从0开始,在Linux中配置Nginx反向代理负载均衡session共享动静分离
Posted 雷恩Layne
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0开始,在Linux中配置Nginx反向代理负载均衡session共享动静分离相关的知识,希望对你有一定的参考价值。
写这篇文章花费了我近一周的时间,参考网上许多优秀的博客文章,我不敢说写的很好,至少很全很详细。本文先介绍原理部分,然后再进行实战操作,我认为这样才会有更深的理解,不过这也导致了文章篇幅很长。但是,如果你耐心看下去,会有很多收获。
文章目录
1. 问题引入
1.1 为什么需要nginx
1.2 Nginx和Apache比较
1.3 什么是Tengine
2. Nginx下载与安装
3. Nginx工作模型
3.1 Master-Worker模式
3.2 worker_cpu_affinity
3.3 accept_mutex
3.4 使用进程而不用线程
3.5 处理高并发请求
4. Nginx参数详解
4.1 nginx.conf全览
4.2 连接数上限
4.3 开启零拷贝
4.4 nginx虚拟主机
4.5 nginx日志配置
4.6 Location详解
4.7 重新安装nginx
5. 反向代理
5.1 正向代理服务器
5.2 反向代理服务器
5.3 反向代理之负载均衡
5.4 负载均衡进阶
6. session共享
6.1 session共享的解决方案
6.2 memcache实现session共享
7. 动静分离
1. 问题引入
1.1 为什么需要Nginx
tomcat作为javaweb服务器非常流行,为什么还需要Nginx呢?我们先来看看单个tomcat的并发测试数据:
| 并发人数 | 响应时间 | 说明 |
|---|---|---|
| 100人 | 0.8s | 完美 |
| 150人 | 1s | 完美 |
| 200人 | 1.5s | 响应时间有微小波动 |
| 250人 | 1.8s | 理想情况下最大的并发用户数量 |
| 280人 | 约2.5s | 开始出现连接丢失问题 |
| 300人 | 3s | 响应时间有较大波动 |
| 350人 | 3s | 连出现接丢失问题,连接很不稳地 |
| 400人 | 3.8s | 连接丢失数量达到3000次以上 |
| 450人 | 4s | 连接丢失数量达到6000次以上 |
| 500人 | 4s | 连接丢失数量达到11000次以上 |
| 550人 | 6s | 连接丢失数量达21000次以上 |
| 600人 | - | 系统出现异常,停止测试 |
上述的并发人数是指同一时刻请求连接的人数,如果并发达到600,基本上能支持几万人的请求。
可以看到,单个tomcat在600并发请求下,系统出现异常, 理想情况下最大的并发用户数量为250,那么怎么解决高并发问题呢?
这就需要用到Nginx,Nginx作为一个轻量级Web服务器,可以支持近50000个并发,并且消耗的资源却非常少,是现代Web平台的首选服务器。
1.2 Nginx和Apache比较
Nginx是俄罗斯人Igor Sysoev编写的轻量级Web服务器,它不仅是一个高性能的静态HTTP和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。Apache httpd也是一个Web服务器,但这两者的适应场景不同,专注于解决不同的问题。总的来说,apache httpd:稳定、对动态请求处理强,但同时高并发时性能较弱,耗费资源多。nginx:**高并发处理能力强、擅长处理静态请求、反向代理、均衡负载。**下面详细说明Nginx和Apache区别[1]:
-
nginx是轻量级的web服务,比apache占用更少的内存及资源,且并发能力更强,在高并发下nginx能保持低资源、低消耗、高性能。另外,nginx具有高度模块化的设计,编写模块相对简单,社区活跃,高性能模块出品迅速。
-
apche的rewrite能力比nginx强大,且模块超多,基本想到的都可以找到。此外,apache的bug相比于nginx较少,比较稳定。一般来说,在性能方面,nginx更有优势,如果不需要性能只求稳定,那就用apache。
Rewrite是一种服务器的重写脉冲技术,它可以使得服务器可以支持 URL 重写,还可以实现限制特定IP访问网站的功能。
-
nginx处理请求是异步非阻塞模式,而apache则是同步阻塞模式。
-
同步:所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。 -
异步:异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。 -
阻塞:阻塞调用是指调用结果返回之前,当前线程会被挂起,函数只有在得到结果之后才会返回。有人也许会把阻塞调用和同步调用等同起来,实际上它们是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是当前函数没有返回而已。 -
非阻塞:非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。 -
nginx配置简单,apache配置复杂,nginx静态处理性能比apache高3倍以上,但对动态处理请求弱。apache对php支持比较简单,nginx需要配合其他后端使用。
-
最核心的区别在于apache是同步多进程模式,一个连接对应一个进程,而nginx是异步的,多个连接(万级别)可以对应一个进程。两者处理请求模式的不同,导致了nginx的抗并发能力强,对资源需求更少。
-
nginx配置文件简洁,正则配置让很多事情变得简单,运行效率高,占用资源少,代理功能强大,很适合做前端响应服务器。
-
nginx处理动态请求是鸡肋,一般动态请求要apache去做,nginx只适合静态HTTP请求和反向代理。
1.3 什么是Tengine
Tengine是由淘宝网发起的Web服务器项目。它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性。Tengine的性能和稳定性已经在大型的网站如淘宝、天猫等得到了很好的检验。它的最终目标是打造一个高效、稳定、安全、易用的Web平台。
Tengine和nginx官方性能测试网址为http://tengine.taobao.org/document_cn/benchmark_cn.html,测试结果:
-
Tengine相比Nginx默认配置,提升200%的处理能力。 -
Tengine相比Nginx优化配置,提升60%的处理能力。
Tengine详细参数解释详见:http://tengine.taobao.org/nginx_docs/cn/docs/
2. Nginx下载与安装
Nginx官方网址http://nginx.org/en/download.html提供了三个类型的版本:
-
Mainline Version:主线版,是最新版,但未经过过多的生产测试。 -
Stable Version:稳定版,生产环境使用版本。 -
Legacy Version:老版本。
这里下载Stable Version,稳定版又分为Linux 版与 Windows 版,本文下载Linxu版的nginx-1.16.1
在安装Nginx前,最好先配置好Linxu系统,并克隆两台以上虚拟机,因为后面的反向代理和负载均衡、Session共享配置,要用到多台虚拟机。可以参考我之前的文章。
接下来,采用源码编译的方式安装Nginx[2]!
(1)安装Nginx依赖的库
yum install gcc gcc-c++ pcre pcre-devel openssl openssl-devel zlib zlib-devel vim -y
推荐使用yum的清华源和东北大学源,可参考进行配置。
(2)创建存放源文件的文件夹
cd /opt # 进入opt目录下
mkdir apps # 创建apps目录,用于存放源文件以及解压后的文件
(3)通过Xftp上传nginx-1.16.1.tar.gz文件到Linux虚拟机的opt/apps目录下,可参考上传文件。
(4)解压 Nginx压缩包
cd /opt/apps
tar -zxvf nginx-1.16.1.tar.gz # 解压
(5)配置configure
配置configure可理解为预编译,主要用于检测系统基准环境库是否满足gcc环境,生成makefile文件,可以使用 configure 命令可以生成该文件。那么,configure 命令需要配置些什么参数呢?使用./configure --help可以查看到可以使用的参数说明。
[root@nginx1 apps]# cd /opt/apps/nginx-1.16.1
[root@nginx1 nginx-1.16.1]# ./configure --help
--help print this message
--prefix=PATH set installation prefix
--sbin-path=PATH set nginx binary pathname
--modules-path=PATH set modules path
--conf-path=PATH set nginx.conf pathname
--error-log-path=PATH set error log pathname
--pid-path=PATH set nginx.pid pathname
--lock-path=PATH set nginx.lock pathname
--user=USER set non-privileged user for
worker processes
--group=GROUP set non-privileged group for
worker processes
##. . .(内容太长,这里只展示部分内容). . . ##
这些参数可以分为三类:
-
第一类:基本信息的配置。 -
第二类:默认没有安装,可以指定安装的模块,使用 --with开头。Nginx 的高扩展性就体现在这里。 -
第三类:默认已经安装,可以指定卸载的模块,使用 --without开头。
这里简单介绍基本信息配置的含义:
-
prefix:Nginx 安装目录 -
sbin-path:sbin即binary file,为Nginx 命令文件存放目录 -
modules-path:Nginx 模块存放路径 -
conf-path:Nginx 配置文件存放路径 -
error-log-path:错误日志文件存放路径 -
pid-path:Nginx 的进程 id 存放路径 -
user:为Nginx的工作进程创建所属用户,如果不创建,则默认为nobody用户 -
group:为Nginx的工作进程创建所属用户组,如果不创建,则默认为nobody用户组
下面,我给出两种配置方案,一种简单版,一种详细版,这里使用简单版进行配置:
### 1. 首先创建/var/tmp/nginx/client目录
[root@nginx1 nginx-1.16.1]# mkdir –p /var/tmp/nginx/client
### 2. 进入/opt/apps/nginx-1.16.1目录下
[root@nginx1 nginx-1.16.1]# pwd
/opt/apps/nginx-1.16.1
### 3. 执行配置命令,简单版(当前使用):
./configure --prefix=/opt/nginx --with-http_ssl_module --with-http_gzip_static_module --error-log-path=/var/log/nginx/nginx.log --pid-path=/var/log/nginx/pid
### 详细版(留着以后备用):
### 下面的 意思是这个命令还没完,可以继续往下写
[root@nginx1 nginx-1.16.1]# ./configure
--prefix=/opt/nginx
--sbin-path=/usr/sbin/nginx
--conf-path=/etc/nginx/nginx.conf
--error-log-path=/var/log/nginx/error.log
--http-log-path=/var/log/nginx/access.log
--pid-path=/var/run/nginx/nginx.pid
--lock-path=/var/lock/nginx.lock
--user=nginx
--group=nginx
--with-http_ssl_module
--with-http_flv_module
--with-http_stub_status_module
--with-http_gzip_static_module
--http-client-body-temp-path=/var/tmp/nginx/client/
--http-proxy-temp-path=/var/tmp/nginx/proxy/
--http-fastcgi-temp-path=/var/tmp/nginx/fcgi/
--http-uwsgi-temp-path=/var/tmp/nginx/uwsgi
--http-scgi-temp-path=/var/tmp/nginx/scgi
--with-pcre
注意:详细版还需要执行useradd nginx 添加nginx用户。
在执行过 configure 命令后并不会立即生成/opt/nginx目录,也不会马上开始安装指定的模块,而仅仅是将命令中指定的参数及默认配置写入到即将要生成的 Makefile文件中。
配置成功后,再次查看 Nginx 解压目录,发现其中多出了一个文件 Makefile,后面的编译就是依靠该文件进行的。
[root@nginx1 nginx-1.16.1]# ls
auto CHANGES CHANGES.ru conf configure contrib html LICENSE Makefile man objs README src
(6)编译
make clean命令用来清除上一次编译生成的目标文件(清除上次的make命令所产生的object文件,即后缀为.o的文件及可执行文件)。这个步骤可有可无,但为了确保编译的成功,还是加上为好。防止由于软件中含有残留的目标文件导致编译失败。
生成脚本及配置文件:make (根据Makefile文件编译源代码、连接、生成目标文件、可执行文件)
所以一般先输入make clean清除编译再输入make进行编译。
(7)安装
输入make install,将编译成功的可执行文件安装到系统目录中。
(8)添加nginx进程到服务列表
安装之后进入nginx的安装目录/opt/nginx,查看包含哪些文件:
[root@nginx1 nginx]# cd /opt/nginx
[root@nginx1 nginx]# ls
client_body_temp conf fastcgi_temp html logs proxy_temp sbin scgi_temp uwsgi_temp
-
conf:保存nginx所有的配置文件,其中nginx.conf是nginx服务器的最核心最主要的配置文件,其他的.conf则是用来配置nginx相关的功能的,例如fastcgi功能使用的是fastcgi.conf和fastcgi_params两个文件,配置文件一般都有个样板配置文件,以文件名.default结尾,使用的时候将其复制并将default去掉即可。 -
html:目录中保存了nginx服务器的web文件,但是可以更改为其他目录保存web文件,另外还有一个50x的web文件是默认的错误提示页面。 -
logs:用来保存nginx服务器访问的错误日志等,logs目录可以放在其他路径,比如/var/logs/nginx里面。 -
sbin:保存nginx二进制启动脚本,可以接受不同的参数以实现不同的功能。
默认情况下,想要启动nginx ,必须在/opt/nginx/sbin 目录中输入./nginx启动nginx进程,使用起来很不方便。为了能够在任意目录下均可直接执行 nginx 命令,可通过以下三种方式完成:
方式一(推荐采用)
添加安装的nginx到服务列表,步骤如下:
-
将如下内容添加到 /etc/init.d/nginx脚本中
[root@nginx1 nginx]# vim /etc/init.d/nginx # 所有开机启动的进程都在/etc/init.d下
#!/bin/sh
#
# nginx - this script starts and stops the nginx daemon
#
# chkconfig: - 85 15
# description: Nginx is an HTTP(S) server, HTTP(S) reverse
# proxy and IMAP/POP3 proxy server
# processname: nginx
# Source function library.
. /etc/rc.d/init.d/functions
# Source networking configuration.
. /etc/sysconfig/network
# Check that networking is up.
[ "$NETWORKING" = "no" ] && exit 0
nginx="/opt/nginx/sbin/nginx"
prog=$(basename $nginx)
NGINX_CONF_FILE="/opt/nginx/conf/nginx.conf"
[ -f /etc/sysconfig/nginx ] && . /etc/sysconfig/nginx
lockfile=/var/lock/subsys/nginx
make_dirs() {
# make required directories
user=`nginx -V 2>&1 | grep "configure arguments:" | sed 's/[^*]*--user=([^ ]*).*/1/g' -`
options=`$nginx -V 2>&1 | grep 'configure arguments:'`
for opt in $options; do
if [ `echo $opt | grep '.*-temp-path'` ]; then
value=`echo $opt | cut -d "=" -f 2`
if [ ! -d "$value" ]; then
# echo "creating" $value
mkdir -p $value && chown -R $user $value
fi
fi
done
}
start() {
[ -x $nginx ] || exit 5
[ -f $NGINX_CONF_FILE ] || exit 6
make_dirs
echo -n $"Starting $prog: "
daemon $nginx -c $NGINX_CONF_FILE
retval=$?
echo
[ $retval -eq 0 ] && touch $lockfile
return $retval
}
stop() {
echo -n $"Stopping $prog: "
killproc $prog -QUIT
retval=$?
echo
[ $retval -eq 0 ] && rm -f $lockfile
return $retval
}
restart() {
configtest || return $?
stop
sleep 1
start
}
reload() {
configtest || return $?
echo -n $"Reloading $prog: "
killproc $nginx -HUP
RETVAL=$?
echo
}
force_reload() {
restart
}
configtest() {
$nginx -t -c $NGINX_CONF_FILE
}
rh_status() {
status $prog
}
rh_status_q() {
rh_status >/dev/null 2>&1
}
case "$1" in
start)
rh_status_q && exit 0
$1
;;
stop)
rh_status_q || exit 0
$1
;;
restart|configtest)
$1
;;
reload)
rh_status_q || exit 7
$1
;;
force-reload)
force_reload
;;
status)
rh_status
;;
condrestart|try-restart)
rh_status_q || exit 0
;;
*)
echo $"Usage: $0 {start|stop|status|restart|condrestart|try-restart|reload|force-reload|configtest}"
exit 2
esac
-
然后,修改nginx文件的执行权限。
chmod +x /etc/init.d/nginx
-
最后,添加该文件到系统服务中去。
chkconfig --add /etc/init.d/nginx
查看服务列表中的nginx进程:
[root@nginx1 nginx]# chkconfig --list nginx
nginx 0:off 1:off 2:off 3:off 4:off 5:off 6:off
这样,就完成了添加nginx进程到服务列表,可以使用service命令来管理nginx进程:
-
service nginx start|stop|reload:设置nginx进程启动|停止|重新加载 -
service nginx restart:重启nginx进程 -
service nginx on:设置nginx进程开机启动
现在,我们设置nginx进程当前启动和开机启动:
[root@nginx1 nginx]# chkconfig nginx on #设置nginx进程开机启动
[root@nginx1 nginx]# chkconfig --list nginx
nginx 0:off 1:off 2:on 3:on 4:on 5:on 6:off
[root@nginx1 nginx]# service nginx start #启动nginx进程
[root@nginx1 nginx]# ps aux | grep nginx
root 1216 0.0 0.1 49400 1292 ? Ss Feb14 0:00 nginx: master process /opt/nginx/sbin/nginx -c /opt/nginx/conf/nginx.conf
nobody 1218 0.0 0.2 49920 2348 ? S Feb14 0:00 nginx: worker process
root 1509 0.0 0.0 103256 864 pts/0 S+ 07:16 0:00 grep nginx
方式二
在/etc/profile 文件最后添加以下内容,将安装目录下的 sbin 目录添加到 PATH 系统环境变量中,然后再重新加载该文件即可。
#1. 进入/etc/profile
vim /etc/profile
#2. 在文件末尾添加环境变量配置
export PATH=$PATH:/opt/nginx/sbin #注意可执行文件的位置,即--prefix的配置位置
#3. 使配置立即生效
source /etc/profile
#4. 启动nginx
nginx #启动nginx
方式二在系统中的任何位置都可以使用下面方式三的命令。
方式三
直接在/opt/nginx/sbin目录下管理nginx进程
[root@nginx1 sbin]# pwd
/opt/nginx/sbin
[root@nginx1 sbin]# ./nginx # 启动nginx进程
[root@nginx1 sbin]# ./nginx -c /opt/nginx/conf/nginx.conf # 以特定目录下的配置文件启动nginx进程
[root@nginx1 sbin]# ./nginx -s stop # 立即停止服务
[root@nginx1 sbin]# ./nginx -s reload # 执行这个命令后,master进程会等待worker进程处理完当前请求,然后根据最新配置重新创建新的worker进程,完成Nginx配置的热更新。
[root@nginx1 sbin]# ./nginx -s quit # 执行该命令后,Nginx在完成当前工作任务后再停止。
[root@nginx1 sbin]# ./nginx -t # 检查配置文件是否正确
nginx: the configuration file /opt/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /opt/nginx/conf/nginx.conf test is successful
[root@nginx1 sbin]# ./nginx -t -c /opt/nginx/conf/nginx.conf # 检查特定目录的配置文件是否正确
nginx: the configuration file /opt/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /opt/nginx/conf/nginx.conf test is successful
[root@nginx1 sbin]# ./nginx -v # 查看版本信息
nginx version: nginx/1.16.1
3. Nginx工作模型
3.1 Master-Worker模式
当我们启动nginx以后,会有两个nginx进程,一个master进程,一个worker进程,可以输入ps aux | grep nginx查看:
[root@nginx1 nginx]# ps aux | grep nginx
root 1641 0.0 0.1 49400 1292 ? Ss 09:18 0:00 nginx: master process /opt/nginx/sbin/nginx -c /opt/nginx/conf/nginx.conf
nobody 1643 0.0 0.1 49920 1876 ? S 09:18 0:00 nginx: worker process
root 1645 0.0 0.0 103256 860 pts/0 S+ 09:18 0:00 grep nginx
在预编译配置nginx时,我们没有为nginx的wrok进程创建用户,所以默认情况下worker进程是以"nobody"用户的身份运行的,如果想要指定worker进程的运行用户,则可以创建一个用户,并修改/opt/nginx/conf/nginx.conf的配置即可。
现在,我们指定worker进程以nginx用户的身份运行,操作步骤如下:
[root@nginx1 nginx]# useradd nginx # 添加nginx用户(默认添加一个同名的用户组)
[root@nginx1 nginx]# id nginx # 查看nginx用户的信息
uid=500(nginx) gid=500(nginx) groups=500(nginx)
[root@nginx1 nginx]# vim /opt/nginx/conf/nginx.conf # 将user nobody注释去掉,并改为user nginx;
[root@nginx1 nginx]# service nginx restart # 重启nginx进程
nginx: the configuration file /opt/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /opt/nginx/conf/nginx.conf test is successful
Stopping nginx: [ OK ]
Starting nginx: [ OK ]
[root@nginx1 nginx]# ps aux | grep nginx # 再次查看nginx的work进程所属的用户
root 1698 0.0 0.1 49404 1300 ? Ss 09:27 0:00 nginx: master process /opt/nginx/sbin/nginx -c /opt/nginx/conf/nginx.conf
nginx 1700 0.0 0.1 49920 1884 ? S 09:27 0:00 nginx: worker process
root 1702 0.0 0.0 103256 860 pts/0 S+ 09:27 0:00 grep nginx
master进程和nginx进程各自有什么用呢[3]?见名知意,worker进程天生就是来"干活"的,真正负责处理请求的进程就是你看到的worker进程。master进程其实是负责管理worker进程的,除此之外,master进程还负责读取配置文件、判断配置文件语法的工作。master进程也叫主进程,在nginx中,主进程只能有一个,而worker进程可以有多个,可以由管理员自己进行定义。在nginx.conf下的配置文件中有这样一条配置:
worker_ processes 1;
默认情况下,启动nginx后只有1个worker进程,你想要多少个worker进程,将worker_ processe指令的值设置成多少就好了。
worker_ processes的值通常不会大于服务器中cpu的核心数量,换句话说,worker进程的数通常与服务器有多少 cpu核心有关,比如,nginx所在主机拥有4核cpu,那么worker_ processes的值通常不会大于4,这样做的原因是为了尽力让每个worker进程都有一个cpu可以使用,尽量避免了多个worker进程抢占同一个cpu的情况。我们也可以将worker_ processes的值设置为"auto",这时nginx会自动检测当前主机的cpu核心数,并启动对应数量的worker进程。
3.2 worker_cpu_affinity
为了避免cpu在切换进程时产生性能损耗,我们也可以将worker进程与cpu核心进行"绑定",当worker进程与cpu核心绑定以后,worker进程可以更好的专注的使用某个cpu核心上的缓存,从而减少因为cpu切换不同worker进程而带来的缓存失效。此功能,可以通过nginx.conf的worker_ cpu_ affinity配置来完成。不过,若指定 worker_processes 的值为auto,则无法设置 worker_cpu_affinity。
worker_cpu_affinity的设置是通过二进制进行的。每个内核使用一个二进制位表示,0 代表内核关闭,1 代
表内核开启。也就是说,有几个内核,就需要使用几个二进制位。下图是worker_processes的数量与绑定的cpu取值的设定关系:
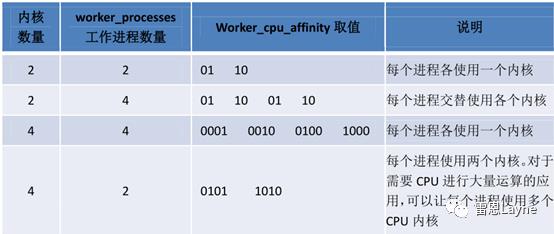
比如,4核cpu可以设置如下的配置:
user nginx;
worker_processes 4;
worker_cpu_affinity 1000 0100 0010 0001;
3.3 accept_mutex
accept_mutex机制通过accept锁来避免所有休眠的work子进程被唤醒的情形,从而避免了惊群问题。
所谓的惊群问题[4],当一个新的连接到达时,所有处于休眠状态的work进程都会被唤醒,但是只有一个wrok进程能获取连接,其它的work进程会重新进入休眠状态。这就导致出现了很多不必要的调度及上下文切换,浪费了系统的资源。
在Linux内核的较新版本中,accept调用本身所引起的惊群问题已经得到了解决,但是在Nginx中,accept是交给epoll机制来处理的,epoll的accept带来的惊群问题并没有得到解决,执行epoll_wait后,所有监听这个事件的进程会被这个epoll_wait唤醒,所以Nginx的accept惊群问题仍然需要定制一个自己的解决方案。
Nginx通过accept锁来解决惊群问题,accept锁本质上这是一个跨进程的互斥锁(共享锁)。在实现上,accept锁是一个全局变量,放在一块进程间共享的内存中,以保证所有进程都能访问这一个实例,加锁、解锁是借由linux的原子变量来做CAS算法,如果加锁失败则立即返回,是一种非阻塞的锁。
Nginx默认激活了accept_mutex,也就是说不会有惊群问题,即每个worker进程在执行accept之前都需要先获取锁(共享锁),获取不到就放弃执行accept()。有了这把锁之后,同一时刻,就只会有一个进程去accpet(),这样就不会有惊群问题了。
实际上Nginx作者Igor Sysoev曾经给过相关的解释:
OS may wake all processes waiting on accept() and select(), this is called thundering herd problem. This is a problem if you have a lot of workers as in Apache (hundreds and more), but this insensible if you have just several workers as nginx usually has. Therefore turning accept_mutex off is as scheduling incoming connection by OS via select/kqueue/epoll/etc (but not accept()).
意思就是说,OS可能会唤醒所有等待的进程,也就是惊群问题。如果像Apache那样有很多work者(几百个甚至更多),会出现这样的问题,但如果像nginx那样只有几个work进程,这就不太可能了。因此,关闭accept_mutex(默认开启)就像操作系统通过select/kqueue/epoll/等来调度传入的请求连接一样(但不是accept)。
Nginx默认激活了accept_mutex,是一种保守的选择。如果关闭accept_mutex,可能会引起一定程度的惊群问题,主要表现为浪费了很多不必要的调度及上下文切换。但是开启accept_mutex,即同时唤醒所有的work进程,让他们主动去抢占式获取连接,整体的效率无疑大大增强了。
如果想要关闭accept_mutex,只要在nginx.conf中加入以下配置即可:
events {
accept_mutex off;
}
select、epoll等都是常用的IO模型,准确的说是IO多路复用,想要更深入的了解,可以参考我的文章
3.4 使用进程而不用线程
Nginx使用的进程(即worker process)而不是线程进行工作,为什么使用进程不使用线程呢?
当一个worker进程在accept()这个连接之后,就开始读取请求、解析请求、处理请求,然后把处理的结果再返回客户端,最后才断开连接,完成一个完整的请求。所以,一个请求,完全由worker进程来处理,而且只能在一个worker进程中处理。每个worker进程之间不会相互影响,就算一个worker进程因为异常挂掉了,也不会影响其他worker进程。
3.5 处理高并发请求
我们知道,worker进程负责处理每个请求,当有多个并发的请求到来时,如何进行处理呢?
当有多个并发的请求到来时,每进来一个请求,会有一个worker进程去处理,但不是全程的处理,处理到什么程度呢?一般处理到可能发生阻塞的地方,比如worker进程转发来自客户端的请求到相应的服务器(如tomcat或apache)后,它不会这么傻等着,而是在发送完请求后,注册一个事件(Nginx以事件驱动的特征就体现在这里):“如果upstream返回了,告诉我一声,我再接着干”,于是他就休息去了(或者为其他的请求进行处理)。此时,如果再有新的请求进程,worker进程就可以很快再按这种方式处理。一旦服务器返回了,就会触发这个事件,worker才会来接手这个请求,把请求的结果返回给客户端。
一般来说,Nginx服务器只有几个worker进程,但会处理数十万个请求,也就是说每个worker进程会处理多个请求,这个可以在Nginx.conf中进程设置:
events {
worker_connections 1024;
}
由于web server的工作性质决定了每个请求的大部份时间都是在网络传输中,实际上花费在server机器上的时间片不多,并且Nginx主要用来转发请求的,一般不真正处理请求,所以几个worker进程就能解决高并发的请求。
4. Nginx参数详解
4.1 nginx.conf全览
nginx.conf有三部分组成,分别是全局块、events块、http块:
#---全局块开始----
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
#----全局块结束----
#====events块开始====
events {
worker_connections 1024;
}
#====events块结束====
#****http块开始****
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
......
}
#****http块结束****
Nginx 配置详解可以从参考这里:https://www.runoob.com/w3cnote/nginx-setup-intro.html
4.1.1 全局块
从Nginx.conf的开始到events之间的内容是全局块,主要设置一些nginx服务器整体运行的配置命令。下面我们分别进程理解和配置:
(1)worker进程的用户
在nginx.conf中,worker进程的默认用户为nobody,查看这个用户的信息
[root@nginx1 conf]# id nobody
uid=99(nobody) gid=99(nobody) groups=99(nobody)
[root@nginx1 conf]# cat /etc/passwd
......
nobody:x:99:99:Nobody:/:/sbin/nologin
......
可以看到,该用户对应的程序是/sbin/nologin,所以就算有人通过worker进程黑到了你的服务器,也就是不能做任何事情!
输入ps -ef|grep nginx查看当前nginx进程信息:

可以看到,用之前的配置方法,没有创建nginx用户和用户组,这时maste进程所属的用户是root,worker进程所属的用户是nobody,一般正式开发需要创建一个用户,毕竟root权限太大了。
可以添加一个nginx用户,并修改nginx.conf的配置:
#1.添加用户
useradd nginx # 添加nginx用户(默认添加一个同名的用户组)
#2.修改nginx.conf配置
user nginx;
#3.默认创建完之后,nginx用户登入后执行的是`/bin/bash`,可以修改为`/opt/nginx/sbin/nginx`
usermod -s /opt/nginx/sbin/nginx nginx
(2)worker进程数
worker_processes用于配置nginx启动后的woker进程数,也可以将worker_ processes的值设置为"auto",这时nginx会自动检测当前主机的cpu核心数,并启动对应数量的worker进程。
(3)错误配置
error_log配置nginx日志文件的全路径名
(4)进程pid
pid配置进程PID存放路径
如果在nginx中不进行上述配置,默认的配置时nginx.conf注释的配置。
4.1.2 events块
events块主要用于配置每个worker进程所支持的最大连接数。
events {
worker_connections 1024;
}
Nginx服务器总的并发数即最大连接数max_clients = worker_processes * worker_connections。一般。不会达到这么大的连接数,因为要受到物理内存和系统可以打开的最大文件数的限制,这个我们在4.2节介绍。
events除了配置最大连接数,也用于许多其他的配置:
events {
accept_mutex on; #设置网路连接序列化,防止惊群现象发生,默认为on
multi_accept on; #设置一个进程是否同时接受多个网络连接,默认为off
use epoll; #事件驱动模型,select|poll|kqueue|epoll|resig|/dev/poll|eventport
worker_connections 1024; # 最大连接数
}
这里,重点介绍一下use epoll,Nginx服务器提供了多个事件驱动模型来处理网络消息。
与apache类似,nginx针对不同的操作系统,有不同的事件模型。如果你不知道Nginx该使用哪种轮询方法的话,它会选择一个最适合你操作系统的。常用的I/O模型有[5]:
-
标准事件模型:select、poll属于标准事件模型,如果当前系统不存在更有效的方法,nginx会选择select或poll -
高效事件模型: -
kqueue:使用于FreeBSD 4.1+、OpenBSD 2.9+、NetBSD 2.0 和 MacOS X,但双处理器的MacOS X系统使用kqueue可能会造成内核崩溃 -
epoll:使用于Linux内核2.6版本及以后的系统 -
/dev/poll:使用于Solaris 7 11/99+、HP/UX 11.22+ (eventport)、IRIX 6.5.15+ 和 Tru64 UNIX 5.1A+ -
eventport:使用于Solaris 10,为了防止出现内核崩溃的问题, 有必要安装安全补丁
可以使用uname -a命令查看服务器系统相关的信息。
[root@nginx1 conf]# uname -a
Linux nginx1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
可以看到,我的Linux内核版本是2.6.32,大于2.6版本的内核,故可以选用epoll作为事件驱动模型。
4.1.3 http块
http块是Nginx服务器配置中最频繁的部分,代理、缓存和日志定义等绝大多数功能和第三方模块的配置都在这里。
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on; # 开启零拷贝
#tcp_nopush on;
#test
keepalive_timeout 0;
#keepalive_timeout 65; # 会话的保持时间,默认是65
gzip on; #是否启动压缩
server {
listen 80;#监听的端口号
server_name localhost;#监听的域名
#charset koi8-r;
#access_log logs/host.access.log main;
location / { #路径中包含 /
root html;
index index.html index.htm;
}
......
}
......
}
http中几个常用配置:
-
keepalive_timeout是会话的保持时间,在部署时需要设置合适的数值来提高效率 -
log_format和access_log是http块的日志配置,后面会详细讲解。 -
gzip on指启用压缩,压缩可以有效减少文件的大小, 有利于网络传输。
http块中最重要的就属server块,server块和虚拟主机有密切关系,虚拟主机从用户角度看,和一台独立的硬件主机是完全一样的,该技术的产生是为了节省互联网服务器硬件成本。每个http块可以包括多个server块,而每个server块就相当于一个虚拟主机。每个server块可以同时包含多个location块,location主要配置nginx转发的出口。
这里先说个大概,后面会详细介绍这些模块的配置。
4.2 连接数上限
#user nobody;
worker_processes 1;
events {
use epoll;
worker_connections 1024;
}
前面也提到了,Nginx服务器总的并发数即最大连接数max_clients = worker_processes * worker_connections。一般,不会达到这么大的连接数,因为:
-
worker_connections值的设置跟物理内存大小有关 -
因为并发受IO约束, max_clients的值须小于系统可以打开的最大文件数。
系统可以打开的最大文件数和内存大小成正比,一般1GB内存的机器上可以打开的文件数大约是10万左右。假如服务器内存是16G,则可以打开的最大文件数约为16万。
Linux可以打开的最大文件数[6]可以由/proc/sys/fs/file-max和ulimit -n来配置。
-
file-max表示系统级别的能够打开的文件句柄的数量,是对整个系统的限制,并不是针对用户的。 -
ulimit -n是进程级别能够打开的文件句柄的数量,提供shell及其启动的进程的可用文件句柄的控制,是进程级别的。
对于服务器来说,file-max和ulimit都需要设置,否则会出现文件描述符耗尽的问题。
一般如果遇到文件句柄达到上限时,会碰到Too many open files或者Socket/File: Can’t open so many files等错误。
当前,我的Linux虚拟机为1G,来看下可以打开的文件句柄数是多少:
[root@nginx1 conf]# cat /proc/sys/fs/file-max #整个系统能够打开的文件句柄的数量
97319
[root@nginx1 conf]# ulimit -n #单个用户进程打开的文件句柄的数量
1024
可以看到,虚拟机内存为1G的Linxu系统可以打开的最大文件数是9.7万多个。
可以修改file-max和ulimit,下面我们就来尝试一下!
(1)修改file-max
一般我们不需要主动修改file-max值,Linux系统在安装时会根据物理内存自动生成合适的大小,当然如果你认为它的调小了,也可以进行修改,方法如下:
-
第一步: vim /etc/sysctl.conf -
第二步:在文件末尾加入配置内容: fs.file-max = 2000000 -
第三步:执行 sysctl -p,使修改配置立即生效
再次查看/proc/sys/fs/file-max的内容,发现已经改变:
[root@nginx1 conf]# cat /proc/sys/fs/file-max
2000000
上述修改永久生效,即重启系统后也不会失效。
(2)修改ulimit
执行vim /etc/security/limits.conf在文件中添加如下两行记录:
* soft nofile 65535
* hard nofile 65535
重启系统后,输入ulimit -n查看单个用户进程打开的文件句柄的数量:
[root@nginx1 ~]# ulimit -n
65535
可以查看,修改已经生效。
如果需要设置当前用户session立即生效,则执行ulimit -n 65535命令即可。
对于服务器,一般修改进程级的最大打开文件句柄数即可(系统默认1024,有点小),一般不需要调整系统级的最大数。如果真的出现了达到系统级别最大限制时,也可以调整系统级的最大数。
只要让并发连接总数小于系统可以打开的文件句柄总数,操作系统才可以在承受的范围之内。所以,worker_connections 的值需根据 worker_processes 进程数目和用户进程打开的文件句柄的数量适当地进行设置,使得并发总数小于操作系统可以打开的最大文件数目,实质上也就是根据主机的物理CPU和内存进行配置。
当然,理论上的并发总数可能会和实际有所偏差,因为主机还有其他的工作进程需要消耗系统资源。
4.3 开启零拷贝
sendfile实际上是 Linux2.0+以后的推出的一个系统调用,web服务器可以通过调整自身的配置来决定是否利用 sendfile这个系统调用。
先来看一下不用sendfile的传统网络传输过程,从逻辑上看只需要两行代码即可:
read(file,tmp_buf, len);
write(socket,tmp_buf, len);
一般,一个基于socket的服务,首先读硬盘数据,然后写数据到socket 来完成网络传输的。上面2行用代码解释了这一点,不过上面2行简单的代码掩盖了底层的很多操作。来看看底层是怎么执行上面2行代码的:
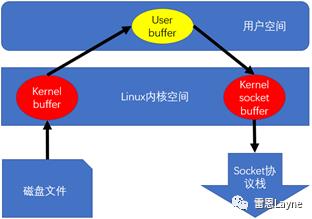
执行过程:硬盘 >> kernel buffer >> user buffer>> kernel socket buffer >>协议栈
-
当应用程序调用read()方法时,通过DMA方式将数据从磁盘拷贝到kernel buffer -
由cpu控制,将kernel buffer的数据拷贝到用户空间的User buffer中,供应用程序使用 -
当应用程序调用write()方法时,cpu会把User buffer的数据copy到内核缓冲区的Socket Buffer中 -
最后通过DMA方式将内核空间中的Socket Buffer拷贝到Socket协议栈(即网卡设备)中传输。
这里经历了4次上下文切换和4次缓冲区的copy,第一次是从磁盘缓冲区到内核缓冲区(由cpu控制),第二次是内核缓冲区到用户缓冲区(DMA控制),第三次是用户缓冲区到内核缓冲区的Socket Buffer(由cpu控制),第四次是从内核缓冲区的Socket Buffer到网卡设备(由DMA控制)。四次缓冲区的copy工作两次由cpu控制,两次由DMA控制。
我们发现如果能减少切换次数和拷贝次数将会有效提升性能。在kernel2.0+ 版本中,系统调用 sendfile() 就是用来简化上面步骤提升性能的,sendfile() 不但能减少切换次数而且还能减少拷贝次数。
再来看一下用 sendfile()来进行网络传输的过程,逻辑上也就一行代码:
sendfile(socket,file, len);
底层执行过程如下:
硬盘 >> kernel buffer (快速拷贝到kernelsocket buffer) >>协议栈
-
当应用程序调用read()方法时,通过DMA方式将数据从磁盘拷贝到kernel buffer -
由cpu控制,将kernel buffer的数据直接拷贝到另外一个与 socket相关的内核缓冲区,即kernel socket buffer -
然后由DMA 把数据从kernel socket buffer直接拷贝给Socket协议栈(网卡设备中)。
这里,只经历了三次缓冲区的拷贝,第一次是从磁盘缓冲区到内核缓冲区,第二次是从内核缓冲区到kernel socket buffer,第三次是从kernel socket buffe到Socket协议栈(网卡设备中)。只发生两次内核态和用户态的切换,第一次是当应用程序调用read()方法时,用户态切换到内核到执行read系统调用,第二次是将数据从网络中发送出去后系统调用返回,从内核态切换到用户态。
需要注意的是,sendfile要求输入的fd必须是文件句柄,不能是socket,输出的fd必须是socket,也就是说,数据的来源必须是从本地的磁盘,而不能是从网络中,如果数据来源于socket,就不能使用零拷贝功能了。我们看一下Linux内核的sendfile接口就知道了:
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)
-
out_fd:待写入文件描述符 -
in_fd:待读出文件描述符 -
offset:从读入文件流的哪个位置开始读,如果为空,则默认从起始位置开始 -
count:指定在文件描述符in_fd 和out_fd之间传输的字节数 -
返回值:成功时,返回出传输的字节数,失败返回-1
in_fd必须指向真实的文件,不能是socket和管道;而out_fd则必须是一个socket。由此可见,sendfile几乎是专门为在网络上传输文件而设计的。所以,当 Nginx 是作为一个反向代理来使用的时候,SENDFILE 则没什么用了,因为 Nginx 是反向代理的时候,in_fd 就不是文件句柄而是 socket,此时就不符合 sendfile 函数的参数要求了。
fd全称file descriptor,即文件描述符,是内核为了高效管理已被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符。in_fd是输入的文件描述符,out_fd是输出的文件描述符。
4.4 nginx虚拟主机
上面也提到了,http块中的server块是用来配置虚拟主机的,所谓的虚拟主机,就是将一台物理服务器虚拟为多个服务器来使用,从而实现在一台服务器上配置多个站点,即可以在一台物理主机上配置多个域名。在Nginx 中,一个 server 标签就是一台虚拟主机,配置多个 server 标签就虚拟出了多台主机。
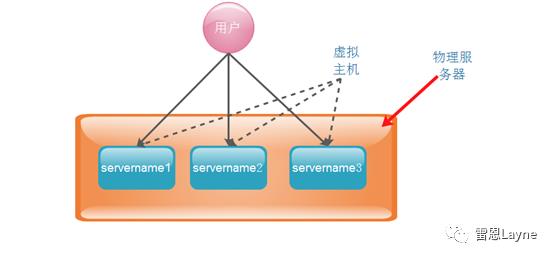
Nginx 虚拟主机的实现方式有两种:域名虚拟方式与端口虚拟方式。域名虚拟方式是指不同的虚拟机使用不同的域名,通过不同的域名虚拟出不同的主机;端口虚拟方式是指不同的虚拟机使用相同的域名不同的端口号,通过不同的端口号虚拟出不同的主机。但是,基于端口的虚拟方式不常用。
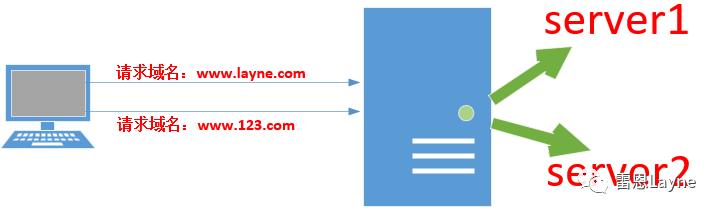
现在,就来配置一下吧!
先来看一个重要参数:
autoindex on; #开启目录列表访问,合适下载服务器,默认关闭
在nginx.conf的http块中添加两个server块,配置如下:
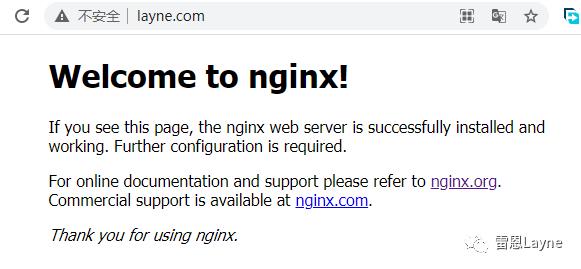
server {
listen 80;
server_name www.layne.com;
location / {
root html;
index index.html index.htm;
}
}
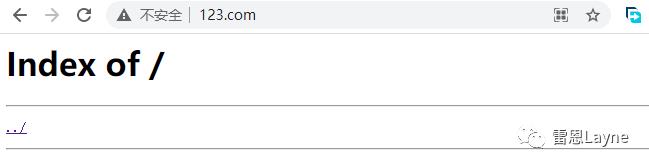
server {
listen 80;
server_name www.123.com;
location / {
root /mnt;
autoindex on;
}
}
然后,重启Nginx:
[root@nginx1 conf]# service nginx restart
nginx: the configuration file /opt/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /opt/nginx/conf/nginx.conf test is successful
Stopping nginx: [ OK ]
Starting nginx: [ OK ]
最后,在windows平台的hosts文件(在C:WindowsSystem32driversetc路径下)添加一条域名解析:
192.168.218.55 nginx1 www.123.com www.layne.com
上述ip就是nginx所在Linux系统的ip,后面是两条刚刚在server块中配置的域名。这样在浏览器中输入网址访问的时候,会先解析本地hosts文件中的记录,如果找不到,才会到相应的域名解析服务器中去找。
在浏览器中输入http://www.layne.com/,可以看到如下界面:
在浏览器中输入http://www.123.com/,会发现里面没有任何东西,这是因为/mnt目录下没有文件。
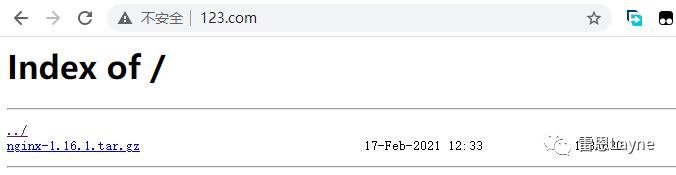
如果我们复制一个文件到/mnt目下,再刷新一下http://www.123.com/,会页面中出现一条记录,点击也可以进行下载:
现在,我们为/mnt挂载,并重新测试,可以看到我们挂载的CD或U盘:
[root@nginx1 nginx]# mount /dev/cdrom /mnt #将cdrom挂载到/mnt目录下
mount: block device /dev/sr0 is write-protected, mounting read-only
再次刷新http://www.123.com/
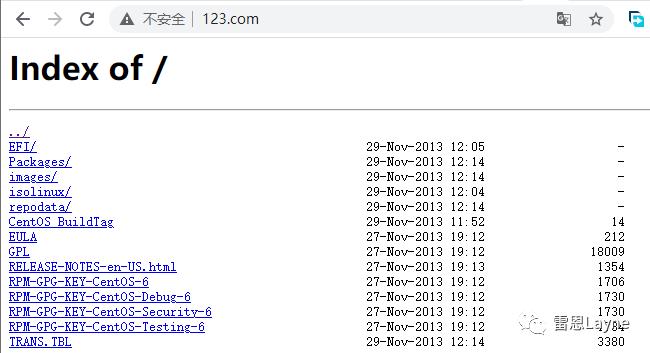
这样我们就完成了一个下载服务器的搭建工作,是不是感觉自己很强!别急,后面还有更好玩的。
4.5 nginx日志配置
nginx的默认日志在安装目录的logs文件夹下,现在我们输入tail -f access.log持续监控这个文件:
[root@nginx1 logs]# pwd
/opt/nginx/logs
[root@nginx1 logs]# tail -f access.log
刷新http://www.123.com/,会发现日志中多了一条记录:

上图的信息是:
-
第一列:ip地址为192.168.218.1,这是因为我们采用的NAT连接方式,所以主机访问虚拟机的时候,采用的IP地址是虚拟机同样网段下的192.168.218.1。 -
第二列:是东八区的时间,即CST时间(北京时间) -
第三列:get请求方式,使用的协议是http1.1 -
第四列:浏览器的相关信息
上述的access.log是http块的日志文件,也就是不管我们请求哪个server下的域名,该日志文件都可以进行记录。如果想要记录某一个server下的日志,我们在该server下进行配置即可。
另外,Nginx也支持日志格式的自定义,现在我们定义一个myfmt日志格式,并在一个server下进行配置,如下所示:
log_format myfmt '$remote_addr - $remote_user [$time_local] "$request" ';
server {
listen 80;
server_name www.layne.com;
#access_log logs/host.access.log main;
access_log logs/layne.log myfmt;
location / {
root html;
index index.html index.htm;
}
}
然后执行service nginx restart重启nginx,并执行tail -f layne.log检测文件,在浏览器中分别输入http://www.layne.com/和http://www.layne.com/assfgf,会发现layne.log中多了两条记录,并且日志的格式就是我们刚刚自定义的格式。

查看access.log,会发现当我们请求http://www.layne.com/时,access.log并不会进行检测。所以,当我们在某个server下配置日志文件时,http块下的日志文件就不会对该server下域名的请求进行检测了,http块下的日志记录的是所有没有配置日志文件的server。
4.6 Location详解
一个server可以有很多location,请求进来之后,server根据location配置将请求转发到哪里,所以location相当于nginx的出口。其语法规则[7]如下:
语法: location [ = | ~ | ~* | ^~ ] uri { ... }
location @name { ... }
默认值: —
上下文: server, location
-
location URI {}: -
对当前路径及子路径下的所有对象都生效 -
location = URI {}: 注意,URI最好为具体路径 -
精确匹配指定的路径,不包括子路径,故只对当前资源生效 -
location ~ URI {}: -
模糊匹配URI,此处的URI可使用正则表达式, ~表示区分字符大小写 -
location ~* URI {}: -
模糊匹配URI,此处的URI可使用正则表达式, ~*表示不区分字符大小写 -
location ^~ URI {}: -
不使用正则表达式 -
优先级: = > ^~ > ~|~* > /|/dir/
让我们用一个例子解释上面的说法:
location = / {
[ configuration A ]
}
location / {
[ configuration B ]
}
location /documents/ {
[ configuration C ]
}
location ^~ /images/ {
[ configuration D ]
}
location ~* .(gif|jpg|jpeg)$ {
[ configuration E ]
}
-
= /是等值匹配,故只有域名后面没跟任何东西的时候,才匹配到这个location下面。 -
/或/documents/是 最大前缀匹配,即跟谁相同的地方最多(即匹配的地方最多),就匹配哪个。 -
^~ /images/不使用正则表达式,即如果这里匹配上了,不管后面有没正则,都不找后面的匹配了。 -
~* .(gif|jpg|jpeg)$是正则表达式的写法,即请求包含.gif、.jpg、.jpeg,都满足这个匹配。
所以,
-
请求 /匹配配置A -
请求 /index.html匹配配置B -
请求 /documents/document.html匹配配置C -
请求 /images/1.gif匹配配置D -
请求 /documents/1.jpg匹配配置E,这个即和最大前缀匹配,又和正则匹配,当时正则匹配优先级高于最大前缀匹配,所以走正则匹配。
一般来说,location的执行逻辑与location的编辑顺序无关,但需要注意的是:
-
uri前加了 ^~,即不使用正则表达式,表示本条uri一旦匹配上,则不需要继续正则匹配。 -
uri前加了 =,即等值匹配,表示该uri恰好精确匹配上,则不需要继续往下匹配。
而带有正则的匹配是顺序匹配,即多个带正则的location只要第一个满足,就停止后面的正则匹配了。
现在,让我来测试一下吧!
-
启动一个新的Linux虚拟机,比如我启动一个ip为
192.168.218.52的虚拟机,执行如下命令安装htttp应用:yum install httpd -y -
然后进入
/var/www/html目下,执行vim index.html加入以下内容:from 192.168.218.52 -
启动httpd服务:
service httpd start。 -
在浏览器中执行
http://192.168.218.52/,可出现如下页面:
-
配置一下nginx服务器的server块,如下:
server {
listen 80;
server_name www.layne.com;
#access_log logs/host.access.log main;
access_log logs/layne.log myfmt;
location / {
root html;
index index.html index.htm;
}
location /abc {
proxy_pass http://192.168.218.52/;
#在url末尾带上/表示访问该url的首页,不带/则表示把访问的地址与url拼接起来,即访问http://192.168.218.52/abc,可以自己尝试。
}
} -
执行
service nginx restart重启nginx,在浏览器中分别执行http://www.layne.com/和http://www.layne.com/abc,会出现不同的页面。
现在,我们在nginx中模拟一个百度
-
在
www.layne.com所在的server块中加入以下location,并重启nginx。location /aaa {
proxy_pass http://www.baidu.com/;
} -
location /aaa {
proxy_pass https://www.baidu.com/; #把http变为了https,其它的不变
} -
-
再次修改配置,在之前的基础上加一个location,如下:
location ~* /s.* {
proxy_pass https://www.baidu.com;
}
-
在百度搜索框再次输入我们要查询的内容时,能够出现搜索结果,并且浏览器地址栏也是我们的域名。 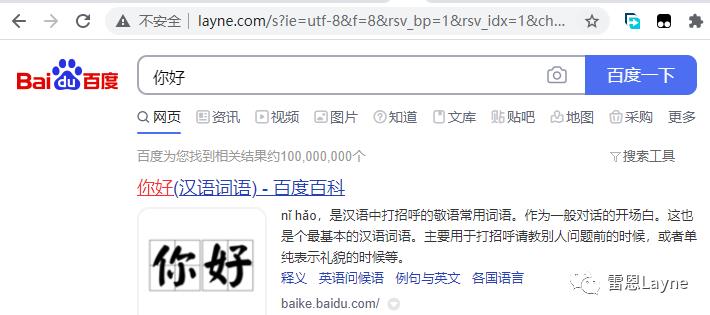
这里,就相当于在我们的网站了嵌套了一个百度,在里面搜索的任何内容都将记录到当前server的日志下面,是不是感觉非常的棒。但这个不太稳定,因为百度为预防这个行为,进行了一些处理,导致搜索某些词可能会跳转到其它地方。
4.7 重新安装nginx
当我们在安装nginx的时候,由于忘记某些配置而导致有些功能无法使用,比如当编译的时候没有启用SSL支持,在配置反向代理到 https的网站时,编辑配置文件报错,无法启动nginx,报错内容如下:
[root@nginx1 conf]# service nginx reload
nginx: [emerg] https protocol requires SSL support in /opt/nginx/conf/nginx.conf:45
nginx: configuration file /opt/nginx/conf/nginx.conf test failed
解决办法:先将nginx.conf备份/root/目录下,删除/opt/nginx和/opt/apps/nginx-1.16.1,然后再解压一份,最后编译安装。
[root@nginx1 nginx-1.16.1]# ./configure --prefix=/opt/nginx --with-http_ssl_module
[root@nginx1 nginx-1.16.1]# make && make install
[root@nginx1 nginx-1.16.1]# cd /opt/nginx/conf/
[root@nginx1 conf]# cp /root/nginx.conf ./
cp: overwrite `./nginx.conf'? yes
[root@nginx1 conf]# service nginx reload
nginx: the configuration file /opt/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /opt/nginx/conf/nginx.conf test is successful
Reloading nginx:
5. 反向代理
所谓的代理其实就是一个中介,比如两台主机A和B,因为某种原因不能直连,在中间插入一个主机C,通过C联通A和B。
早些时候,代理多数是帮助内网client访问外网server用的,这就是正向代理。
后来出现了反向代理[8],"反向"这个词在这儿的意思其实是指方向相反,即代理将来自外网客户端的请求转发到内网服务器,是从外到内的。
所以,代理服务器根据其代理对象的不同,可以分为正向代理服务器与反向代理服务器。
5.1 正向代理服务器
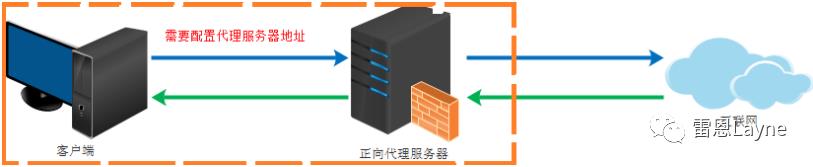
正向代理是对客户端的代理。客户端 C 想要从服务端 S 获取资源,但由于某些原因不能,直接访问服务端,而是通过另外一台主机 P 向服务端发送请求。当服务端处理完毕请求后,将响应发送给主机 P,主机 P 在接收到来自服务端的响应后,将响应又转给了客户端 C。此时的主机 P,就称为客户端 C 的正向代理服务器。
比如我们国内访问谷歌,直接访问访问不到,我们可以通过一个正向代理服务器,请求发到代理服,代理服务器能够访问谷歌,这样由代理去谷歌取到返回数据,再返回给我们,这样我们就能访问谷歌了。
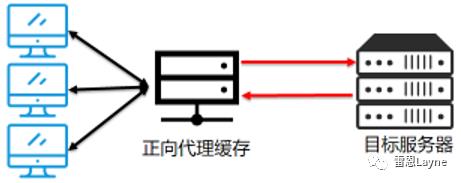
Maven的Nexus私服也是典型的用于“缓存”的正向代理服务器:
正向代理的用途:
-
访问原来无法访问的资源,如google -
可以做缓存,加速访问资源 -
对客户端访问授权,上网进行认证 -
代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息。
5.2 反向代理服务器
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。这个时候,对于客户端来说,感觉不到内部目标服务器的存在。
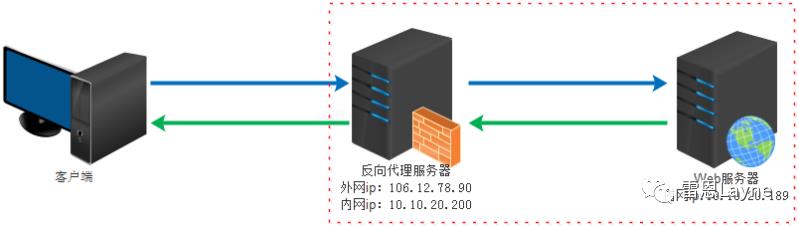
反向代理的作用:
-
保证内网的安全,阻止web攻击,大型网站,通常将反向代理作为公网访问地址,Web服务器是内网 -
负载均衡,通过反向代理服务器来优化网站的负载
总的来说:
-
正向代理即是客户端代理, 代理客户端, 服务端不知道实际发起请求的客户端 -
反向代理即是服务端代理, 代理服务端, 客户端不知道实际提供服务的服务端
5.3 反向代理之负载均衡
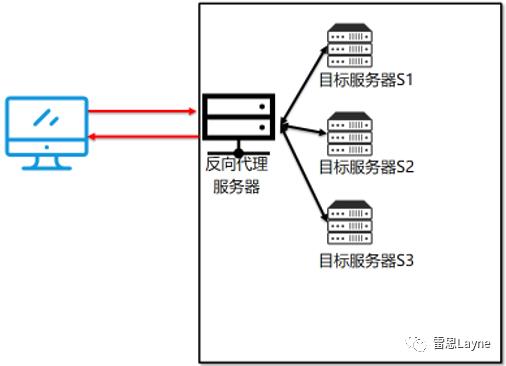
由于反向代理服务器处在最终处理请求访问的服务器之前,因此可以在代理服务器上做负载均衡。
所谓的负载均衡(Load Balancing),就是将对请求的处理分摊到多个操作单元上进行。这个均衡是指在大批量访问前提下的一种基本均衡,并非是绝对的平均。对于 Web 工程中的负载均衡,就是将相同的 Web 应用部署到多个不同的 Web 服务器上,形成多个 Web 应用服务器。当请求到来时,由负载均衡服务器负责将请求按照事先设定好的比例向 Web 应用服务器进行分发,从而增加系统的整体吞吐量。
负载均衡可以通过负载均衡软件实现,也可通过硬件负载均衡器实现。
(1)硬件负载均衡
硬件负载均衡器的性能稳定,且有生产厂商作为专业的服务团队。但其成本很高,一台硬件负载均衡器的价格一般都在十几万到几十万,甚至上百万。知名的负载均衡器有 F5、Array、深信服、梭子鱼等。

(2)软件负载均衡
软件负载均衡成本几乎为零,基本都是开源软件。例如:LVS、HAProxy、Nginx 等。
下面我们Nginx反向代理服务器配置负载均衡。
Nginx配置负载均衡有两种方式,我将分别进行介绍。
方式一
-
修改nginx.conf的http块下的内容:
# 默认负载权重是一样的
upstream rss{
server 192.168.218.52;
server 192.168.218.53;
}
server {
listen 80;
server_name www.layne.com;
#access_log logs/host.access.log main;
access_log logs/layne.log myfmt;
location / {
root html;
index index.html index.htm;
}
location /dogs {
proxy_pass http://rss/;
}
} -
这里最好也把http块下的
keepalive_timeout设置为0,即让会话保持时间为0,便于看出负载切换的效果,但部署时需要设置合适的数值来提高效率。keepalive_timeout 0; -
执行
service nginx restart重启nginx -
分别在layne2和layne3虚拟机安装执行如下命令安装httpd:
yum install httpd -y -
进入
/var/www/html目下,执行vim index.html分别在layne2和layne3里加入from 192.168.218.52、from 192.168.218.53。 -
启动两台虚拟机上的httpd服务:
service httpd start。 -
在浏览中分别输入
http://192.168.218.52/和http://192.168.218.53/进行测试,出现from 192.168.218.5x即代表httpd配置成功。 -
最后,输入
http://www.layne.com/dogs,不断进行刷新,可看到页面内容发生变化,说明负载均衡配置成功。
一般来说,中小企业一般使用方式一。
方式二
在Nginx服务器上配置hosts本地域名解析:
[root@nginx1 logs]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.218.55 nginx1
192.168.218.50 layne
192.168.218.51 layne1
192.168.218.52 layne2 xxx
192.168.218.53 layne3 xxx
192.168.218.54 layne4
[root@nginx1 logs]#
修改nginx.conf配置文件,在server块中添加如下配置
location /cats {
proxy_pass http://xxx/;
}
重启nginx:service nginx restart
浏览器中输入http://www.layne.com/cats不端刷新进行测试。
5.4 负载均衡进阶
在5.3节我们采用两种方式实现了负载均衡,对于方式一还有许多的扩充配置,我们一起来看看吧。
Nginx提供的负载均衡策略[9]有2种:内置策略和扩展策略。内置策略为轮询,加权轮询,Ip hash(ip绑定)。扩展策略,就天马行空,只有你想不到的没有他做不到的啦,最常用的扩展策略为fair、url_hash。扩展策略一般不能直接使用,需要安装安三方扩展包。
轮询:nginx默认就是轮询其权重都默认为1,服务器处理请求的顺序:ABABABABAB....
# 默认负载权重是一样的
upstream rss{
server 192.168.218.52;
server 192.168.218.53;
}
加权轮询:跟据配置的权重的大小而分发给不同服务器不同数量的请求。如果不设置,则默认为1。下面服务器的请求顺序为:ABBABBABBABBABB....
# 加权轮训
upstream rss{
server 192.168.218.52 weight=1;
server 192.168.218.53 weight=2;
}
ip_hash:nginx会让相同的客户端ip请求相同的服务器。
upstream rss{
server 192.168.218.52;
server 192.168.218.53;
ip_hash;
}
热备:如果你有2台服务器,当一台服务器发生事故时,才启用第二台服务器给提供服务。服务器处理请求的顺序:AAAAAA突然A挂啦,BBBBBBBBBBBBBB.....
upstream rss{
server 192.168.218.52;
server 192.168.218.53 backup; #热备
}
fair(第三方):按后端服务器的响应时间来分配请求,响应时间短的优先分配。
url_hash(第三方):按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
关于第三方的扩展策略,可参考https://www.cnblogs.com/ztlsir/p/8945043.html。
nginx负载均衡配置的几个状态参数:
-
down:表示当前的server暂时不参与负载均衡。 -
backup:预留的备份机器。当其他所有的非backup机器出现故障或者忙的时候,才会请求backup机器,因此这台机器的压力最轻。 -
max_fails:允许请求失败的次数,默认为1。当超过最大次数时,返回proxy_next_upstream 模块定义的错误。 -
fail_timeout:在经历了max_fails次失败后,暂停服务的时间。max_fails可以和fail_timeout一起使用。
upstream rss {
server 192.168.218.52 weight=2 max_fails=2 fail_timeout=2;
server 192.168.218.53 weight=1 max_fails=2 fail_timeout=1;
#server 服务器的ip 权重 最大失败次数 暂停服务的时间
}
6. session共享
6.1 session共享的解决方案
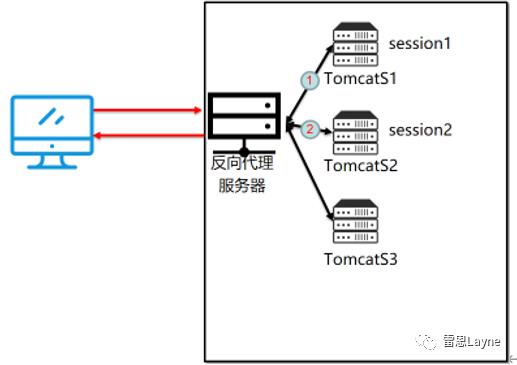
当nginx做了负载均衡之后,同一个ip的url请求服务器的时候,负载均衡会根据每台服务器的权重等一些设置将请求转发到不同的服务器上去进行处理,这样会带来一个很大的问题,即不能保证带有状态的请求的完整性。假如A用户登陆系统,负载均衡机制把A用户的登陆请求分发给了S1服务器,这个时候S1服务器上就会记录A用户登陆的session信息。登陆成功后,当A用户进行相应的操作,比如进入个人中心,这时候这个请求经过反向代理服务器的时候,负载均衡机制根据当前集群中的各个服务器的压力性能等情况可能把请求分发给了S2服务器处理,那么这个时候会去验证用户的状态是否登录,也就是验证session。可是A用户的session保存在了S1服务器上,造成再S2服务器上请求验证状态找不到对应的session,就会认为用户未登录而做的异常操作,提醒用户去登录,从而跳转到登录页面。这就是负载均衡针对带有状态的请求的一个弊端。
本小节引用自负载均衡的session共享[10],里面加了少部分自己的理解
常用的解决方案有4种。
(1)不使用session,使用cookie
session是存放在服务器端的,cookie是存放在客户端的,我们可以把用户访问页面产生的session放到cookie里面,就是以cookie为中转站。你访问web服务器A,产生了session然后把它放到cookie里面,当你的请求被分配到B服务器时,服务器B先判断服务器有没有这个session,如果没有,再去看看客户端的cookie里面有没有这个session,如果也没有,说明session真的不存,如果cookie里面有,就把cookie里面的sessoin同步到服务器B,这样就可以实现session的同步了。其实session底层原理也是通过cookie实现的,但它是自动实现的,不需要人为进行操作,但是这里我们是通过编程cookie的方式实现session共享。
说明:这种方法实现起来简单,方便,也不会加大数据库的负担,但是如果客户端把cookie禁掉了的话,那么session就无从同步了,这样会给网站带来损失;cookie的安全性不高,虽然它已经加了密,但是还是可以伪造的,所以这种方式也是不推荐的。
(2)session存在数据库mysql
session保存在数据库中,是把session表和其他的数据表存放在一起,那么当用户只要登录后随便操作了些什么就要去数据库验证一下session的状态,这样无疑加重了mysql数据库的压力;如果数据库也做了集群的话,那么也就是说每个数据库集群的节点都得保存这个session表,而且要保证每个集群的节点中数据库的session表的数据保持一致,实时同步。
说明:session保持在数据库,加重了数据库的IO,增大数据库的压力和负担,从而影响数据库的读写性能,而且mysql集群的话也不利于session的实时同步。
(3)session存在缓存memcache或者redis中
这种方式来同步session,不会加大数据库的负担,而且安全性比用cookie保存session大大的提高,把session放到内存里面,比从文件中读取要快很多。但是memcache把内存分成很多种规格的存储块,有块就有大小,这种方式也就决定了,memcache不能完全利用内存,会产生内存碎片,如果存储块不足,还会产生内存溢出。
memcache可以做分布式,php配置文件中设置存储方式就为memcache,这样php自己会建立一个session集群,将session数据存储在memcache中。
(4)ip_hash技术
upstream rss{
server 192.168.218.52;
server 192.168.218.53;
ip_hash;
(5)tomcat 本身带有复制session的功能,不过由于tomcat的性能有限,这种方案基本不用。
下面我将通过memcache实现session共享。
6.2 memcache实现session共享
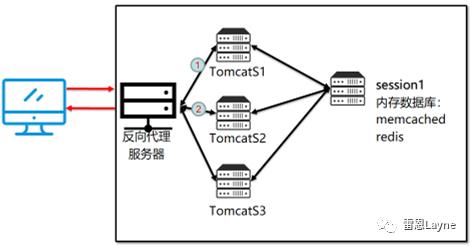
(1)安装jdk、tomcat
在layne2和layne3虚拟机上安装jdk和tomcat。
-
首先把相应的软件
apache-tomcat-7.0.69.tar.gz和jdk-7u80-linux-x64.rpm拷贝到两台虚拟机的/opt/apps目录下(可联系博主获取本文所有软件),然后执行下面命令进行安装:[root@layne2 ~]# cd /opt/apps
[root@layne2 apps]# ls
apache-tomcat-7.0.69 apache-tomcat-7.0.69.tar.gz jdk-7u80-linux-x64.rpm
[root@layne apps]# rpm -ivh jdk-7u80-linux-x64.rpm
Preparing... ########################################### [100%]
1:jdk ########################################### [100%]
Unpacking JAR files...
rt.jar...
jsse.jar...
charsets.jar...
tools.jar...
localedata.jar...
jfxrt.jar...
[root@layne2 apps]# find / -name java
/etc/pki/ca-trust/extracted/java
/etc/pki/java
/usr/bin/java
/usr/java
/usr/java/jdk1.7.0_80/bin/java
/usr/java/jdk1.7.0_80/jre/bin/java
[root@layne2 apps]# ll /usr/java
total 4
lrwxrwxrwx 1 root root 16 Feb 11 18:58 default -> /usr/java/latest
drwxr-xr-x 8 root root 4096 Feb 11 18:57 jdk1.7.0_80
lrwxrwxrwx 1 root root 21 Feb 11 18:58 latest -> /usr/java/jdk1.7.0_80 -
配置环境变量,进入
vim /etc/profile,在文件最后加入以下两行代码:export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin -
让配置生效,使用
source /etc/profile -
测试安装配置是否成功
[root@layne ~]# java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
[root@layne ~]# jps
1423 Jps -
解压
apache-tomcat-7.0.69.tar.gztar -zxvf apache-tomcat-7.0.69.tar.gz -
编辑
apache-tomcat-7.0.69/webapps/ROOT/index.jsp[root@layne2 apps]# cd apache-tomcat-7.0.69/webapps/ROOT/
[root@layne2 ROOT]# vim index.jsp使用
:%d删除index.jsp里面的全部内容,并添加:from 192.168.218.52 session=<%=session.getId()%> -
在layne3上进行同样的安装配置操作。
-
启动tomcat
[root@layne2 bin]# pwd
/opt/apps/apache-tomcat-7.0.69/bin
[root@layne2 bin]# ./startup.sh
Using CATALINA_BASE: /opt/apps/apache-tomcat-7.0.69
Using CATALINA_HOME: /opt/apps/apache-tomcat-7.0.69
Using CATALINA_TMPDIR: /opt/apps/apache-tomcat-7.0.69/temp
Using JRE_HOME: /usr/java/default
Using CLASSPATH: /opt/apps/apache-tomcat-7.0.69/bin/bootstrap.jar:/opt/apps/apache-tomcat-7.0.69/bin/tomcat-juli.jar -
浏览器中输入
http://192.168.218.52:8080/,就可以出现页面了,并显示当前的sessionid,刷新页面,session也不会变。
(2)配置nginx.conf
修改nginx.conf为如下配置
upstream rss{
server 192.168.218.52:8080;
server 192.168.218.53:8080;
}
# 如果默认不写8080,则默认为80端口,如果ip后面写上8080端口,则请求的是tomcat的服务。
# 当然,也可以通过修改tomcat配置,让tomcat服务端口变为80,这样我们的Ip地址后面就不用加80端口了
# 但是,要把httpd服务关了,因为httpd服务的端口也是80,会占用端口
重启nginx:service nginx restart
访问http://www.layne.com/dogs,不断刷新,会发现session一直在改变,接下来我们就配置session共享了。
(3)nginx服务器安装memcached
-
安装libevent
yum install libevent -y -
安装memcached
yum install memcached -y -
启动memcached
[root@nginx1 conf]# memcached -d -m 128m -p 11211 -l 192.168.218.55 -u root -P /opt/mempid
[root@nginx1 conf]# ps aux |grep memcached
root 1870 0.0 0.0 330844 884 ? Ssl 19:45 0:00 memcached -d -m 128m -p 11211 -l 192.168.218.55 -u root -P /opt/mempid
root 1877 0.0 0.0 103256 864 pts/2 S+ 19:45 0:00 grep memcached
[root@nginx1 conf]# cat /opt/mempid
1870可以看到,/opt/mempid存储的就是memcached进程的pid,对上面memcached的启动命令进行解释:
-
-d:后台启动服务 -
-m:缓存大小 -
-p:启动的端口 -
-l:所在服务器的ip地址 -
-P:服务器启动后的系统进程ID,存储的文件 -
-u:服务器启动是以哪个用户名作为管理用户
(4)配置session共享
-
拷贝session共享所需的jar包到两个虚拟机的
apache-tomcat-7.0.69/lib目录下,如下所示: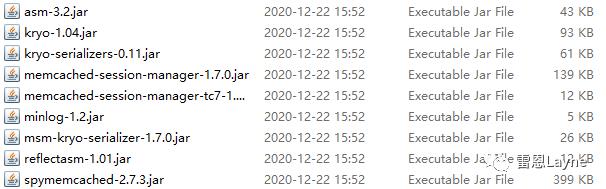 以上jar包,有需要的可以留言或者直接私信我。
以上jar包,有需要的可以留言或者直接私信我。 -
配置两个的tomcat,在每个
apache-tomcat-7.0.69/conf/context.xml的<Context>...</Context>结点里面加入如下内容:<Manager className="de.javakaffee.web.msm.MemcachedBackupSessionManager"
memcachedNodes="n1:192.168.218.55:11211"
sticky="false"
lockingMode="auto"
sessionBackupAsync="false"
requestUriIgnorePattern=".*.(ico|png|gif|jpg|css|js)$"
sessionBackupTimeout="1000" transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory"
/> -
执行以下命令重启两个tomcat
[root@layne2 bin]# pwd
/opt/apps/apache-tomcat-7.0.69/bin
[root@layne2 bin]# ./shutdown.sh && ./startup.sh -
在浏览器中输入
http://www.layne.com/dogs,不断刷新页面,发现session保持不变。显示类似如下的内容:from 192.168.218.53 session=4493A2D98EC0934FA892B16BA0D3AAFE-n1
至此,session共享就配置成功了。接下来,我们来配置nginx动静分离。
7. 动静分离
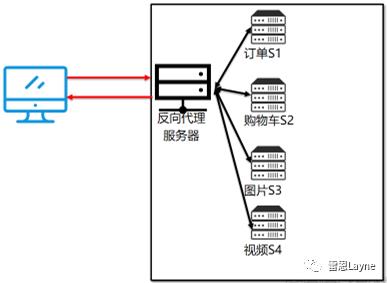
Nginx动静分离简单来说就是把动态和静态请求分开,不能理解成知识单纯的把动态页面和静态页面物理分离。严格意义上说应该是动态请求和静态请求分开,可以理解成使用Nginx处理静态请求,Tomcat处理动态请求。
动静分离从目前实现方式大致分为两种:
-
方式一:纯粹的把静态文件独立成单独的域名,放在独立的服务器上,也是目前主流推崇的方案。 -
方式二:动态和静态文件混合在一起发布,通过nginx分开。通过配置location指定不同的后缀名实现不同的请求转发。
接下来,我通过方式一实现动静分离。下面是我们即将配置动静分离的服务器拓扑图:
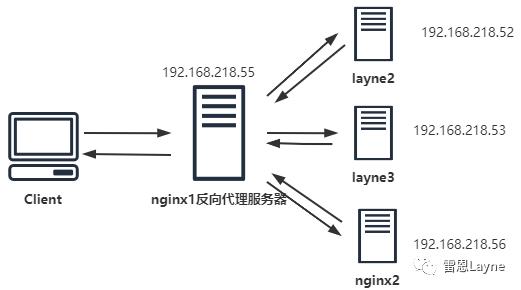
-
nginx1作为反向代理服务器,负责session共享、负载均衡、反向代理,区分动态请求和静态请求并转发给不同的服务器 -
layne2和layne3作为web服务器,部署了tomcat,负责解析动态请求 -
nginx2中存放的是静态资源,负责解析静态请求。
让我们实现nginx的动静分离吧!
-
先在两个tomcat中执行
./shutdown.sh关闭 -
编辑layne2中tomcat的
apache-tomcat-7.0.69/webapps/ROOT/index.jsp文件,修改为以下内容:<link rel="stylesheet" type="text/css" href="/css/index.css">
<img src="/image/logo.jpg" ><br/>
<font class="myfont">
from 192.168.218.52 <br/>
session=<%=session.getId()%></font> -
在
apache-tomcat-7.0.69/webapps/ROOT/目下执行如下命令把layne2中的index.jsp拷贝到layne3的相同目录下:scp index.jsp 192.168.218.53:`pwd` -
修改layne3中的tomcat,把index.jsp中的ip改为
192.168.218.53 -
从nginx1克隆nginx2,修改nginx2的
/etc/udev/ rules.d/70-persistent-net.rules[root@nginx2 rules.d]# pwd
/etc/udev/rules.d
[root@nginx2 rules.d]# vim 70-persistent-net.rules将原来的eth0一行删掉,并将eth1改为eth0 。这里参考。
-
-
在nginx2服务器上创建目录 /data/image和/data/css,然后将logo.jpg和index.css上传到对应的目录。
[root@nginx2 ~]# mkdir -p /data/image /data/csslogo.jpg为:

index.css内容为:
.myfont{color:#F00;font-size:45px} -
修改nginx2服务器上的nginx.conf配置文件,执行
vim /opt/nginx/conf/nginx.conf,加入以下内容:server {
listen 80;
server_name 192.168.218.56;
location / {
root /mnt;
autoindex on;
}
location /image {
root /data;
}
location /css {
root /data;
}
#不用再路径最后加/,不加/意味着可以拼接路径,加了/意味着直接访问填写的路径
} -
修改nginx1服务器上的nginx.conf配置文件,内容如下:
upstream rss{
server 192.168.218.52:8080;
server 192.168.218.53:8080;
}
server {
listen 80;
server_name www.layne.com;
#access_log logs/layne.log myfmt;
location / {
proxy_pass http://rss/;
}
location /image {
proxy_pass http://192.168.218.56;
}
location /css {
proxy_pass http://192.168.218.56;
} -
重启nginx1、nginx2,重启两个tomcat。
-
在nginx1服务器中输入以下命名开启memcached
memcached -d -m 128m -p 11211 -l 192.168.218.55 -u root -P /opt/mempid -
在浏览器中输入
http://www.layne.com/测试,出现如下页面,不断刷新页面,session也不会变。
end
我是雷恩Layne,欢迎关注。如果在学习过程中有什么疑问,欢迎随时和我沟通交流。一起学习,一起努力,未来必然成为更好的自己!
长按图片一键关注
参考资料
Nginx和Apache区别: https://blog.51cto.com/11837799/1826624
[2]安装Nginx: https://wxler.github.io/2021/02/10/112210/#src-build%E5%AE%89%E8%A3%85nginx
[3]work和master进程的作用: https://www.cnblogs.com/jianmingyuan/p/13960906.html
[4]Nginx惊群问题: https://blog.csdn.net/weixin_33759269/article/details/93019512
[5]Nginx的I/O模型: https://blog.csdn.net/u010832551/article/details/85160336
[6]Linux可以打开的最大文件数: https://blog.csdn.net/sunny05296/article/details/54952009
[7]tengine配置文档: http://tengine.taobao.org/nginx_docs/cn/docs/http/ngx_http_core_module.html
[8]正向代理与反向代理: https://www.cnblogs.com/taostaryu/p/10547132.html
[9]Nginx负载均衡策略: https://www.runoob.com/w3cnote/nginx-proxy-balancing.html
[10]负载均衡的session共享: https://www.cnblogs.com/zengguowang/p/8261695.html
以上是关于从0开始,在Linux中配置Nginx反向代理负载均衡session共享动静分离的主要内容,如果未能解决你的问题,请参考以下文章
Nginx入门:通俗理解反向代理和负载均衡,简单配置Nginx