Elasticsearch:Elasticsearch 使得 Data Science 变得更简单了 - Eland
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Elasticsearch 使得 Data Science 变得更简单了 - Eland相关的知识,希望对你有一定的参考价值。
Eland 是一个全新的 Python 包,它在 Elasticsearch 和数据科学生态系统之间架起了一座桥梁。Elasticsearch 是一个功能丰富的开源搜索引擎,它构建在 Apache Lucene 之上,Apache Lucene 是市场上最重要的全文搜索引擎之一。Elasticsearch 以其提供的广泛而通用的 REST API 体验而闻名,包括用于全文搜索、排序和聚合任务的高效 wrapper,使得在现有后端中实现此类功能变得更加容易,而无需进行复杂的重新设计。自 2010 年推出以来,Elasticsearch 在软件工程领域获得了广泛的关注,到 2016 年,根据 DBMS 知识库 DB-engines,它成为最受欢迎的企业搜索引擎软件堆栈,超越了行业标准的 Apache Solr( 也建立在 Lucene 之上)。
Elasticsearch 如此受欢迎的原因之一是它生成的生态系统。 世界各地的工程师开发了开源 Elasticsearch 集成和扩展,其中许多项目被 Elastic(Elasticsearch 项目背后的公司)吸收作为其堆栈的一部分其中一些项目是 Logstash(数据处理管道,通常用于解析基于文本的文件)和 Kibana(建立在 Elasticsearch 之上的可视化层),导致现在广泛采用的 ELK(Elasticsearch、Logstash、Kibana)堆栈。Elastic Stack 因其在新兴和整合技术领域(例如 DevOps、站点可靠性工程以及最近的数据分析)的优异表现而得到广泛的使用。
Data science
如果您是一名阅读本文的数据科学家,并且将 Elasticsearch 作为你雇主技术堆栈的一部分,那么在尝试使用 Elasticsearch 提供的所有功能进行数据分析甚至简单的机器学习任务时,你可能会遇到一些问题。
数据科学家通常不习惯使用 NoSQL 数据库引擎执行常见任务,甚至不习惯依赖复杂的 REST API 进行分析。例如,使用 Elasticsearch 的低级 Python 客户端处理大量数据也不是那么直观,对于来自与 SWE 不同领域的人来说,学习曲线有些陡峭。
尽管 Elastic 在增强用于分析和数据科学用例的 Elastic Stack 方面做出了重大努力,但它仍然缺乏与现有数据科学生态系统(pandas、numpy、scikit-learn、PyTorch 和其他流行库)的简单接口。
2017 年,Elastic 向数据科学领域迈出了第一步,作为对机器学习和预测技术在软件行业日益普及的回应,发布了第一个支持 ML 的 X-pack(扩展包)用于 Elastic Stack,将异常检测和其他无监督 ML 任务添加到其功能中。不久之后,回归和分类模型也被添加到 Elastic Stack 中可用的 ML 任务集中。
随着 Eland 的发布,Elasticsearch 在数据科学行业获得广泛采用又迈出了一步,Eland 是一个全新的 Python Elasticsearch 客户端和工具包,具有强大(且熟悉的)类似 Pandas 的 API 用于分析、ETL 和机器学习。
Eland: Elastic 及 Data

Eland 使数据科学家能够有效地使用已经强大的 Elasticsearch 分析和 ML 功能,而无需深入了解 Elasticsearch 及其许多复杂性。
Elasticsearch 的功能和概念被转化为更容易识别的设置。 例如,一个 Elasticsearch 索引及其文档、映射和字段,变成了一个包含行和列的数据框,就像我们在使用 Pandas 时看到的那样。
那么 Eland 到底是什么呢?简单地说, Eland 是一个 Python 客户端和工具包,用于 Elasticsearch 中的 DataFrames 和机器学习。它具有一下特点:
- 是一个免费及开源的 Python 库
- 通过 PyPI 及 Conda Forge 来提供
- 支持 Python 3.6+, Pandas 1.0.0+ 及 Elasticsearch 7+。建议使用 Elasticsearch 7.6 及以后版本来体验所有的功能。
在传统的 data science 应用中,有两大阵营:

在 Eland 之前,这两个阵营互不联系,比如我该如何使用 Pandas 从 Elasticsearch 中得到 data frame? 如何使用 Jupyter Notebook 来查看在 Elasticsearch 中的数据?如何把 Scikit-Learn 模型部署到 Elasticsearch 中?
为了解决这两个阵营,Eland 就是这两个阵营的桥梁:
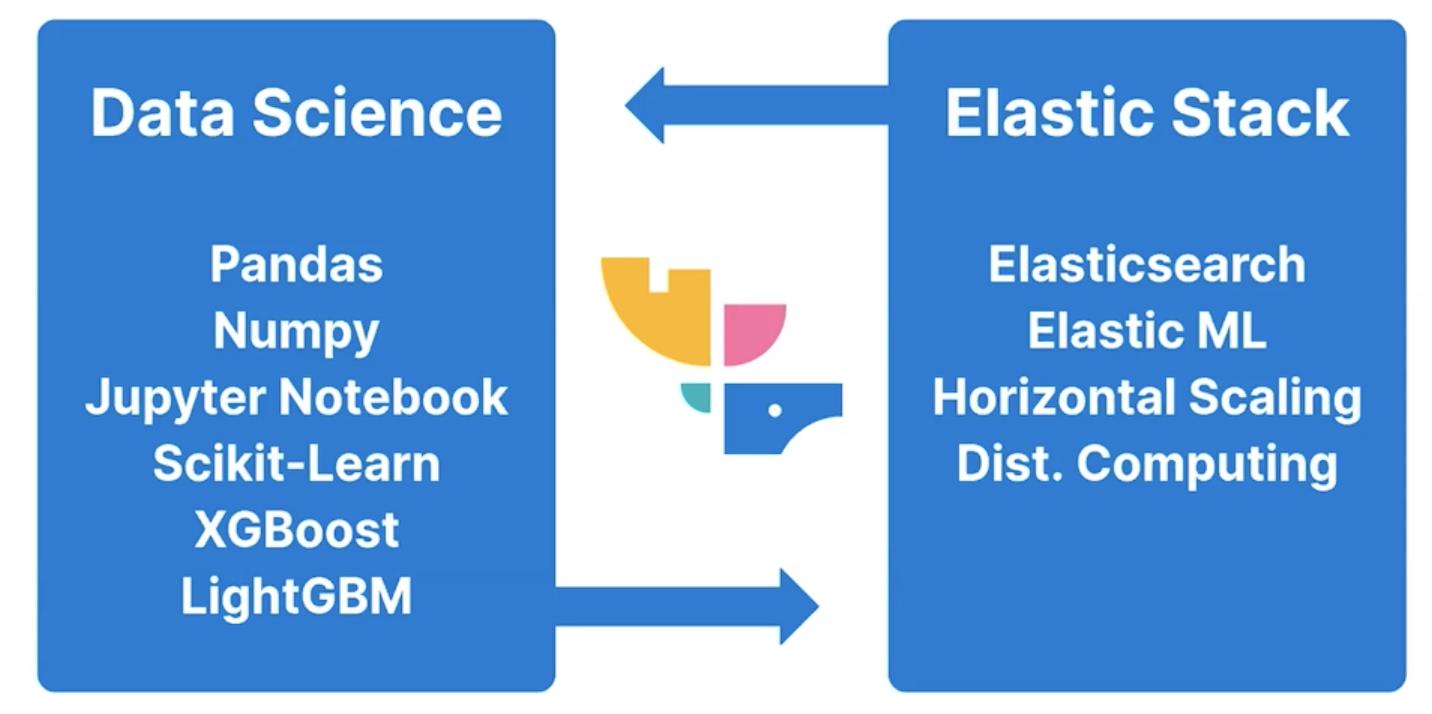
这样对于熟悉 Python 的数据科学家们,他们不用去学习一套新的开发工具及 API,直接使用他们之前熟悉的方法对 Elasticsearch 中的数据进行分析。他们不必是一个 Elasticsearch 的专家。
通过 Eland 的使用,数据科学家们可以做如下的事情:
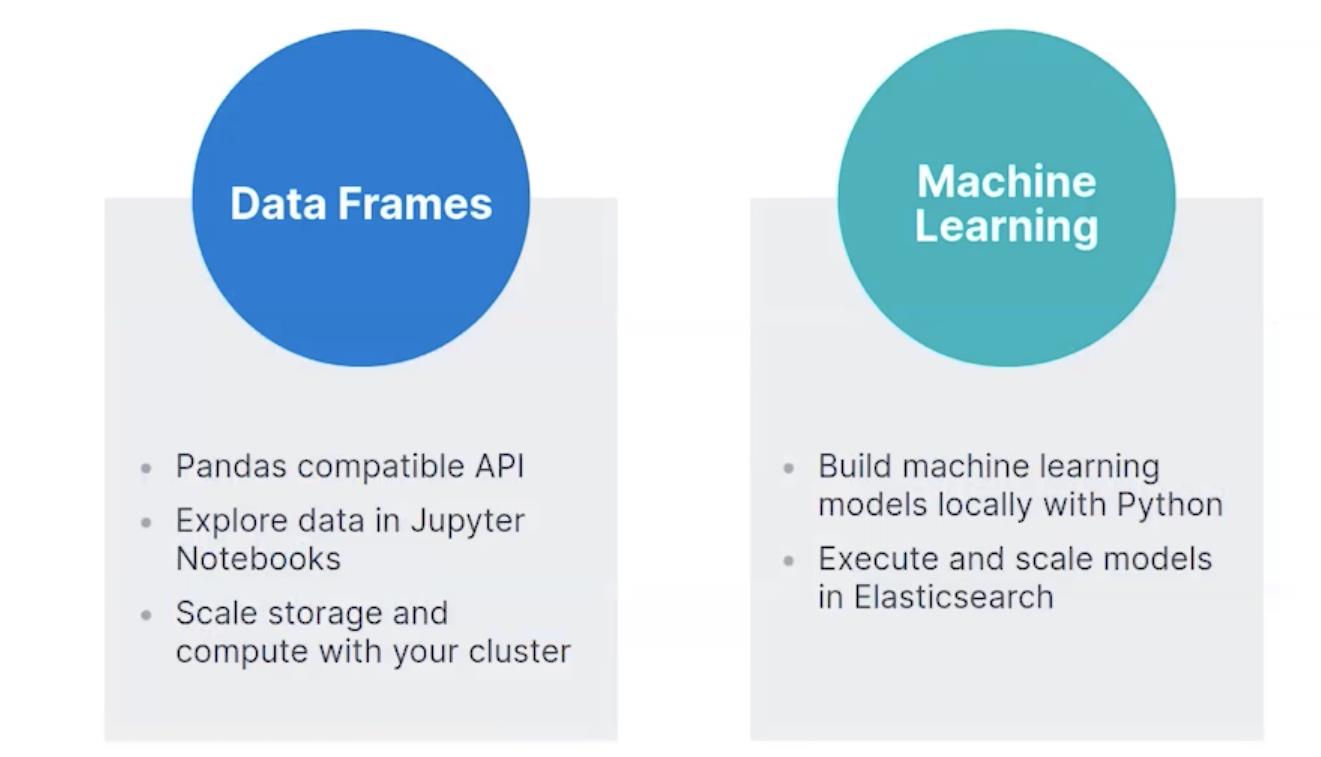
我们可以通过 Eland 的使用对数据生产 Data frames 以及使用 Python 部署自己的进行机器模型并对数据进行分析。Eland 提供一套基于 Pandas 的 data frame 数据分析子包。和传统的分析不同的是,这些数据来自于 Elasticsearch 集群而不是本地电脑的数据。这样做的好处是,我们可以充分利用 Elasticsearch 的可扩展性从而使得我们的分析达到 PB 级的数据。
动手实践
我们可以在地址 https://github.com/elastic/eland 找到 Eland 的开源项目。我们可以在 Elastic 官方网站 找到更多关于 Eland 的介绍。在今天的练习中,我将使用 Jupyter 来进行展示。
安装
我们首先在自己的电脑上安装如下的 Eland 库。我们在 terminal 中打入如下的命令:
python -m pip install eland或者使用如下的命令来进行安装:
conda install -c conda-forge eland请注意在上面介绍的 Python 及 Elasticsearch 的版本信息。
准备数据
在今天的练习中,我将使用 Kibana 自带的 flight 索引数据。打开 Kibana:
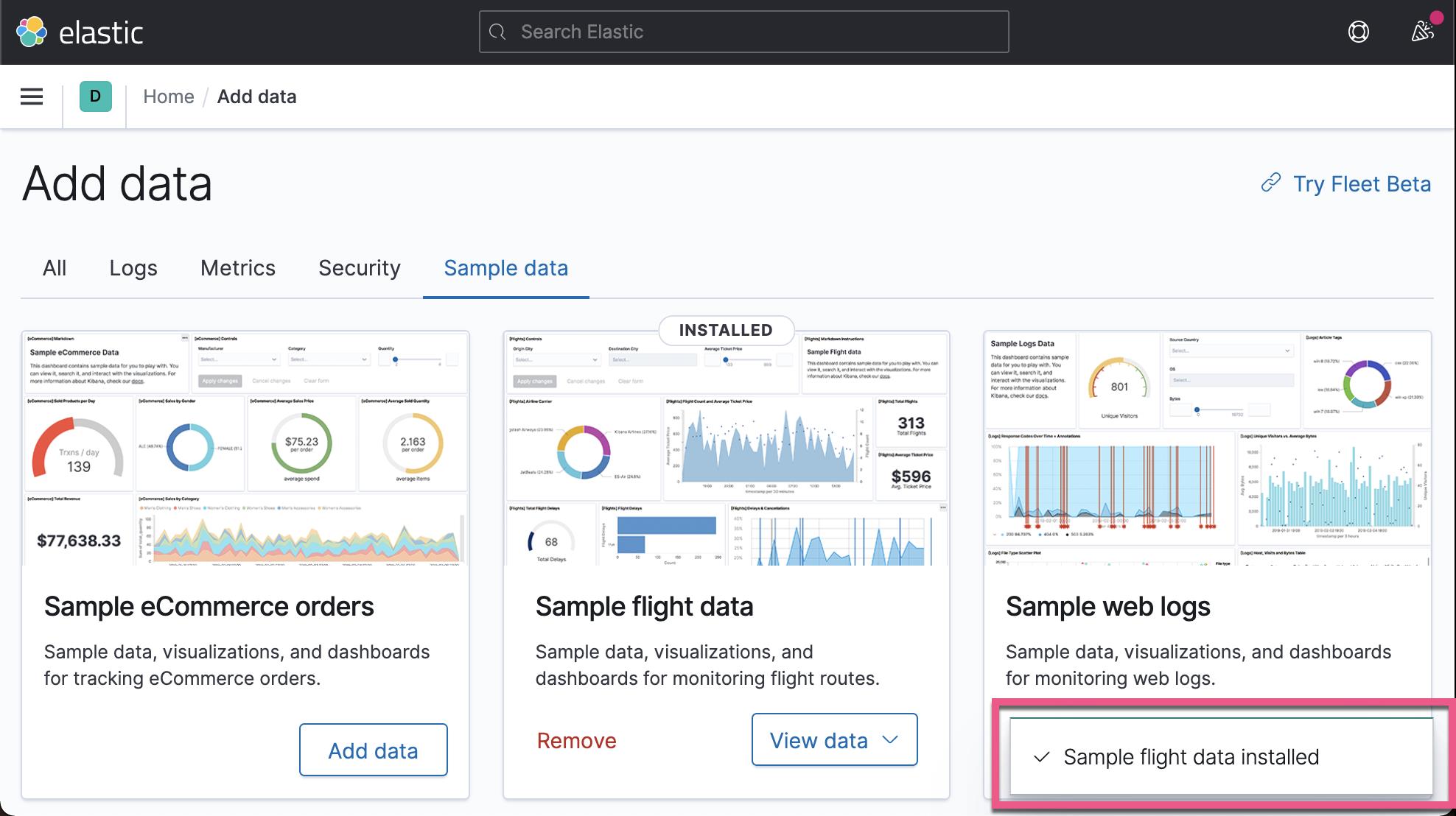
这样我们就导入了一个叫做 kibana_sample_data_flights 的索引。由于这个索引的名称比较长,为了下面的叙述的方便,我们为这个索引创建一个别名 flights:
PUT kibana_sample_data_flights/_alias/flights这样当我们对 flights 进行操作的时候,实际上也就是对 kibana_sample_data_flights 进行操作。
启动 Jupyter
我们在 terminal 中打入如下的命令:
jupyter notebook
我们创建一个新的叫做 eland 的 notebook:
import eland as ed
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from elasticsearch import Elasticsearch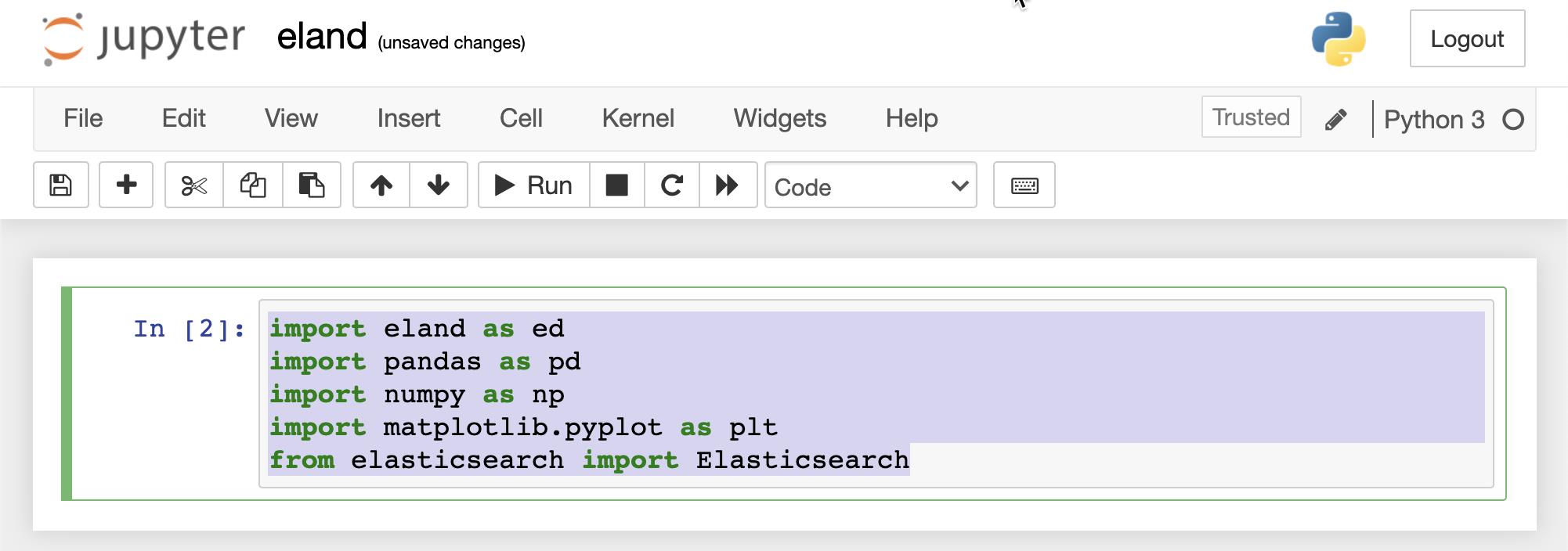
连接到 Elasticsearch
Eland 使用 Elasticsearch 低级客户端接口连接到 Elasticsearch。这个客户端支持一系列的连接及认证选项。
你可以将 elasticsearch.Elasticsearch 的实例传递给 Eland API 或包含要连接的主机的字符串:
df = ed.DataFrame('localhost:9200', 'flights')我们也可以使用如下的方法:
df = ed.read_es("localhost:9200", "flights")如果你使用 Elastic cloud 实例,那么我们可以使用如下的方法来进行连接:
from elasticsearch import Elasticsearch
es = Elasticsearch(
cloud_id="cluster-name:...",
http_auth=("elastic", "<password>")
)
df = ed.DataFrame(es, es_index_pattern="flights")Eland 里的 DataFrames
eland.DataFrame 将 Elasticsearch 索引包装在一个类似 Pandas 的 API 中,并将数据的所有处理和过滤推迟到 Elasticsearch 而不是你的本地机器。 这意味着你可以在 Elasticsearch 中从 Jupyter Notebook 处理大量数据,而不会使你的机器过载。你可以在如下的地址找到更多的信息:
我们可以使用像以前的 Panda 那样使用如下的命令来得到数据:
df.head()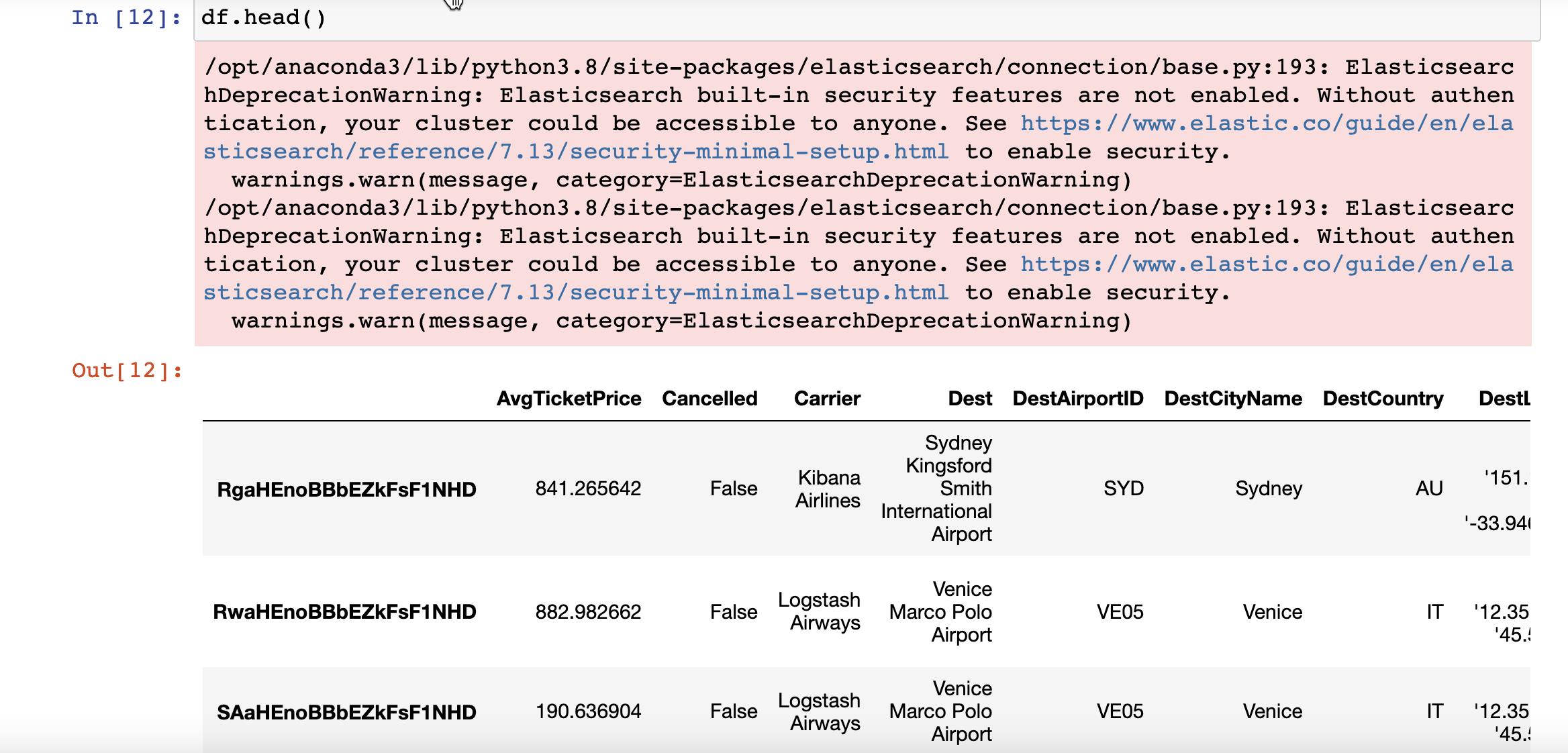
我们可以比较一下 Eland 的 data frame 和 Pandas 的 data frame 的比较:
type(df)
pandas_df = ed.eland_to_pandas(df)
我们来比较一下它们的 columns:

我们比较一下两种 data frame 的数据类型:
df.dtypes
pandas_df.dtypes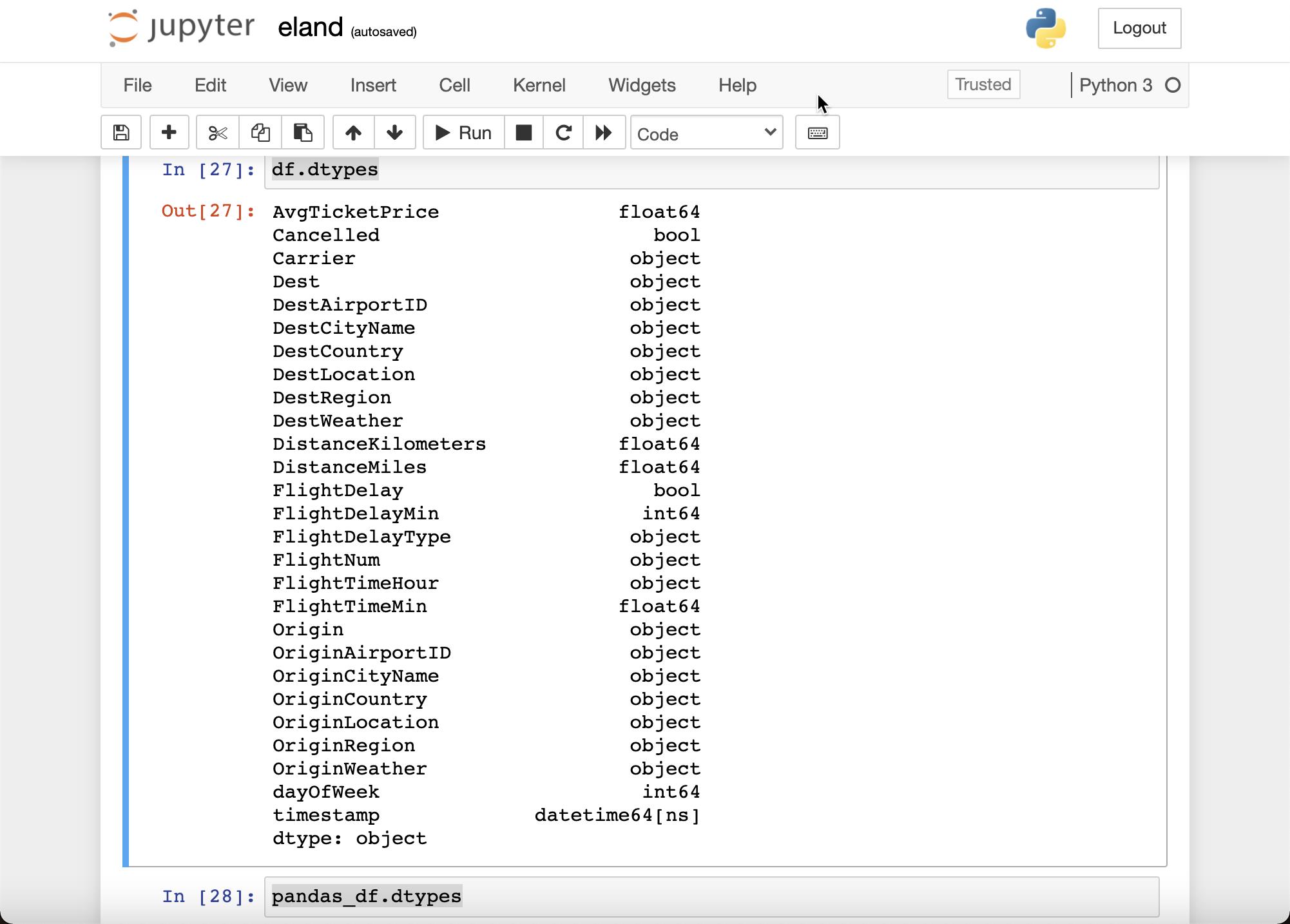
我们可以从输出中看到,它们都是一样的。
我们也可以使用如下的方法来得到有多少数据:
df.shape
通过 df.info() 来产科信息:
df.info()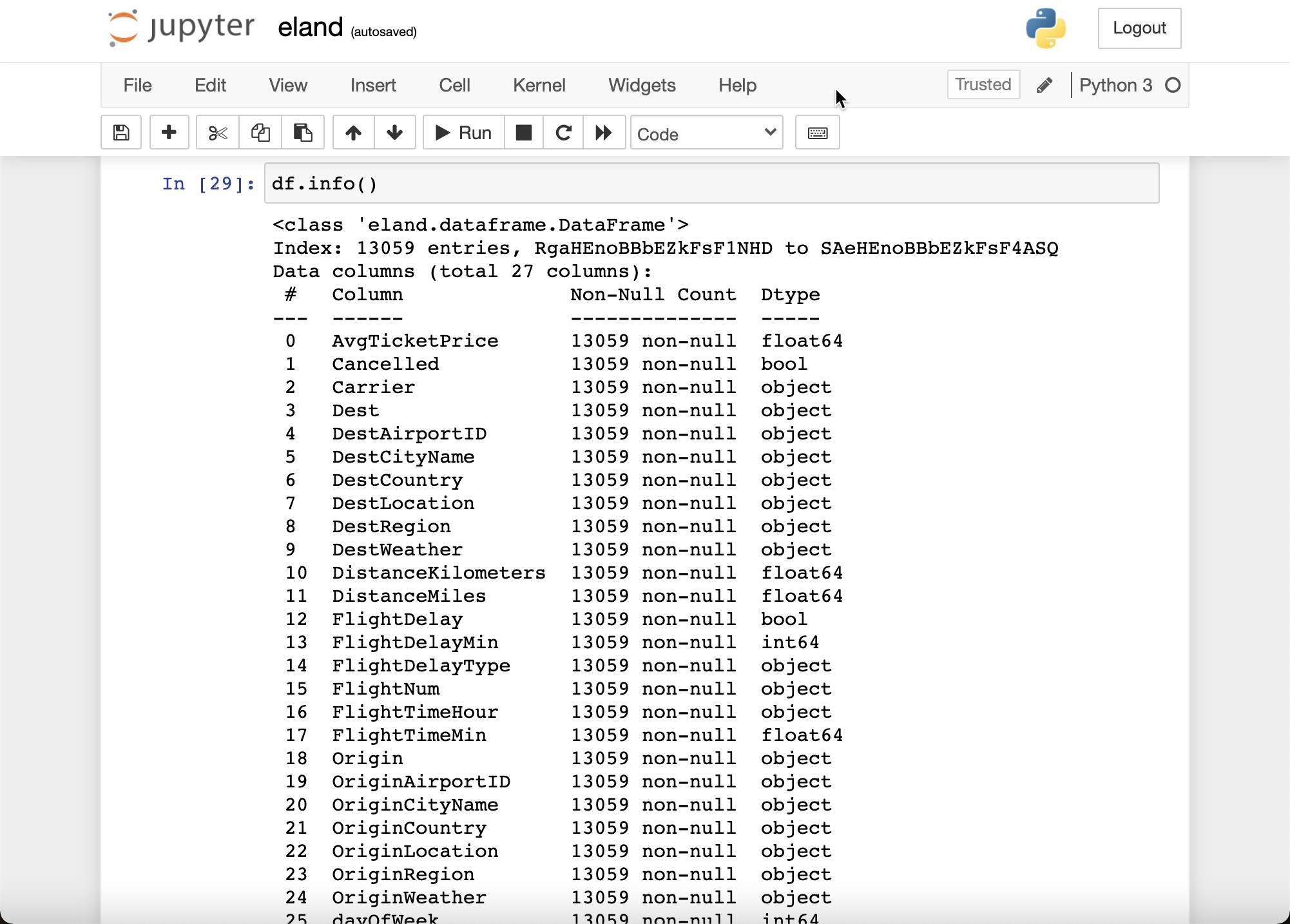
我们可以使用如下的方法来对数据进行过滤:
df[(df.Carrier=="Kibana Airlines") & (df.AvgTicketPrice > 900.0) & (df.Cancelled == True)].head()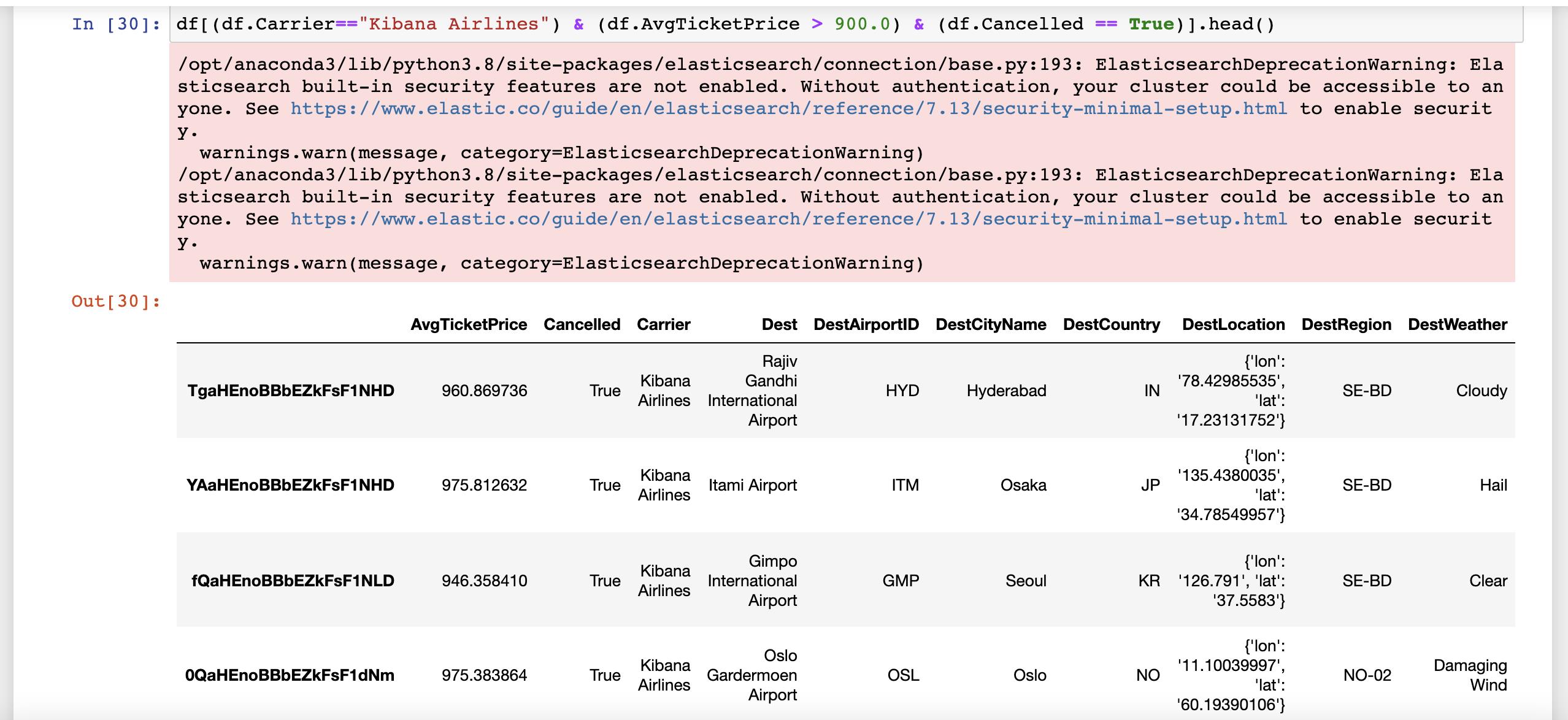
上面的搜索实际上是把 Pandas API 转换为 Query DSL:

我们可以使用如下的方法来对索引数据进行聚合:
df[['DistanceKilometers', 'AvgTicketPrice']].aggregate(['sum', 'min', 'std'])
我们可以使用如下的接口来对 flights 进行全文搜索:
# define the full-text queru
query = {
"query_string": {
"fields": ["OriginWeather"],
"query": "Sunny OR Hail"
}
}
# using full-text search capabilities with Eland:
text_search_df = df.es_query(query)
# visualizing price of products for each manufacturer using pandas column syntax:
text_search_df[['AvgTicketPrice','DistanceMiles']]上面显示:

我们可以通过如下的方法来对数据进行统计:
hist = df.get("AvgTicketPrice").hist()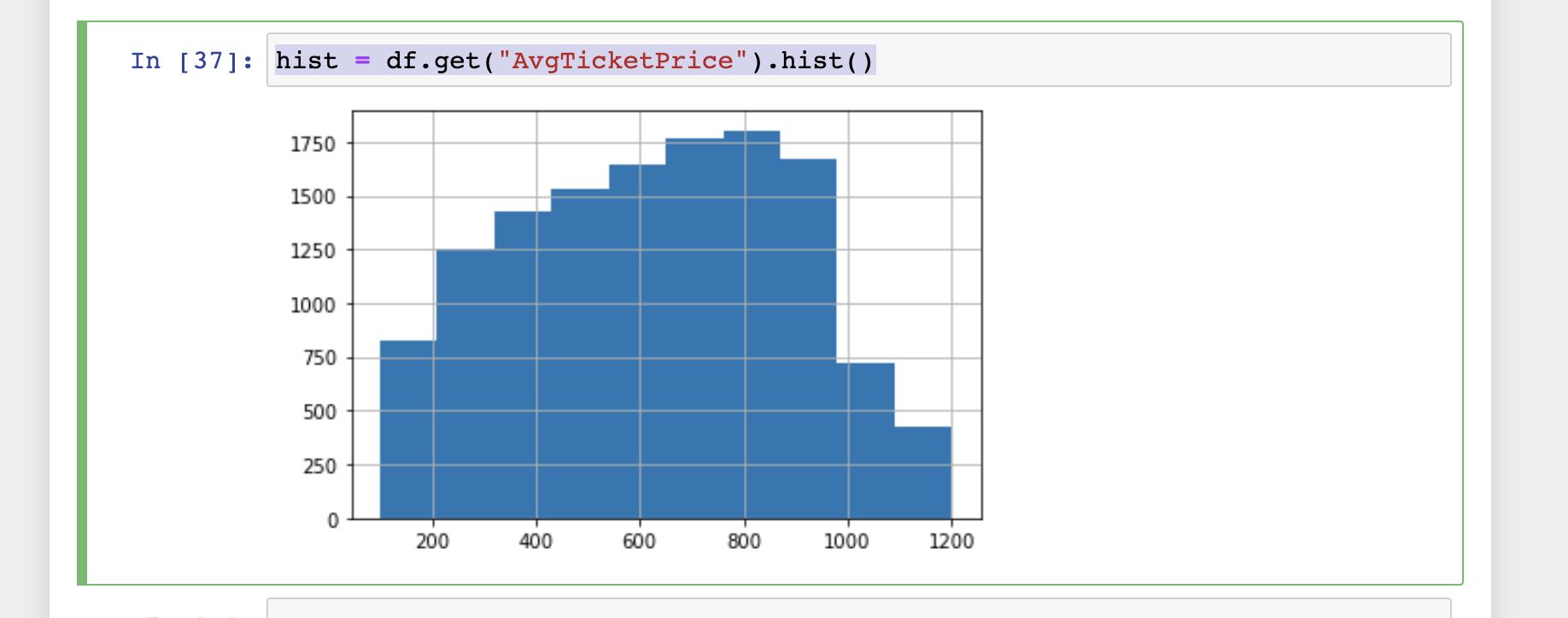
我们回到 Kibana 中重新定义一个 alias,如同上面我们对 fligths 的定义一样,不过稍微不同的是我们这次使用过滤器的方法来生成一个 alias。我们想找出 DestCountry 是 CN,并且 AvgTicketPrice 在 500 到 800 中的所有数据。我们可以在 Dev Tools 定义如下的 alias:
PUT kibana_sample_data_flights/_alias/china_price_range
{
"filter": [
{
"match": {
"DestCountry": "CN"
}
},
{
"range": {
"AvgTicketPrice": {
"gte": 500,
"lte": 800
}
}
}
]
}和上面的方法类似,我们使用如下的方法来定义 df_filtered:
df_filtered = ed.DataFrame('localhost:9200', 'china_price_range')
hist = df_filtered.get("AvgTicketPrice").hist()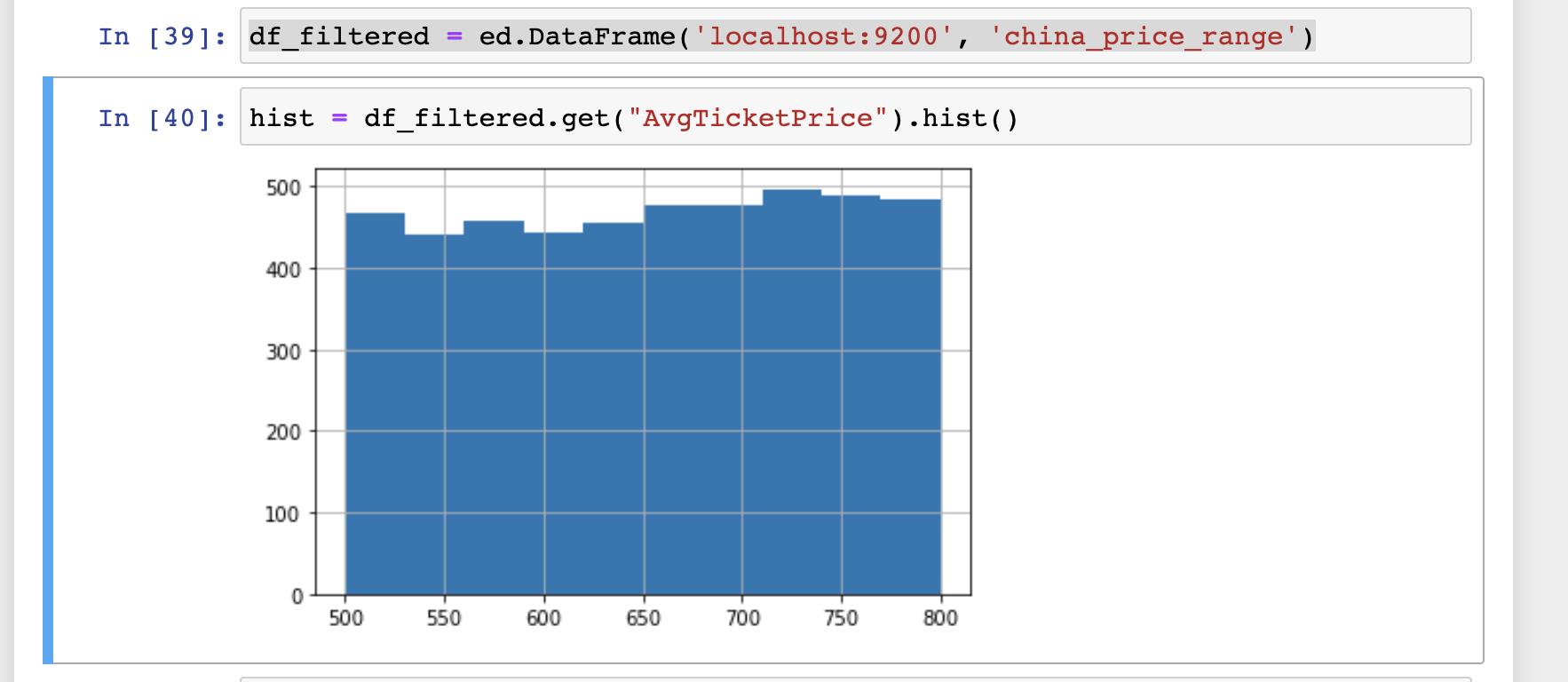
我们接下来在 Kibana 中创建一个 transform。你们可以参考我之前的文章 “Transforms 介绍”。
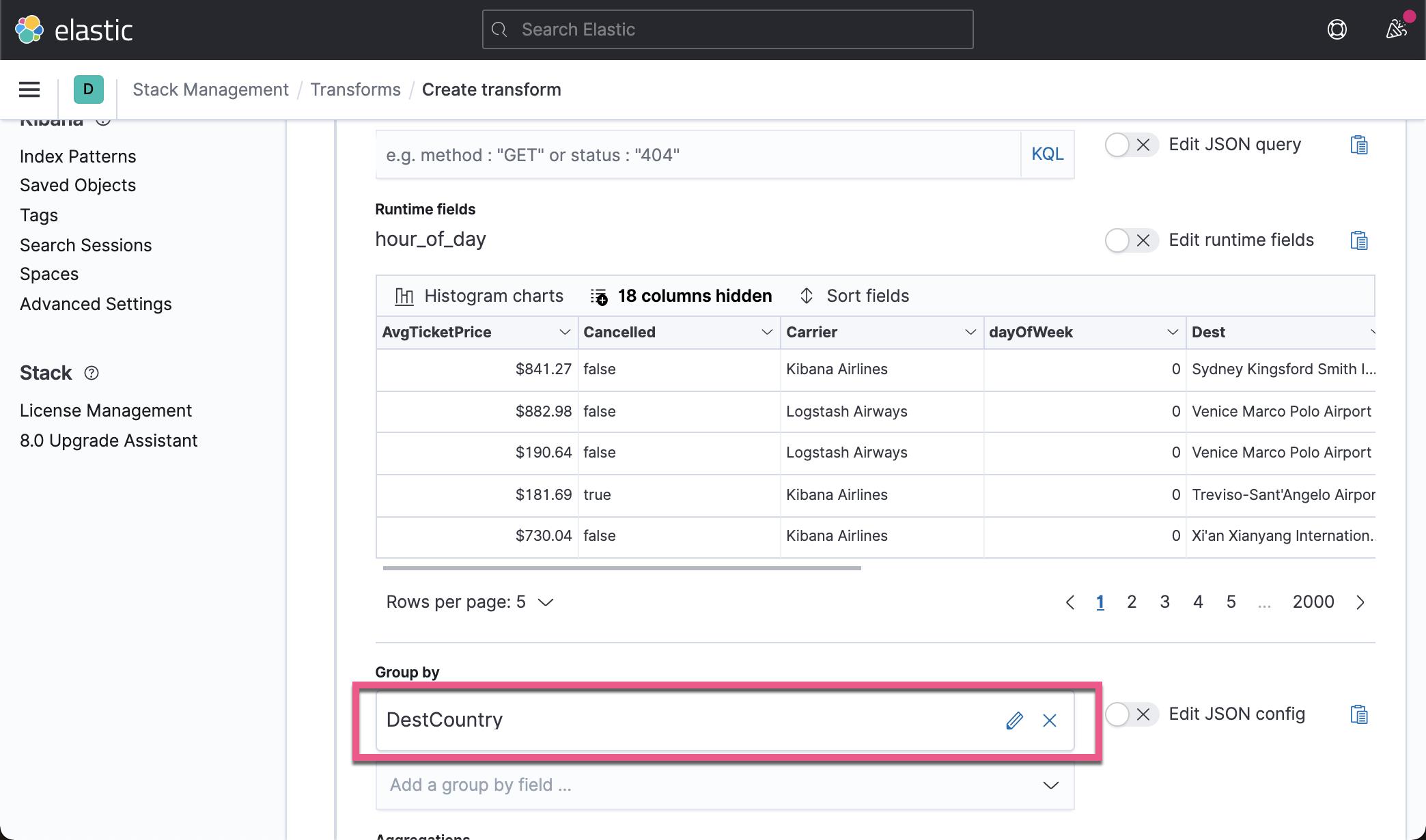
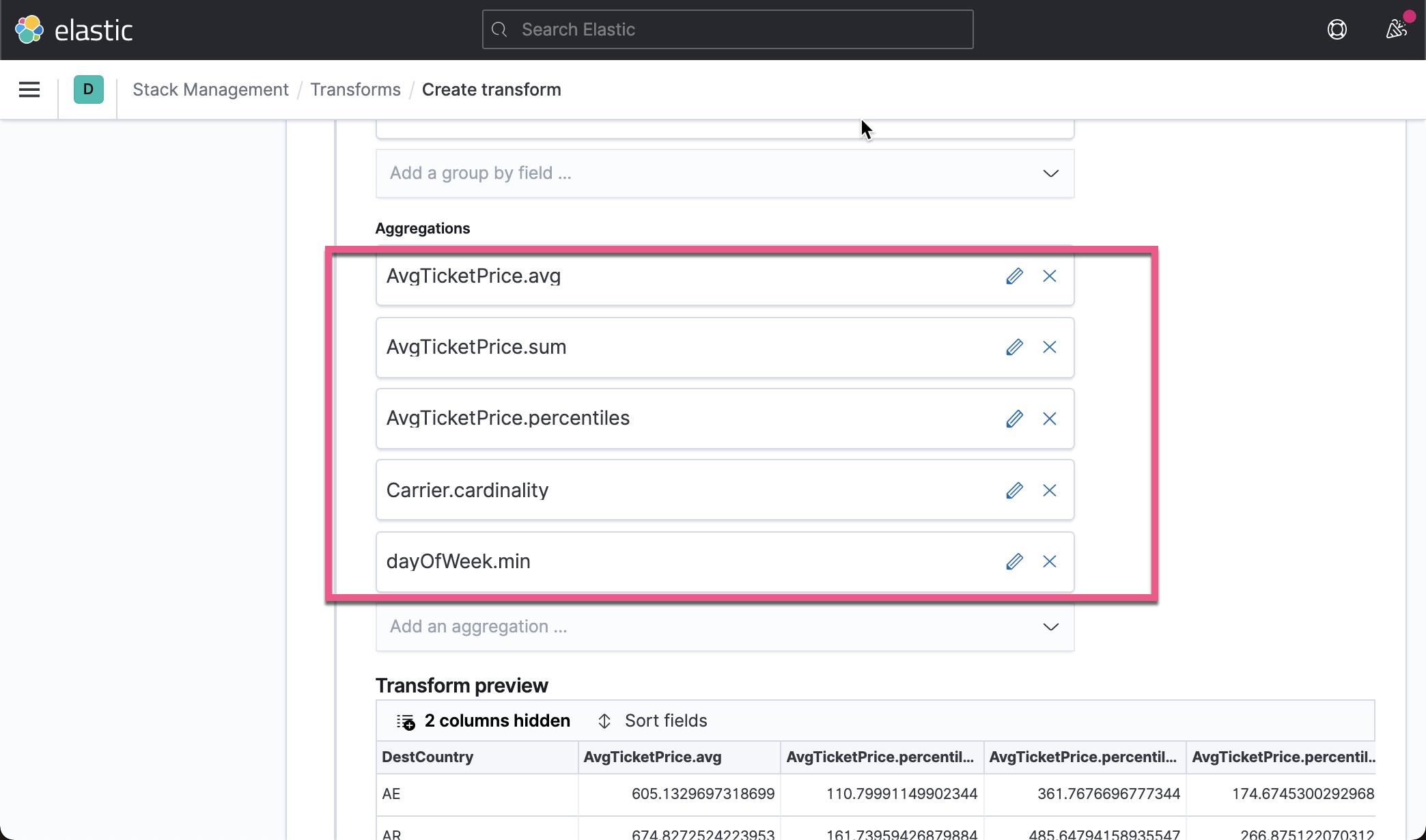
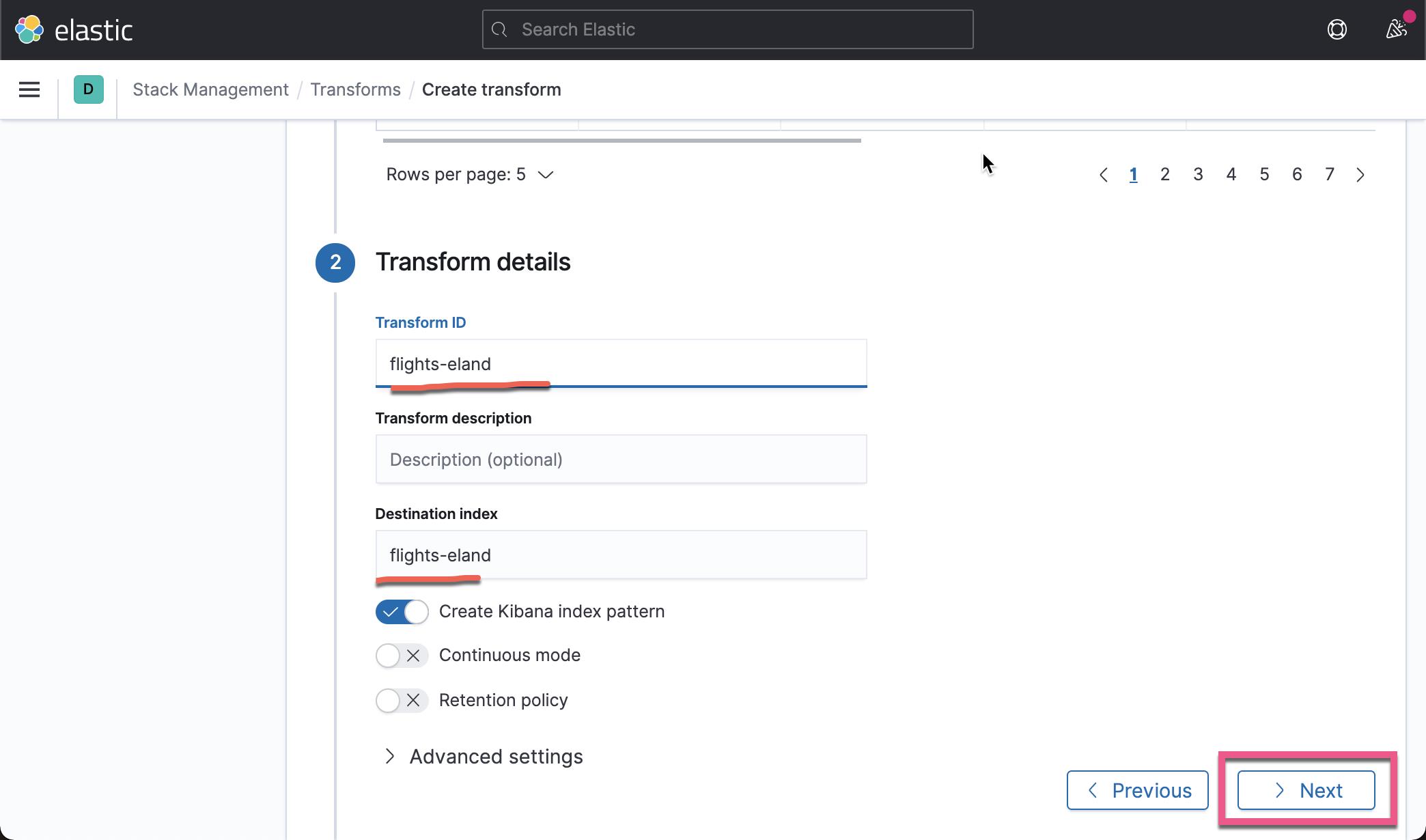
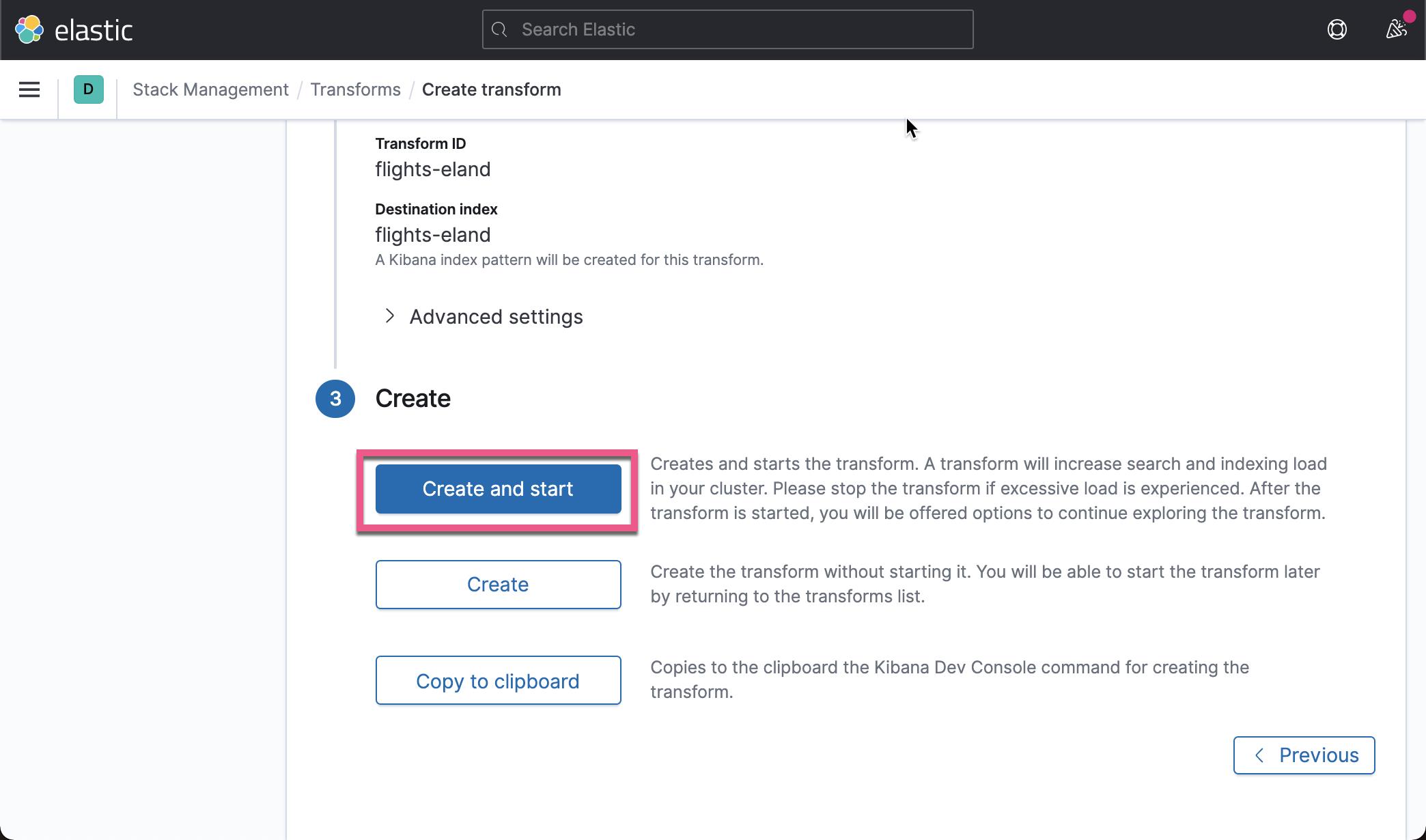
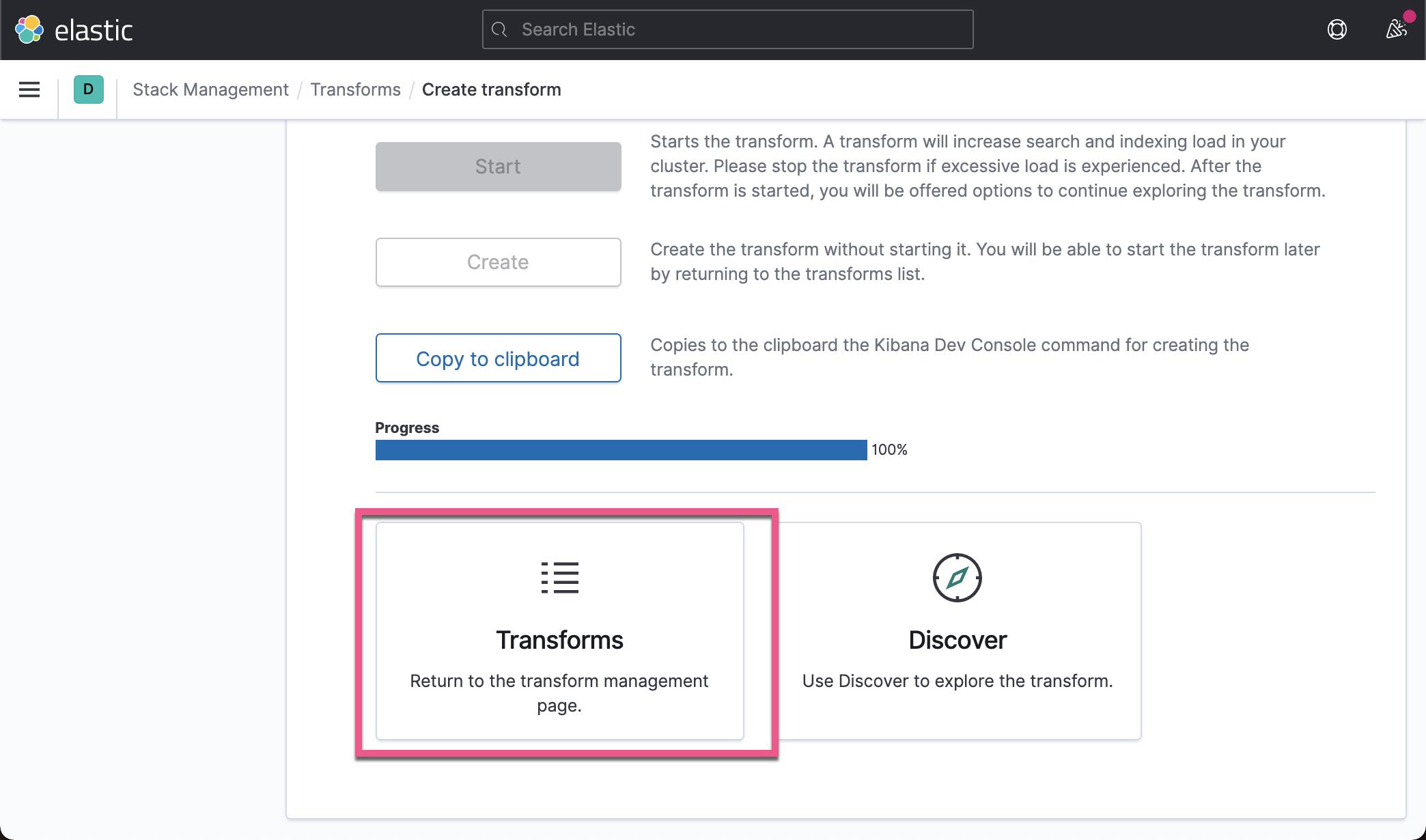
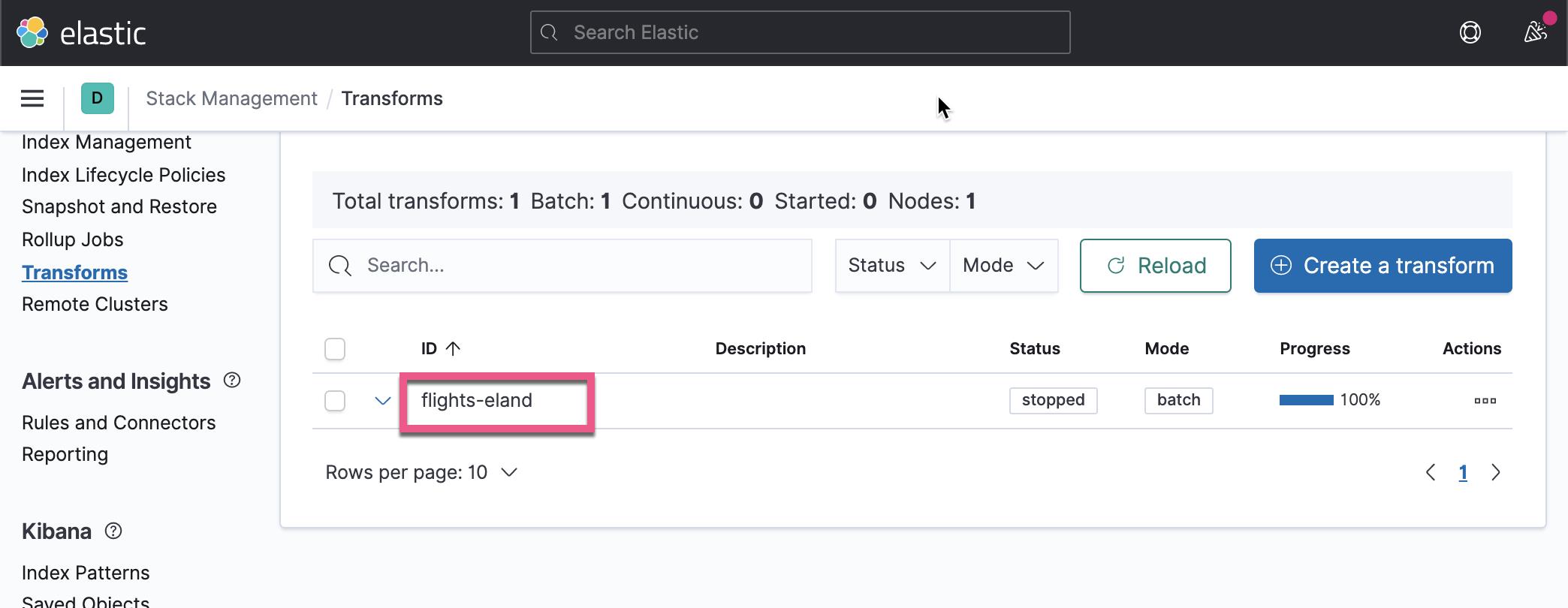
在上面,我们已经创建了一个叫做 flights-eland 的 transform。上面显示已经完成了 100% 。
我们在 Jupyter 中打入如下的命令:
df_transform = ed.DataFrame('localhost:9200', 'flights-eland')
df_transform.head()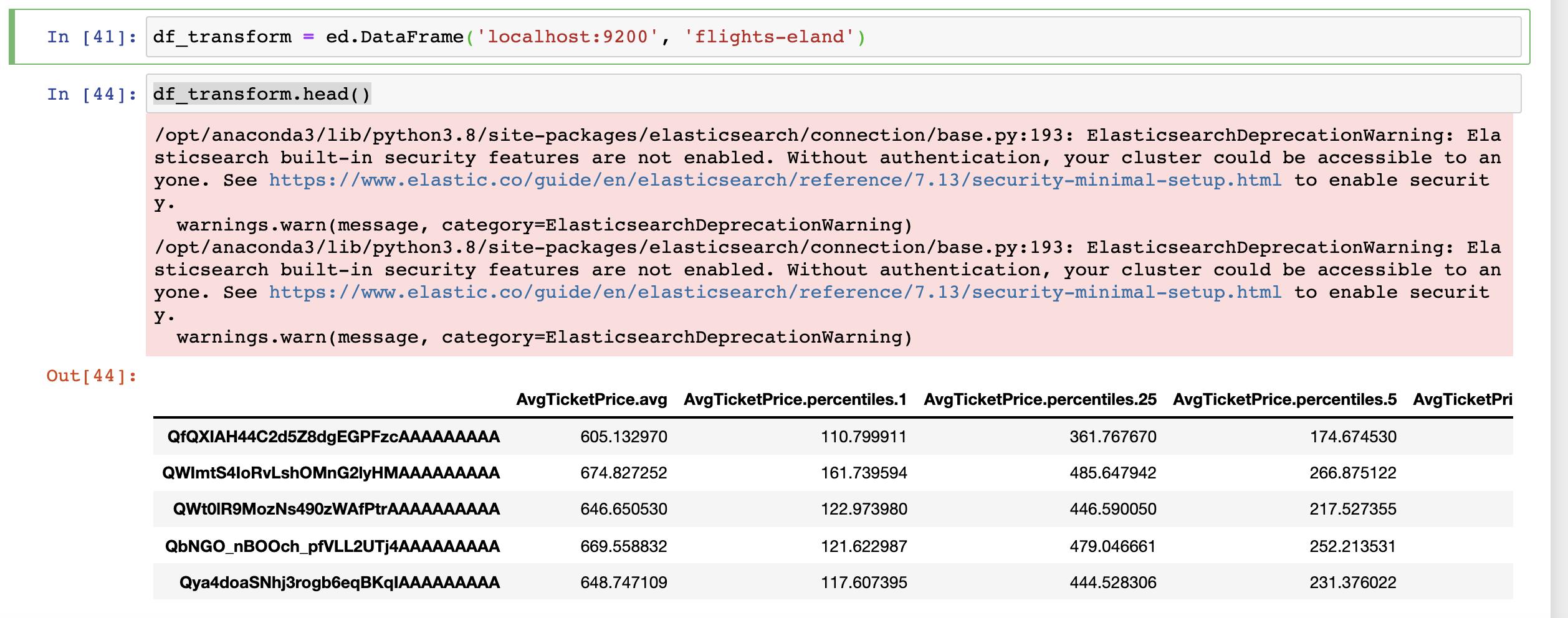
在上面,我们把在 Kibana 中创建的 flights-eland 这个 transform 传入到 data frame 中。从上面我们可以看得出来 data frame 里的数据。
我们甚至可以直接在 Kibana 中创建一些 Data Frame Analytics 任务:
并把这个任务传入到 Eland 的 Data Frame 的创建中,比如:
flights_outliers = ed.DataFrame("localhost:9200", "<Your analytics job>")
fights_outliers.head()在这里我就不赘述了。
Eland 中的机器学习
Eland 允许将来自 scikit-learn、XGBoost 和 LightGBM 库的训练模型进行序列化并用作 Elasticsearch 中的推理模型。更多资料请在一下链接查找:
参考:
以上是关于Elasticsearch:Elasticsearch 使得 Data Science 变得更简单了 - Eland的主要内容,如果未能解决你的问题,请参考以下文章