Java泛型复习笔记
Posted Putarmor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java泛型复习笔记相关的知识,希望对你有一定的参考价值。

1.泛型出现的意义:
在没有出现泛型之前,假如我们实现一个栈,栈中存放的数据类型只能有一种;当我们想去存放另外一种数据类型时,又要重新创建一个类,定义存放的数据类型;可以看出,这样操作是非常不方便的,同时代码也是非常冗余的,不够简洁。
我们猜想创建Object类型的栈是否可以弥补上述的缺点?Object类默认是所有类的父类,当栈中存放的数据类型为Object类型,任何类型的元素看起来都可以存放在栈中,似乎看起来很完美,但是在我们取得元素的时候,却需要做强制类型转换例如
String str = (String)stack.get(i);每取一次都要做类型强转,非常的繁琐不方便。
因而
泛型就出现了。泛型是什么呢?它是程序编译时期的一种机制,在使用对类进行限定后,我们所创建的类就是一个泛型类;此时栈中可以存放任意类型的元素,泛型在编译时期具有擦除机制,也就是将T类型擦除为Object类型,因此才可以存放各种引用类型的元素;但是当我们创建一个对象后只能指定存放一种类型的元素,泛型会根据我们设定的类型自动进行数据类型检查,当存放别的类型元素时,编译就会报错;此外当我们取出元素时候,不用再去做强制类型转换,泛型已经自动隐式做了类型转换。
2.Object代码示例:
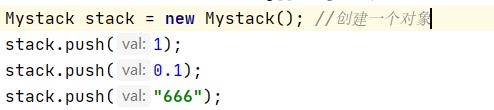
创建一个Object类型的栈:
class Mystack{
Object[] elem;
int top;
public Mystack() {
this.elem = new Object[10];
}
public void push(Object val){
this.elem[top] = val;
top++;
}
public Object getTop(){
return this.elem[top-1];
}
}
可以看出,栈中可以存放各种引用类型的变量,代码编译不报错
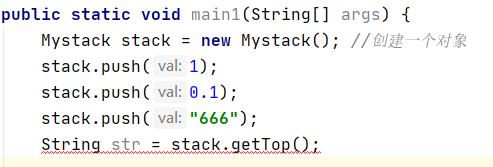
调用getTop方法取栈顶元素时,代码完美出错,和我们上述认知一样;原因:getTop()返回的是Object类型,而栈顶放的是String类型。
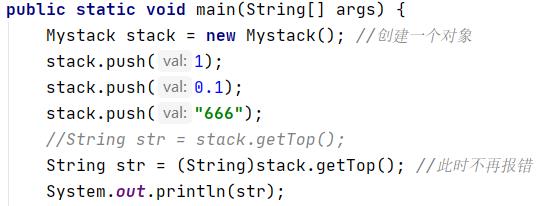
此时可以发现,经过强制类型转换,没有出现代码编译错误;正常取得栈顶元素并打印出来。

3.泛型示例:
创建一个泛型栈:
//<T>标志该类是一个泛型类
class Mystack<T>{
T[] elem;
int top;
public Mystack() {
this.elem = (T[])(new Object[10]);
}
public void push(T val){
this.elem[top] = val;
top++;
}
public T getTop(){
return this.elem[top-1];
}
}
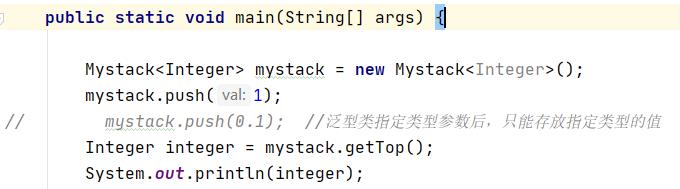
可以看出,指定存储数据类为Integer,当插入Double类型时,编译出错,这就是泛型自带的自动类型检查机制。
调用getTop方法获得栈顶元素时,编译不报错,泛型已经自动的进行了类型转换,正常获得栈顶元素并打印。
多来几个例子看看:

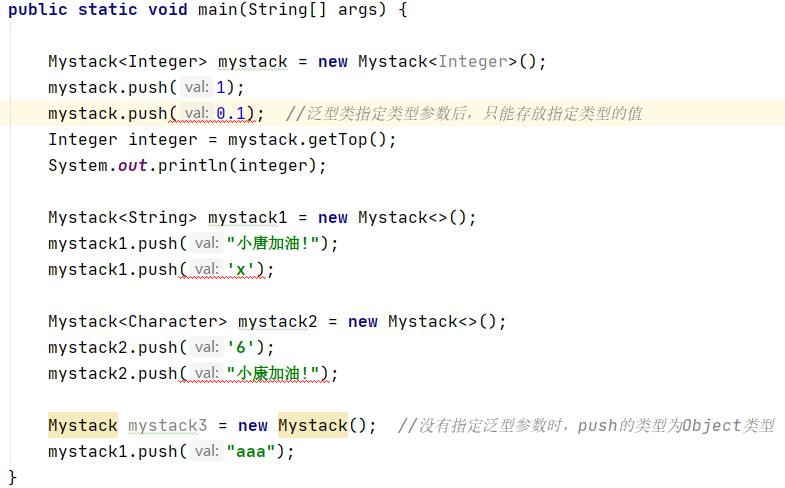
4.泛型特点:
以上就是本人对泛型的浅薄认知,现对泛型的特点进行一个总结:
- 泛型是编译时期的一种机制,程序运行时期没有泛型机制。
- 泛型可以自动进行类型检查;自动进行类型转换
- 简单类型不能作为泛型的参数取使用,必须传入的是引用类型(包装类型可以)
- 泛型编译原理:擦除机制。
在编译时期将T类型擦除为Object类型,其意义是为了存放任意类型的数据 - 不能new泛型类型的数组,需要new Object[ ]再使用T[ ]做强制类型转换
- 泛型类上届:
比如:class Algorithm<E extends Animal>E可以是Animal子类或者Animal本身
以上是关于Java泛型复习笔记的主要内容,如果未能解决你的问题,请参考以下文章