数据库系统概念笔记——第十二章:查询处理
Posted 叶卡捷琳堡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库系统概念笔记——第十二章:查询处理相关的知识,希望对你有一定的参考价值。
文章目录
第十二章:查询处理
12.1 概述
查询处理的基本步骤包括
- 语法分析与翻译
- 优化
- 执行
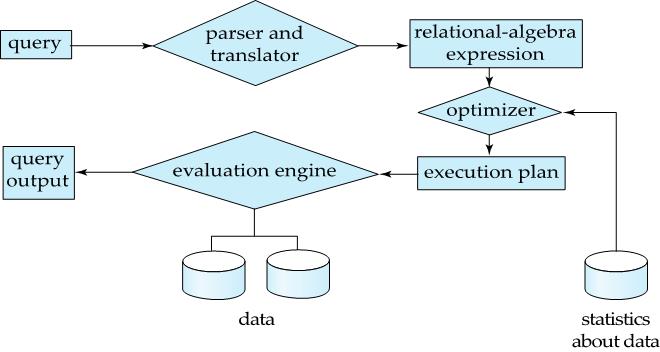
解析和翻译
语法分析器检查语法,验证关系。把查询语句翻译成系统的内部表示形式,即关系代数
执行
查询执行引擎接收一个查询执行计划,执行该计划并把结果返回给查询
优化
比如对于如下sql语句
select salary
from instructor
where salary < 75000
可以被翻译成下面两个关系代数表达式中的任意一个
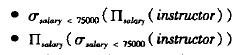
对于每一种,都可以使用不同的算法进行执行
执行一个查询,不仅要提供关系代数表达式,还要对表达式加上注释来说明如何执行每个操作。
加了“如何执行”注释的关系代数被称为计算原语
用于执行一个查询的原语操作序列称为查询执行计划或查询计算计划
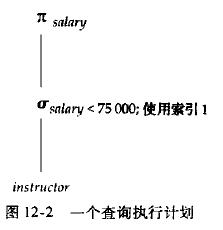
查询执行引擎接受一个查询执行计划,执行该计划并把结果返回给查询
查询优化:在所有等效执行计划中选择具有最小查询执行代价的计划
12.2 查询代价的度量
数据库中可以存在多种可能的查询计算计划,重要的是能估计它们的代价来对不同的计划做比较,并选择最佳方案
因为磁盘存取比CPU时间大得多,因此我们忽略CPU时间,仅仅用磁盘存取代价来度量查询执行计划的代价
我们用传输磁盘块数以及搜索磁盘次数来度量查询计算计划的代价。
设磁盘子系统传输一个块的数据平均消耗tT秒,磁盘块平均访问时间为ts秒,则一次传输b个块以及执行S次磁盘搜索将消耗
btT + Sts秒
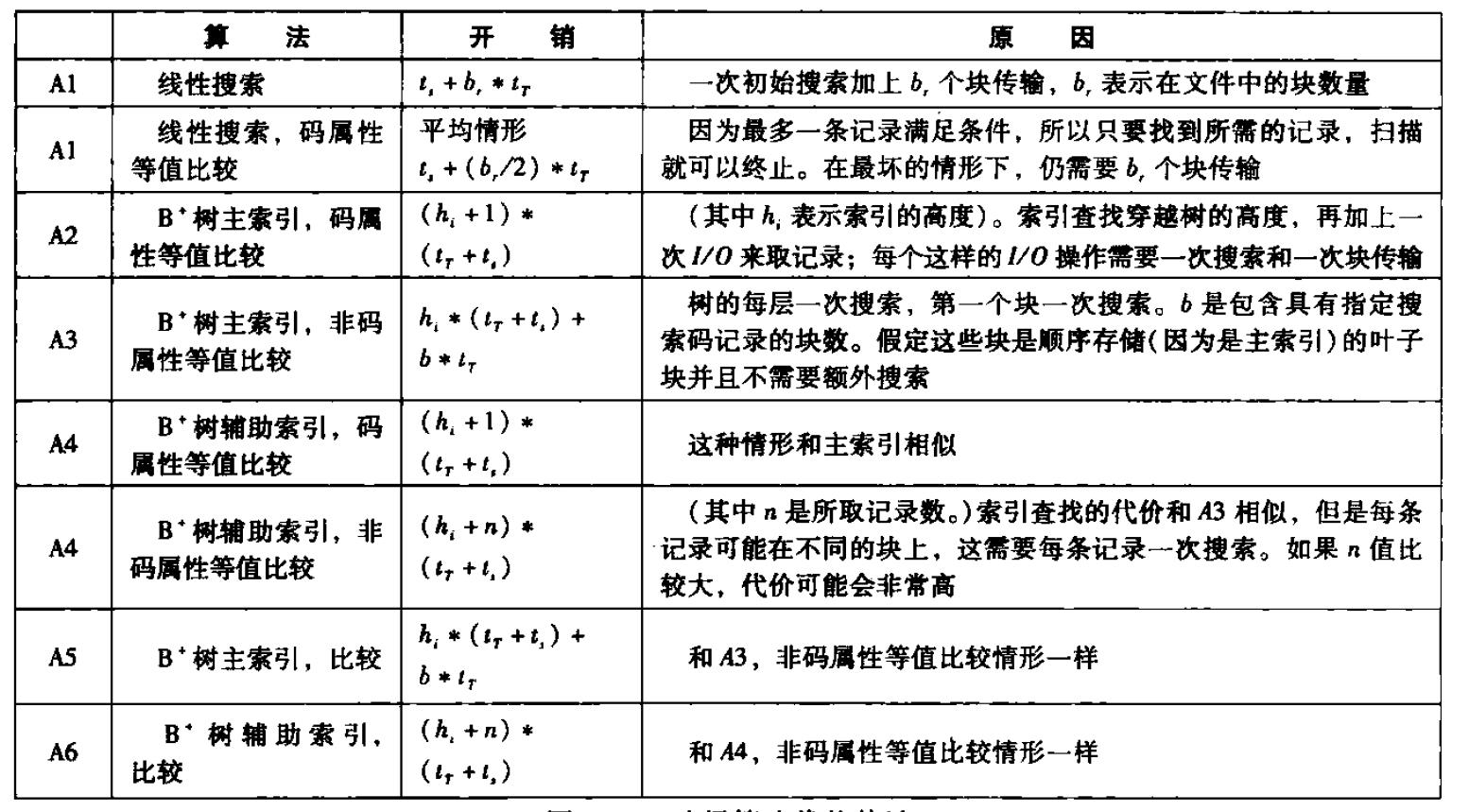
12.3 选择运算
12.3.1 使用文件和索引的选择
具体的时间开销如图所示
12.3.2 涉及比较的选择
对于形如
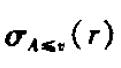
的选择,可以使用线性搜索,也可以使用索引实现选择运算
A5(主索引,比较)

A6(辅助索引,比较)

12.5 连接运算
用等值连接来表示形如
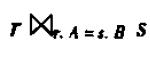
的连接。其中A,B分别为关系r与关系s的属性或属性组
使用student和takes做自然连接作为例子
假设这两张表有以下信息

12.5.1 嵌套循环连接
嵌套循环连接是一个计算两个关系连接的算法,这个算法由两个for循环构成,因此被称为嵌套循环连接
这种算法称r为外层关系,s为内层关系

nr:外层关系元组数量
bs:内层关系快数量

12.5.2 块嵌套循环连接
块嵌套循环连接使用块的方式,而不是元组的方式处理关系。内层关系中的每一块与外层关系中的每一块形成一对。在每个块对中,一个块中的每个元组与另一块的每个元组形成元组对,得到全体元组对


12.5.3 索引嵌套循环连接
在嵌套循环连接的内层循环上若有索引,则可以用索引替代文件扫描。对于外层关系r的每一个元组tr,可以利用索引查找s中和tr满足连接条件的元组

归并连接和散列连接这里略去
12.7 表达式计算
之前只研究了单个运算如何执行,现在考虑包含多个运算的关系代数表达式
计算一个完整表达式树的两种方法
- 物化:输入一个关系或已完成的计算产生一个表达式的结果,并在磁盘中物化它,重复该过程
- 流水线:一个正在执行的操作的部分结果送到流水线的下一个操作,使得两操作可同时进行
12.7.1 物化
直观地理解如何计算一个表达式——看运算符树
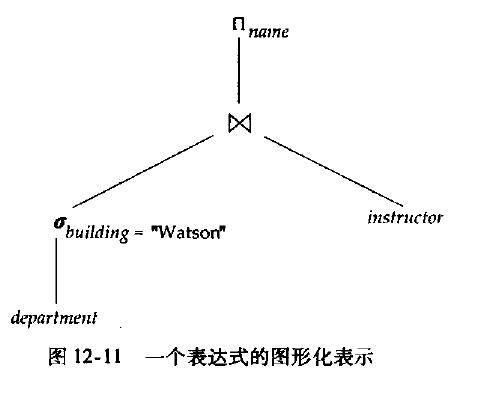
采用物化方法时,我们从表达式的最底层开始(树的底部),这里是department的选择运算。底层运算的输入是数据库中的关系。对运算的每个中间结果创建(物化)临时关系,然后用于上一层计算
在任何情况下,物化计算都是永久适用的。但是将结果写入磁盘和读取它们的代价很大
双缓冲技术:使用两个缓冲区,一个用于执行算法,另一个用于写出结果
12.7.2 流水线
比如在前面的表达式树中,不存储中间结果,直接传递元组到连接运算
流水线比物化的代价小很多,但流水线不总是可行的,比如排序,散列连接时,就不能用流水线
以上是关于数据库系统概念笔记——第十二章:查询处理的主要内容,如果未能解决你的问题,请参考以下文章