spark3.1.1安装(spark on yarn)
Posted 逃跑的沙丁鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark3.1.1安装(spark on yarn)相关的知识,希望对你有一定的参考价值。
目录
- 环境scala2.12.12
- hadoop3.2.2
- centos7
1 安装scala2.12.12
1.1 下载scala2.12.12
https://www.scala-lang.org/download/2.12.12.html
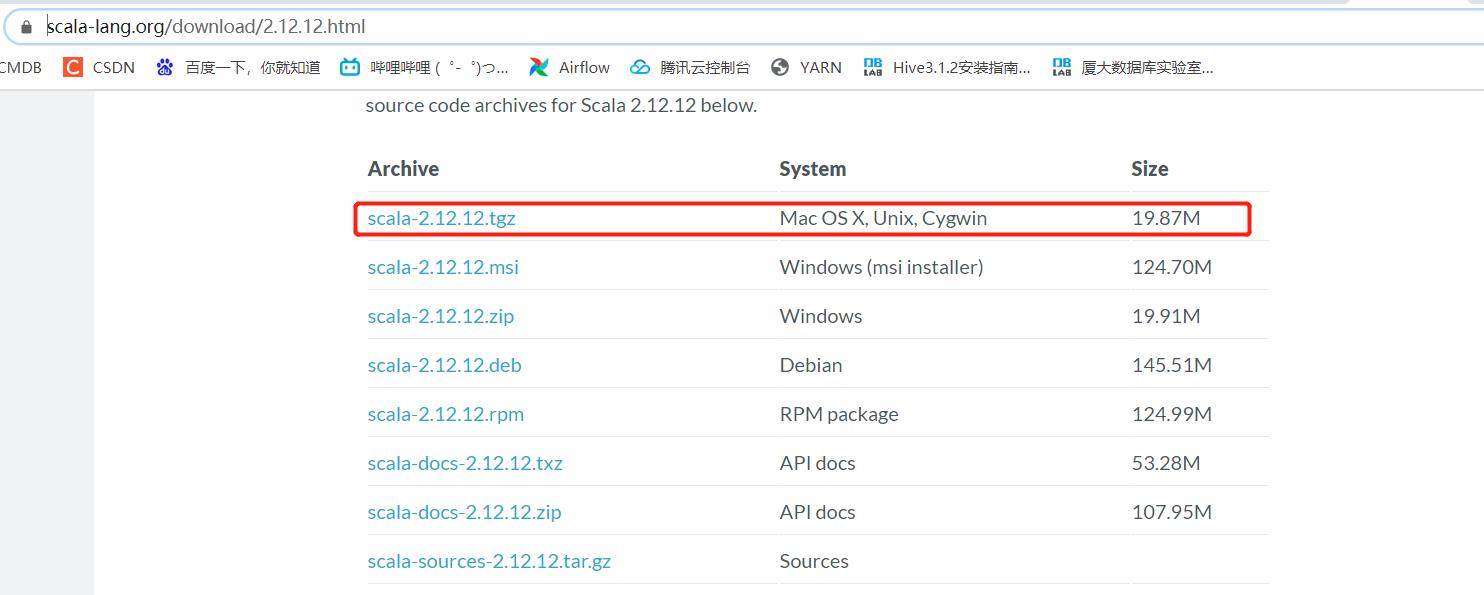
1.2 上传解压
node1
[liucf@node1 softfile]$ tar -xvf scala-2.12.12.tgz -C ../soft1.3 配置环境变量SCALA_HOME
[liucf@node1 scala-2.12.12]$ sudo vim /etc/profile

[liucf@node1 scala-2.12.12]$ source /etc/profile1.4 验证

1.5 分发解压包配置node2,node3机器
scp -r scala-2.12.12 liucf@node2:/home/liucf/soft
scp -r scala-2.12.12 liucf@node3:/home/liucf/soft
sudo scp /etc/profile root@node2:/etc
sudo scp /etc/profile root@node3:/etc
source /etc/profile
scala 安装完成
2 其他安装
hadoop3.2.2 安装参考
https://blog.csdn.net/m0_37813354/article/details/116561918
3 spark 安装配置
3.1 下载上传解压
下载
https://mirrors.bfsu.edu.cn/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz
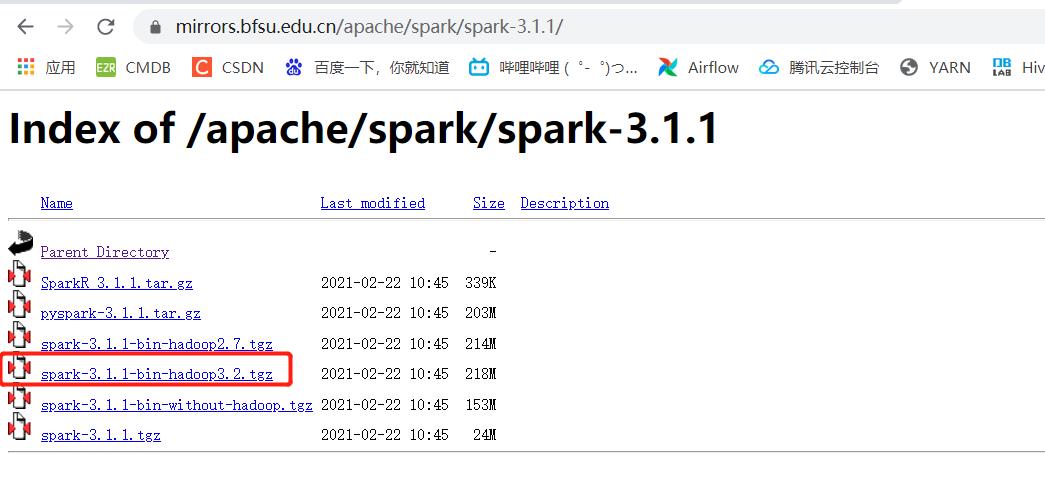
解压
[liucf@node1 softfile]$ tar -xvf spark-3.1.1-bin-hadoop3.2.tgz -C ../soft修改解压目录名称
[liucf@node1 soft]$ mv spark-3.1.1-bin-hadoop3.2 spark-3.1.1![]()
![]()
3.2 配置spark-env.sh
[liucf@node1 conf]$ cp spark-env.sh.template spark-env.sh
export JAVA_HOME=/home/liucf/soft/jdk1.8.0_121
export SCALA_HOME=/home/liucf/soft/scala-2.12.12
# Options read in YARN client/cluster mode
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
export SPARK_CONF_DIR=/home/liucf/soft/spark-3.1.1/conf
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
export HADOOP_CONF_DIR=/home/liucf/soft/hadoop-3.2.2
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
export YARN_CONF_DIR=/home/liucf/soft/hadoop-3.2.2/etc/hadoop
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
3.3 配置spark-defaults.conf
[liucf@node1 conf]$ cp spark-defaults.conf.template spark-defaults.conf
这个配置暂时只修改名称内容暂时不做修改
3.4 配置SPARK_HOME
export SPARK_HOME=/home/liucf/soft/spark-3.1.1
PATH=$SPARK_HOME/bin:$SCALA_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
分发到其他两台机器
scp -r /etc/profile root@node2:/etc/profile
scp -r /etc/profile root@node3:/etc/profile
使生效,三台机器都执行
source /etc/profile3.5 验证spark 自带的例子PI
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi --name SparkPi --num-executors 1 --executor-memory 1g --executor-cores 1 /home/liucf/soft/spark-3.1.1/examples/jars/spark-examples_2.12-3.1.1.jar 100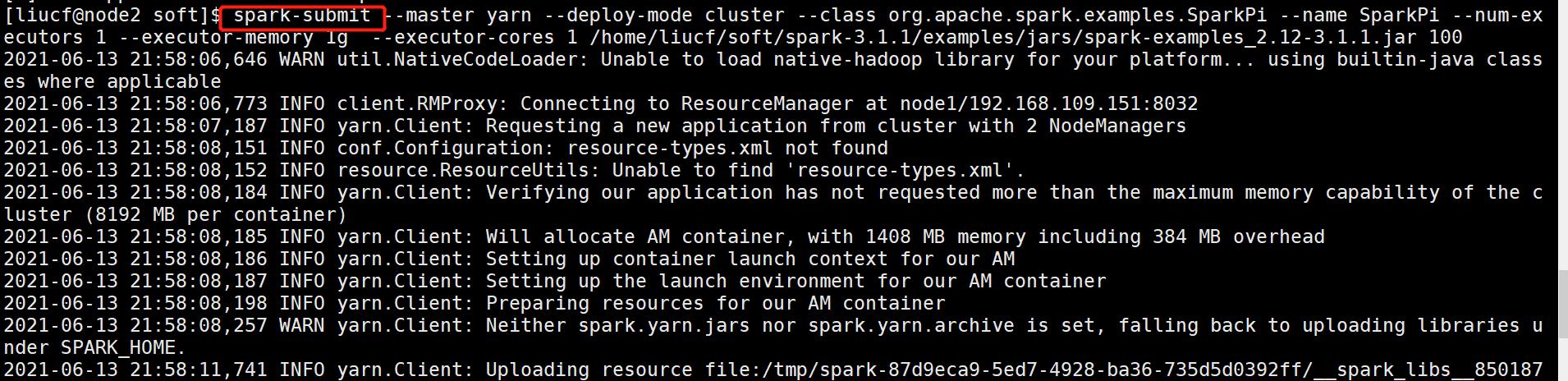
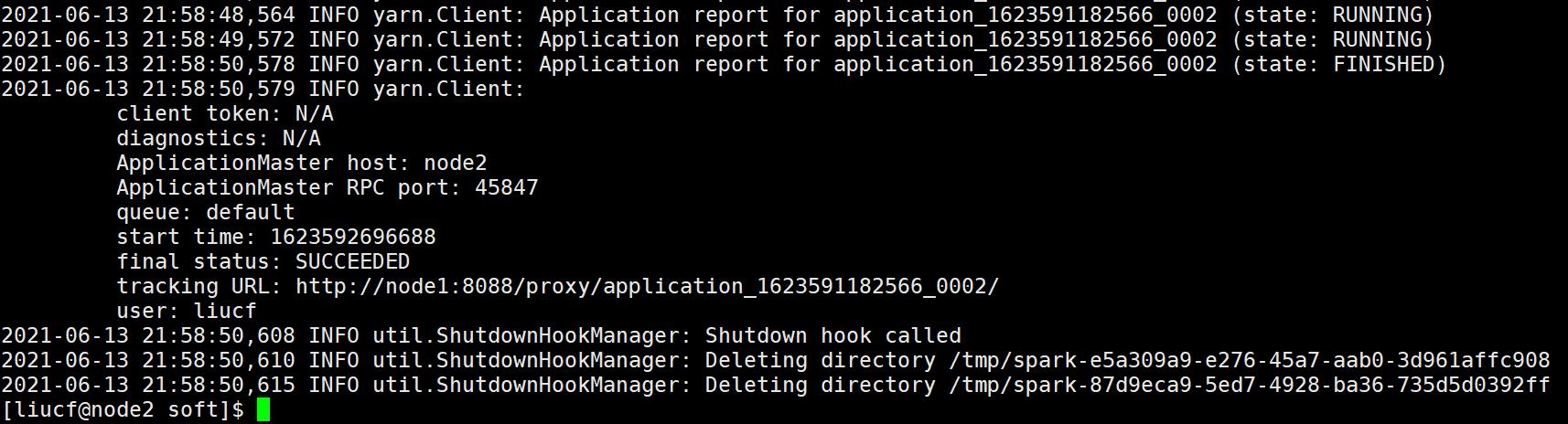
yarn 上能看到任务正常执行完毕

日志可以聚合到hdfs 能够使用yarn 上执行的日志

但是spark 自己的历史执行日志是没有被记录下来的。
4 spark JobHistoryServer 配置
4.1 现在hdfs 上创建日志聚合目录
hdfs dfs -mkdir -p /spark/sparkhistory后面会使用到不然会报错目录找不到
4.2 配置spark-defaults.conf
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.yarn.historyServer.address node1:18080
spark.history.ui.port 18080
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/spark/sparkhistory
spark.eventLog.compress true4.3 配置spark-env.sh
增加如下配置
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node1:8020/spark/sparkhistory"
注意其中:Dspark.history.fs.logDirectory对应的目录必须是和spark-defaults.conf里配置的 spark.eventLog.dir hdfs://node1:8020/spark/sparkhistory 保持一致。
4.4 启动
/home/liucf/soft/spark-3.1.1/sbin/start-history-server.sh4.5 验证结果
jps验证

18080 端口页面验证

完成
以上是关于spark3.1.1安装(spark on yarn)的主要内容,如果未能解决你的问题,请参考以下文章