英文垃圾邮件分类深度学习篇——CNNRNNLSTM
Posted weixin_46570668
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英文垃圾邮件分类深度学习篇——CNNRNNLSTM相关的知识,希望对你有一定的参考价值。
英文垃圾邮件分类深度学习篇——CNN、RNN、LSTM
CNN
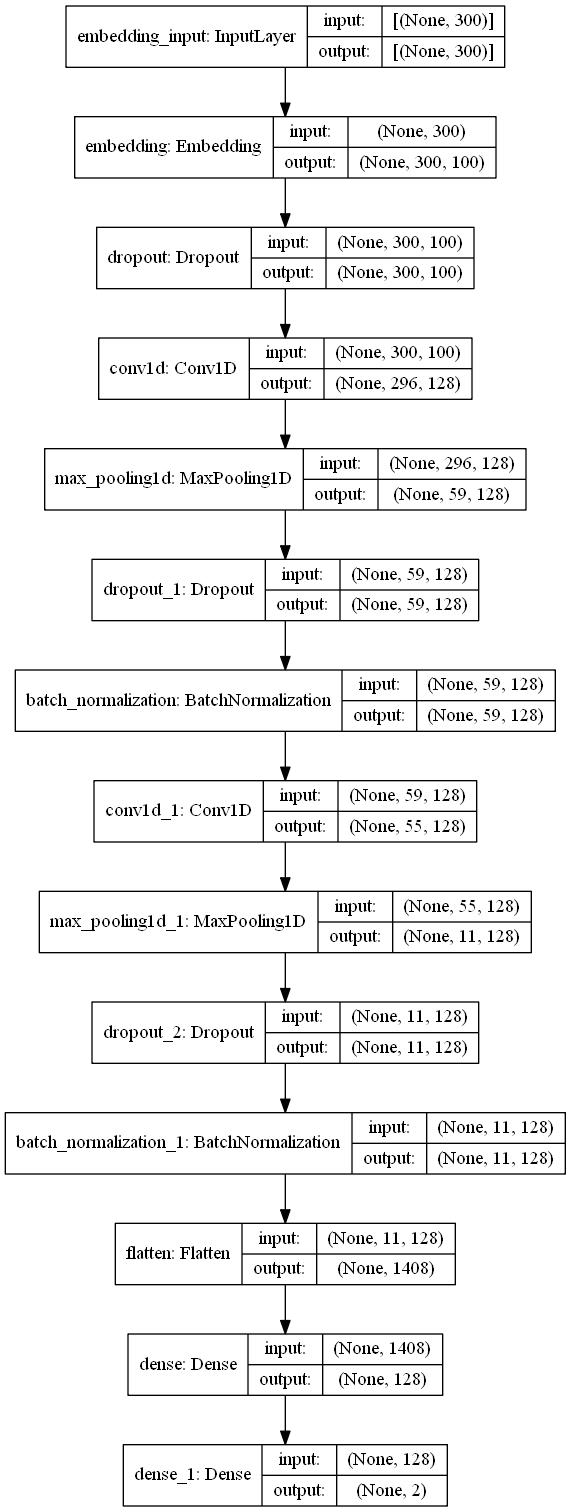
我们来搭建一个如图所示的卷积神经网络
输入序列长度为300;
嵌入的维度设置为100;
卷积层卷积核设置为5*5;
最大池化层步幅设置为5;
Flatten层把多维的输入一维化;
全连接层完成分类;
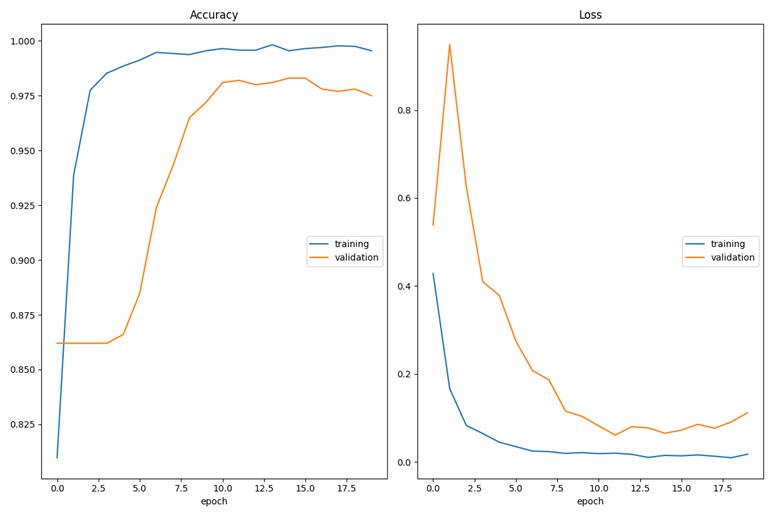
 代码非常简单,显示数据处理,然后模型搭建,然后训练20轮。
代码非常简单,显示数据处理,然后模型搭建,然后训练20轮。
import pandas as pd
import numpy as np
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Dense, Input, Flatten, Dropout,BatchNormalization
from keras.layers import Conv1D, MaxPooling1D, Embedding
from keras.models import Sequential
from keras.utils.vis_utils import plot_model
from livelossplot import PlotLossesKeras
import re
import os
os.environ["PATH"] += os.pathsep +'C:\\Program Files\\Graphviz\\bin'
# 读取数据
data = pd.read_csv('spam.csv', encoding = "ISO-8859-1")
# 去除无用数据,后3列是无用数据
data = data[['v1', 'v2']]
# 修改表头信息
data = data.rename(columns={"v1":"label","v2":"text"})
# 去除标点符号及两个以上的空格
data['text'] = data['text'].apply(lambda x:re.sub('[!@#$:).;,?&]', ' ', x.lower()))
data['text'] = data['text'].apply(lambda x:re.sub(' ', ' ', x))
# 单词转换为小写
data['text'] = data['text'].apply(lambda x:" ".join(x.lower() for x in x.split()))
# 去除停止词 ,如a、an、the、高频介词、连词、代词等
stop = stopwords.words('english')
data['text'] = data['text'].apply(lambda x: " ".join(x for x in x.split() if x not in stop))
# 分词处理,希望能够实现还原英文单词原型
st = PorterStemmer()
data['text'] = data['text'].apply(lambda x: " ".join([word for word in x.split()]))
#data['text'] = data['text'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
#分出训练集和测试集
train=data[:5000]
test=data[5000:]
# 每个序列的最大长度,多了截断,少了补0
max_sequence_length = 300
#只保留频率最高的前20000个词
num_words = 20000
# 嵌入的维度
embedding_dim = 100
# 找出经常出现的单词,分词器
tokenizer = Tokenizer(num_words=num_words)
tokenizer.fit_on_texts(train.text)
train_sequences = tokenizer.texts_to_sequences(train.text)
test_sequences = tokenizer.texts_to_sequences(test.text)
# dictionary containing words and their index
word_index = tokenizer.word_index
# print(tokenizer.word_index)
# total words in the corpus
print('Found %s unique tokens.' % len(word_index))
# get only the top frequent words on train
train_x = pad_sequences(train_sequences, maxlen=max_sequence_length)
# get only the top frequent words on test
test_x = pad_sequences(test_sequences, maxlen=max_sequence_length)
print(train_x.shape)
print(test_x.shape)
def lable_vectorize(labels):
label_vec = np.zeros([len(labels), 2])
for i, label in enumerate(labels):
if str(label) == 'ham':
label_vec[i][0] = 1
else:
label_vec[i][1] = 1
return label_vec
train_y = lable_vectorize(train['label'])
test_y = lable_vectorize(test['label'])
'''
num_words = 20000
embedding_dim = 100
'''
model = Sequential()
model.add(Embedding(num_words,
embedding_dim,
input_length=max_sequence_length))
#model.add(Embedding(max_sequence_length,128))
model.add(Dropout(0.5))
model.add(Conv1D(128, 5, activation='relu'))
model.add(MaxPooling1D(5))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Conv1D(128, 5, activation='relu'))
model.add(MaxPooling1D(5))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(2, activation='softmax'))
plot_model(model, to_file='model3.png',show_shapes='True')
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
model.fit(train_x, train_y,
batch_size=64,
epochs=20,
validation_split=0.2,
callbacks=[PlotLossesKeras()])
print(model.evaluate(test_x, test_y))
# prediction on test data
predicted=model.predict(test_x)
print(predicted)
#模型评估
import sklearn
from sklearn.metrics import precision_recall_fscore_support as score
precision, recall, fscore, support = score(test_y,predicted.round())
print('precision: {}'.format(precision))
print('recall: {}'.format(recall))
print('fscore: {}'.format(fscore))
print('support: {}'.format(support))
print("############################")
print(sklearn.metrics.classification_report(test_y,predicted.round()))

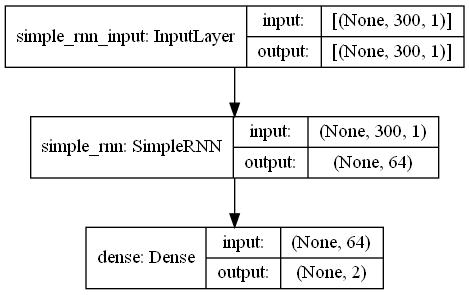
RNN
其实这些神经网络使用keras非常容易搭建。
import tensorflow as tf
import numpy as np
import pandas as pd
from tensorflow import keras
import os
import re
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from keras.utils.vis_utils import plot_model
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
os.environ["PATH"] += os.pathsep +'C:\\Program Files\\Graphviz\\bin'
#=============================================================================================
#=============================================================================================
# 读取数据
data = pd.read_csv('spam.csv', encoding = "ISO-8859-1")
# 去除无用数据,后3列是无用数据
data = data[['v1', 'v2']]
# 修改表头信息
data = data.rename(columns={"v1":"label","v2":"text"})
# 去除标点符号及两个以上的空格
data['text'] = data['text'].apply(lambda x:re.sub('[!@#$:).;,?&]', ' ', x.lower()))
data['text'] = data['text'].apply(lambda x:re.sub(' ', ' ', x))
# 单词转换为小写
data['text'] = data['text'].apply(lambda x:" ".join(x.lower() for x in x.split()))
# 去除停止词 ,如a、an、the、高频介词、连词、代词等
stop = stopwords.words('english')
data['text'] = data['text'].apply(lambda x: " ".join(x for x in x.split() if x not in stop))
# 分词处理,希望能够实现还原英文单词原型
st = PorterStemmer()
data['text'] = data['text'].apply(lambda x: " ".join([word for word in x.split()]))
#data['text'] = data['text'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
#分出训练集和测试集
train=data[:5000]
test=data[5000:]
# 每个序列的最大长度,多了截断,少了补0
max_sequence_length = 300
#只保留频率最高的前20000个词
num_words = 20000
# 嵌入的维度
embedding_dim = 100
# 找出经常出现的单词,分词器
tokenizer = Tokenizer(num_words=num_words)
tokenizer.fit_on_texts(train.text)
train_sequences = tokenizer.texts_to_sequences(train.text)
test_sequences = tokenizer.texts_to_sequences(test.text)
# dictionary containing words and their index
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
# get only the top frequent words on train
train_x = pad_sequences(train_sequences, maxlen=max_sequence_length)
# get only the top frequent words on test
test_x = pad_sequences(test_sequences, maxlen=max_sequence_length)
print(train_x.shape)
print(test_x.shape)
# 标签向量化
# [0,1]: ham;[1,0]:spam
def lable_vectorize(labels):
label_vec = np.zeros([len(labels), 2])
for i, label in enumerate(labels):
if str(label) == 'ham':
label_vec[i][0] = 1
else:
label_vec[i][1] = 1
return label_vec
train_y = lable_vectorize(train['label'])
test_y = lable_vectorize(test['label'])
X_train = np.reshape(train_x , (train_x .shape[0], train_x .shape[1], 1))
X_test = np.reshape(test_x, (test_x .shape[0], test_x .shape[1], 1))
print("加载数据完成")
#=============================================================================================
#=============================================================================================
# 数据长度 一行有28个像素
input_size = 28
# 序列的长度
time_steps = 28
# 隐藏层block的个数
cell_size = 64
model = keras.Sequential()
#直接添加SimpleRNN
model.add(keras.layers.SimpleRNN(
units = cell_size, # 输出
input_shape=(max_sequence_length,1), # 输入
))
# 输出层
model.add(keras.layers.Dense(2, activation='softmax'))
plot_model(model, to_file='SimpleRNN.png',show_shapes='True')
model.summary()
# 定义优化器
adam = keras.optimizers.Adam(lr=1e-4)
model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, train_y, batch_size=64, epochs=4)
# 评估模型
loss, accuracy = model.evaluate(X_test,test_y)
print('test loss', loss)
print('test accuracy', accuracy)
LSTM
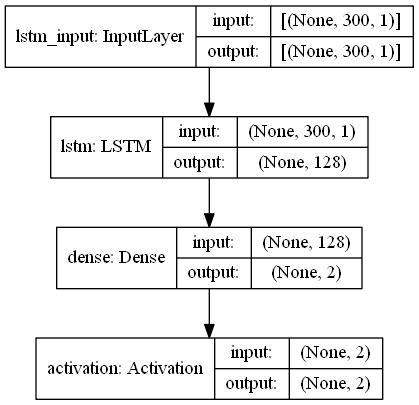
import numpy as np
import pandas as pd
from keras.layers import LSTM
from keras.layers import Dense, Activation
from keras.models import Sequential
from keras.optimizers import Adam
import os
import re
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from keras.utils.vis_utils import plot_model
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
os.environ["PATH"] += os.pathsep +'C:\\Program Files\\Graphviz\\bin'
#=============================================================================================
#==================