大数据系列12:spark graphframe
Posted IE06
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据系列12:spark graphframe相关的知识,希望对你有一定的参考价值。
1. 简介
Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求。
众所周知·,社交网络中人与人之间有很多关系链,例如Twitter、Facebook、微博和微信等,这些都是大数据产生的地方都需要图计算,现在的图处理基本都是分布式的图处理,而并非单机处理。Spark GraphX由于底层是基于Spark来处理的,所以天然就是一个分布式的图处理系统。
GraphX的代码大部分都是围绕Partition的优化进行的。这在某种程度上说明了点分割的存储和相应的计算优化,的确是图计算框架的重点和难点。
点和边实际都不是以表Collection[tuple]的形式存储的,而是由VertexPartition/EdgePartition在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在RDD转换过程中是共用的。
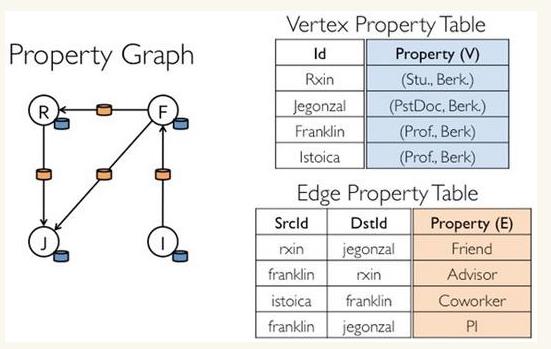
2. 存储模式
巨型图的存储总体上有边分割和点分割两种存储方式。2013年,GraphLab2.0将其存储方式由边分割变为点分割,在性能上取得重大提升,目前基本上被业界广泛接受并使用。
-
边分割(Edge-Cut):每个顶点都存储一次,但有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。
-
点分割(Vertex-Cut):每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
Graphx借鉴PowerGraph,使用的是Vertex-Cut(点分割)方式存储图,用三个RDD存储图数据信息:
- VertexTable(id, data):id为Vertex id,data为Edge data
- EdgeTable(pid, src, dst, data):pid为Partion id,src为原定点id,dst为目的顶点id
- RoutingTable(id, pid):id为Vertex id,pid为Partion id
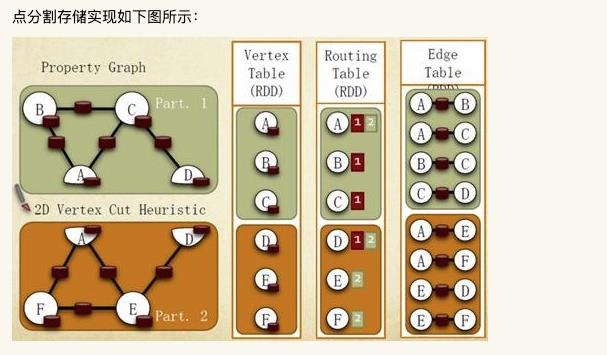
3. 计算模式
GraphX的Graph类提供了丰富的图运算符,大致结构如下图所示。可以在官方GraphX Programming Guide中找到每个函数的详细说明。
由于graphx没有python接口,因此使用替代品graphframes。
4. 简单应用
首先下载jar包:
https://spark-packages.org/package/graphframes/graphframes
放到spark的jar文件夹下。
如果用的是anaconda,则在site-packages/pyspark/jars文件夹下。
from pyspark import SparkContext
from pyspark.sql.context import SQLContext
from pyspark.sql import types
sc = SparkContext('local', 'graph')
sqlContext = SQLContext(sc)
data = sqlContext.read.csv("links.csv",header=True,schema = StructType([
StructField('src', LongType(),True),
StructField('dst',LongType(),True),
StructField("value",FloatType(),True)]))
data.show()
from pyspark.sql.types import *
from graphframes import *
data.createOrReplaceTempView("data_sql")
ver1 = sqlContext.sql("select distinct src from data_sql")
ver2 = sqlContext.sql("select distinct dst from data_sql")
ver = ver1.unionAll(ver2).withColumnRenamed("src", "id").distinct()
g = GraphFrame(ver, data)
sc.setCheckpointDir('./spark-checkpoint')
res = g.connectedComponents()
res.show()
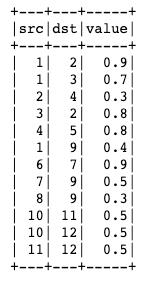
原始数据如下:
计算结果如下:

以上是关于大数据系列12:spark graphframe的主要内容,如果未能解决你的问题,请参考以下文章