多线程基础线程池
Posted 烟锁迷城
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程基础线程池相关的知识,希望对你有一定的参考价值。
1、基础认知
线程池的作用是提前创建好若干个线程放在一个容器里,如果有任务需要处理,则将任务直接分配给线程池中的线程来执行,任务处理完后这个线程不会被销毁,而是等待后续分配任务,它具有以下效果:
- 降低创建线程和销毁线程的性能开销
- 提高响应速度,当有新任务需要执行是不需要等待线程创建就可以立即执行
- 合理的设置线程池大小可以避免因为线程数超过硬件限制带来的问题
2、具体使用
在java中,提供了四种预定线程池来进行使用。
- newFixedThreadPool,创建固定数量的线程池
- newSingleThreadExecutor:创建只有一个线程的线程池
- newCachedThreadPool:创建可伸缩的线程池
- newScheduledThreadPool:创建有定时调度的线程池
在示例中,循环显示的结果总是固定的三个线程,其他的线程池不再赘述。
public class Pool implements Runnable{
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(3);
IntStream.range(1,100).forEach(i-> {
executorService.execute(new Pool());
});
}
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
}
3、原理分析
3.1、核心参数
无论是什么样的线程池,其构架都依托于ThreadPoolExecutor,其核心参数如下(七个):
- corePoolSize:核心线程数
- maximumPoolSize:最大线程数(临时线程数=maximumPoolSize-corePoolSize)
- keepAliveTime:超时时间,超出核心线程数量以外的线程存活时间,即临时线程存活时间
- unit:存活时间单位
- workQueue:阻塞队列,保存执行任务的队列
- threadFactory:线程工厂,创建新线程使用的工厂
- handler:拒绝策略,当任务无法执行的时候的处理方式
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
核心原理是生产者消费者模式,有请求就处理,没有就阻塞,所以必须要有员工:核心线程,要有等待队列:阻塞队列,当请求太多,无法消耗,可以扩容:增加临时线程,或者拒绝:拒绝策略。
3.2、执行原理
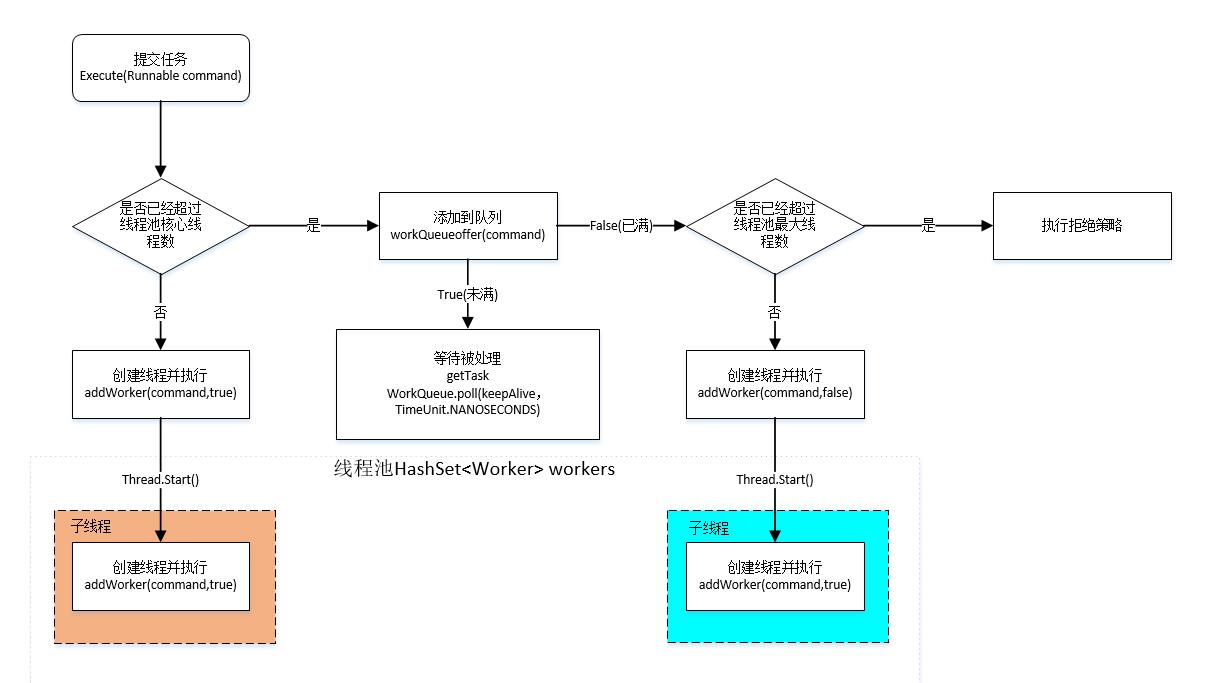
- 任务提交进入线程池
- 判断线程池线程数是否已经达到核心线程数,若是未达到,则创建核心线程,开始执行任务。线程也会从阻塞队列中获得任务进行执行。
- 若核心线程已满,就将任务放置到阻塞队列,其他线程可以消费队列中的任务
- 若阻塞队列已满,就判断线程池是否达到最大线程数,若是未达到,就创建临时线程,开始消费任务
- 若是达到最大线程数,就执行拒绝策略。
public void execute(Runnable command) {
//如果当前线程为空
if (command == null)
//抛出空指针异常
throw new NullPointerException();
//存储线程状态的原子整数
int c = ctl.get();
//如果线程数小于核心线程数
if (workerCountOf(c) < corePoolSize) {
//创建新的线程,true代表创建的是核心线程数
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程处于运行状态,并且队列没有装满
if (isRunning(c) && workQueue.offer(command)) {
//再次获得线程状态
int recheck = ctl.get();
//如果线程不为运行状态,就从队列中移除线程任务
if (! isRunning(recheck) && remove(command))
//拒绝
reject(command);
//如果线程为运行状态,判断线程数是否为0
else if (workerCountOf(recheck) == 0)
//若为0,添加临时线程
addWorker(null, false);
}
//否则,添加临时线程数
else if (!addWorker(command, false))
reject(command);
}
ct1是一个原子整数,高3位存储线程状态,低29位存储线程数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
addWorker是添加线程的方法,所有的新创建线程都会被加入到workers,private final HashSet<Worker> workers = new HashSet<Worker>();,一个HashSet中。当新线程添加成功后,worker线程启动。
private boolean addWorker(Runnable firstTask, boolean core) {
//goto语句的位置
retry:
//死循环
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
//获取线程数
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//原子递增方法,将工作线程数增加一个
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//构建一个worker,可以理解为一个新的线程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
//加入重入锁,防止线程冲突
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//构建成功,将线程加入workers中
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//如果添加成功
if (workerAdded) {
//线程启动
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
在worker中,启动任务线程的run方法,这里不启动start方法的原因是不需要再开启一个新的线程。getTask()方法是从任务队列中获取一个任务,当任务队列为空,线程就会被阻塞,阻止线程被回收。当getTask()方法返回值为null,循环结束,线程会被回收。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
//调用run方法,不直接启动线程
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
队列方法workQueue.take();是一种阻塞的拿取,如果队列为空,这里会被阻塞,防止线程被回收。
有两种情况会导致getTask方法返回null
- 线程已经停止,并且阻塞队列为空
- 满足超时时间,并且线程数目大于核心线程数
在回收线程时,不会区分是否为核心线程,而是会将线程数缩减到等于核心线程数为止。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
//如果线程的运行已经停止,或者队列为空,就减去线程数量,并且返回空值
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
//当超时时间满足,并且线程数目大于核心线程数,就得到需要清除临时线程的true
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
拒绝策略有四种,也可以重写新的策略
- AbortPolicy :直接抛出异常
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
- DiscardOldestPolicy :如果线程尚未结束,就会将阻塞队列里原来的任务丢掉,执行新的任务
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
- CallerRunsPolicy :如果线程尚未结束,执行任务的run方法
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
- DiscardPolicy:不执行
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
4、线程监控
想要实现对线程池的监控,需要自己实现线程池。
继承ThreadPoolExecutor 类,实现构造线程池的方法,可以将beforeExecute执行前方法,afterExecute执行后方法进行重写,在这两个方法内进行线程池内容的监控。
ExecutorsSelf 类似于Executors,可以建立自定义线程池。
public class ThreadPoolSelf extends ThreadPoolExecutor {
public ThreadPoolSelf(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void shutdown() {
super.shutdown();
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
//重写方法
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("初始线程数:"+this.getPoolSize());
System.out.println("核心线程数:"+this.getCorePoolSize());
System.out.println("正在执行的任务数量"+this.getActiveCount());
System.out.println("已经执行的任务数量"+this.getCompletedTaskCount());
System.out.println("任务总数"+this.getTaskCount());
}
}
public class ExecutorsSelf {
public static ExecutorService newThreadPoolSelf(int nThreads) {
return new ThreadPoolSelf(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
}
public class ThreadPool implements Runnable{
public static void main(String[] args) {
ThreadPoolExecutor executorService = (ThreadPoolExecutor)ExecutorsSelf.newThreadPoolSelf(3);
//预热所有核心线程数
executorService.prestartAllCoreThreads();
IntStream.range(1,100).forEach(i-> {
executorService.execute(new ThreadPool());
});
executorService.shutdown();
}
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out