])
以上是关于TensorFlow2 大幅提高模型准确率的神奇操作的主要内容,如果未能解决你的问题,请参考以下文章