数据处理包Pandas--第三章
Posted Recently 祝祝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据处理包Pandas--第三章相关的知识,希望对你有一定的参考价值。
序列:
1:系列的创建于访问
创建
序列:由索引和对应值组成
import pandas as pd
import numpy as np
#列表转序列
s1=pd.Series([1,2,3,4,5])
#元祖转序列
s2=pd.Series((1,3,4))
#数组转序列
s3=pd.Series(np.array([1,2,3,5]))
#指定下标
s3=pd.Series([5,2,3],index=['a','b','c'])
#字典转序列
mydict={'red':2000,"bule":3000,"yellow":4000}
ss=pd.Series(mydict)
有默认的序列索引,也可以index自己指定索引
集合不能被序列化
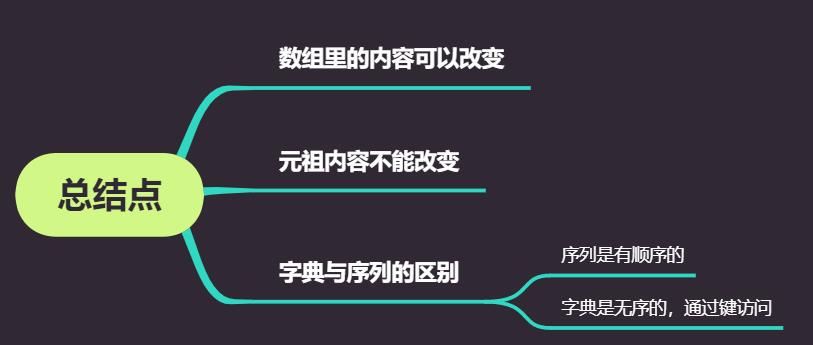
访问
通过索引下标进行访问
print(s1[3])
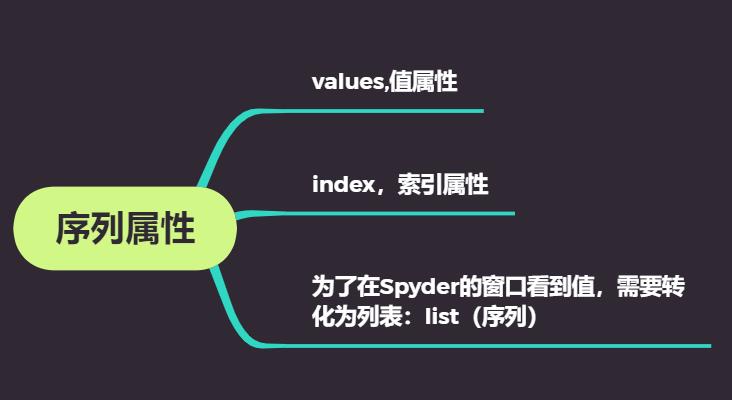
2:序列属性
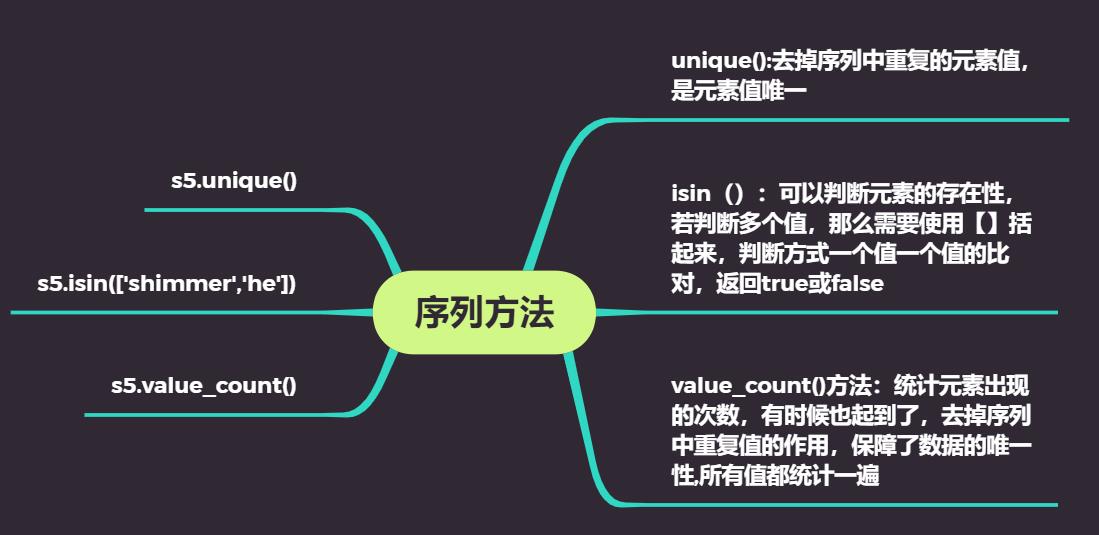
3:序列方法
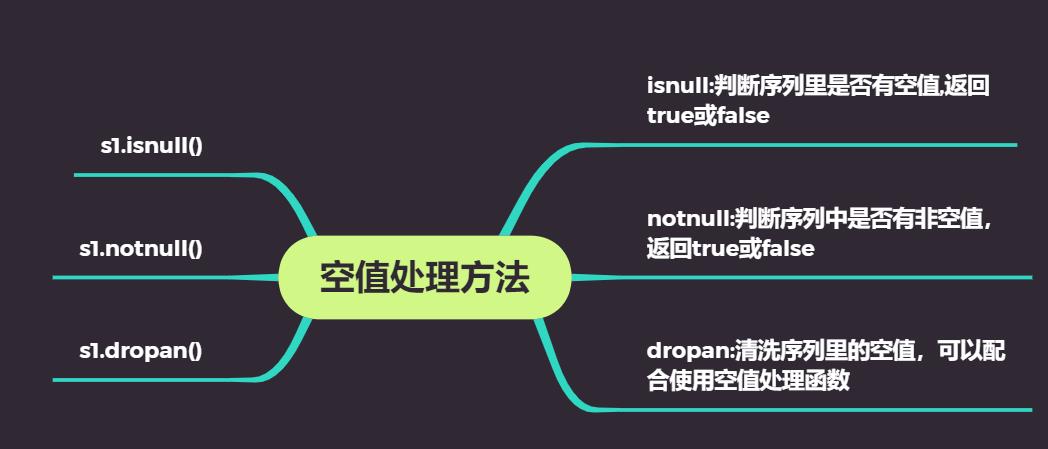
4:空值处理方法
5:序列切片
打印的值:对于序列来说都是索引值
import pandas as pd
s3=pd.Series([5,2,3,4],index=['a','b','c','d'])
#取索引号为a,b的元素
s22=s3[['a','b']]
#索引为连续的数组,取左不取右
s11=s3[0:2]
#索引为不连续的数组
s33=s3[[0,1,3]]
#索引为逻辑数组
s44=s3[s3>1]
6:序列聚合运算

数据框
1:数据框的创建:
s1.DataFrame(data)
数据框每个数组必须相同的Index,相同的长度
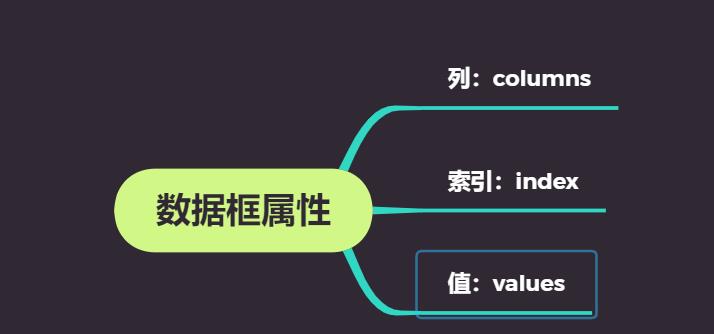
2:数据框属性
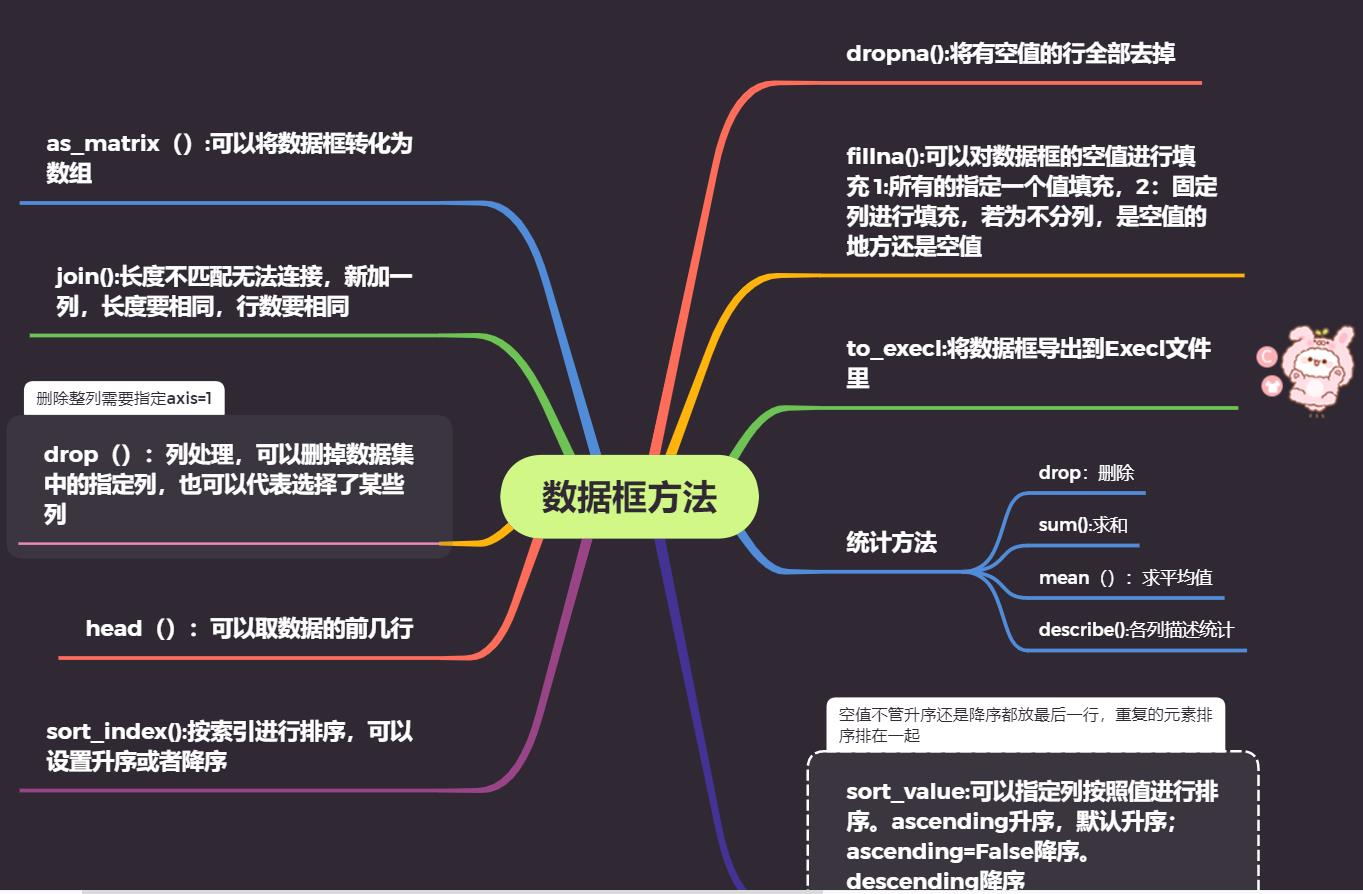
3:数据框方法
4:数据框切片
1:利用数据框中的iloc属性进行切片
利用数据框中的iloc[①,②]可以实现下标值或逻辑定位索引,并进行切片操作,①控制行,②控制列
跟np.ix_()切片类似
2:利用数据框中的loc属性进行切片
通过列值进行行行筛选定位,在通过指定列进行切片操作
import pandas as pd
import numpy as np
data={"shimmer":[1,2,3,4],"recently":[5,6,7,8],"Trada":[9,9.1,'kl',np.nan],
"A":['KL','KL','KL','kl'],'B':[1,2,np.nan,3]}
data1=pd.DataFrame(data)
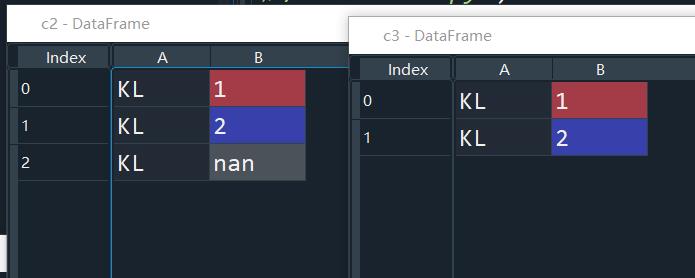
c1=data1.loc[data1['A'] == 'kl',:]
c2=data1.loc[data1['A'] == 'KL',['A','B']]
c3=data1.loc[data1['A'] == 'KL',['A','B']].head(2)
5:外部文件读取

# -*- coding: utf-8 -*-
"""
Created on Tue May 11 10:38:40 2021
@author: Administrator
"""
import pandas as pd
#excel文件读取
path="一、车次上车人数统计表.xlsx"
data=pd.read_excel(path)
data1=pd.read_excel(path,"Sheet2")
#data2=pd.read_excel('dta.xlsx',header=None)
data3=pd.read_excel(path,"t3",header=None)
# TXT文件读取
dta1=pd.read_table("txt1.txt",header=None)
dta11=pd.read_table("txt1.txt")
dta2=pd.read_table("txt2.txt",sep='\\s+')
dta3=pd.read_table("txt3.txt",sep=",",header=None)
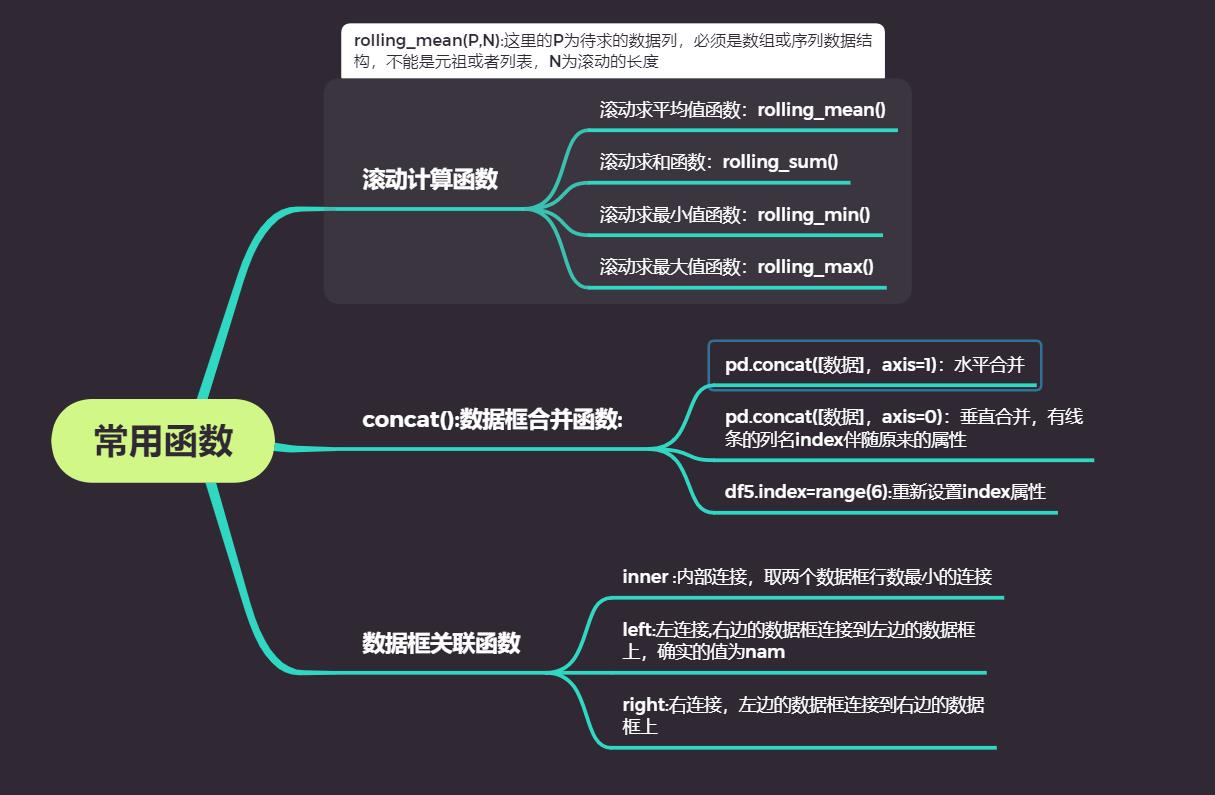
6:数据框合并
concat: 水平连接行数相同,垂直连接列数相同
import pandas as pd
import numpy as np
dict1={'a':[2,2,'kt',6],'b':[4,6,7,8],'c':[6,5,np.nan,6]}
dict2={'d':[8,9,10,11],'e':['p',16,10,8]}
dict3={'a':[1,2],'b':[2,3],'c':[3,4],'d':[4,5],'e':[5,6]}
df1=pd.DataFrame(dict1)
df2=pd.DataFrame(dict2)
df3=pd.DataFrame(dict3)
del dict1,dict2,dict3
df4=pd.concat([df1,df2],axis=1)
df5=pd.concat([df3,df4],axis=0)
#重新设置index的值
df5.index=range(6)
以上是关于数据处理包Pandas--第三章的主要内容,如果未能解决你的问题,请参考以下文章