云原生技术分享 | MySQL锁与事务的并发性
Posted 兴兵乐儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生技术分享 | MySQL锁与事务的并发性相关的知识,希望对你有一定的参考价值。
mysql5.7
的存储引擎InnoDB对于只读查询的非常大,几乎不占用任何临界资源,比如锁、日志。若事务多数为优化过的只读查询,单实例吞吐量与CPU性能正相关;若混合读写查询,更新语句常常会导致锁资源竞争,降低数据库并发性能。
本文将介绍常见的数据变更语句DML如何占用锁,了解它们有助于在设计业务查询时,考虑并发情况下事务在执行区间内因等待持有锁而互相阻塞的问题,从而提高MySQL的使用性能。
作者
应用平台部 徐泽龙/文
InnoDB引擎事务隔离级别
InnoDB数据存储结构
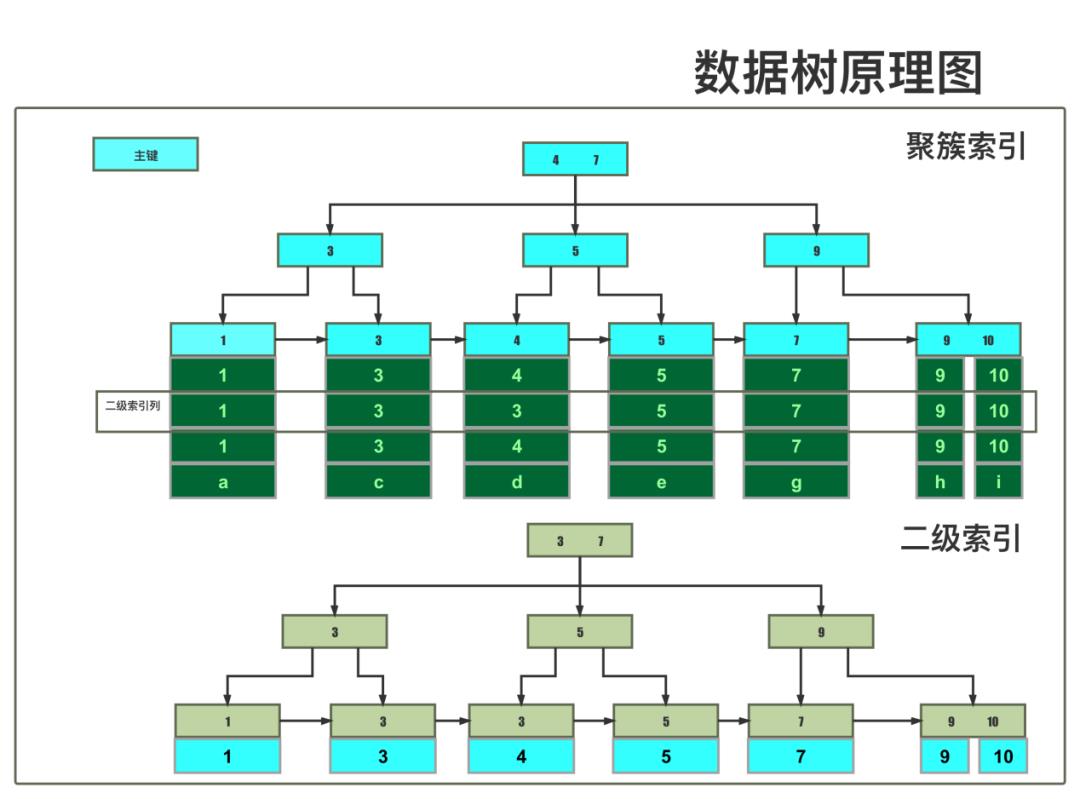
01
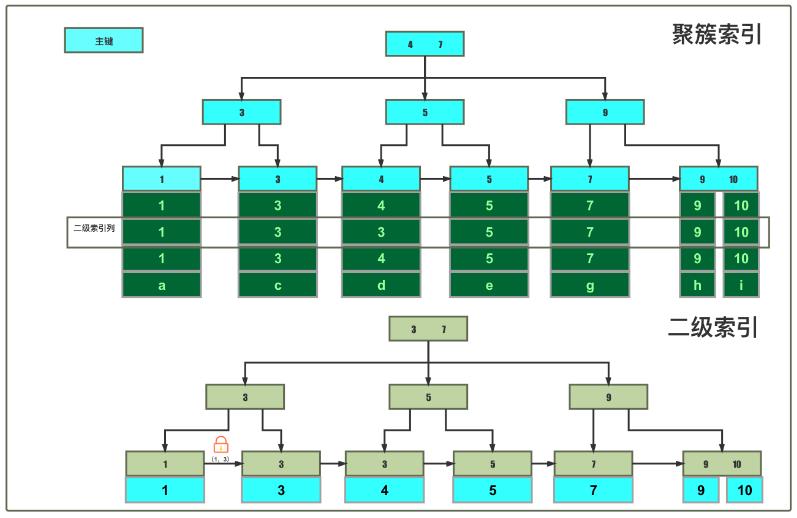
聚簇索引:由(主键、记录)生成的B+树
02
二级索引:由(索引列1、索引列2、...、 主键值)生成的B+树,分唯一约束索引和无约束普通索引
SQL加锁基本原理
01
锁加在索引树叶子数据节点上
02
锁最终落到聚簇索引树叶子上
加锁结构=类型+模式
数据更新语句通过加锁,确保数据一致性,事务在尚未提交时,持有的锁将不会释放,事务根据不同的隔离级别、索引利用等方面在索引树上加不同区间的锁。
#
类型(加锁范围)
· 记录锁(record lock but not gap):索引树上的叶子加锁
· 间隙锁(gap lock):索引树上的叶子区间加锁( a, b )
· next-key锁(record lock):形式为左开右闭( a, b ],在特定情况下退化为记录锁或间隙锁
#
模式(加锁属性)
· 读锁:S
· 写锁:X
以更新查询为例,锁模式为X
一、RR隔离级别
精确查询加锁规则
搜寻索引树使用next-key加锁算法,若具有唯一约束,命中结果退化为使用记录锁,未命中退化为在叶子区间加间隙锁。
· begin;update test_lock set random_col = 'c_new' where id = 3;聚簇索引命中
聚簇索引树记录锁(id=3)
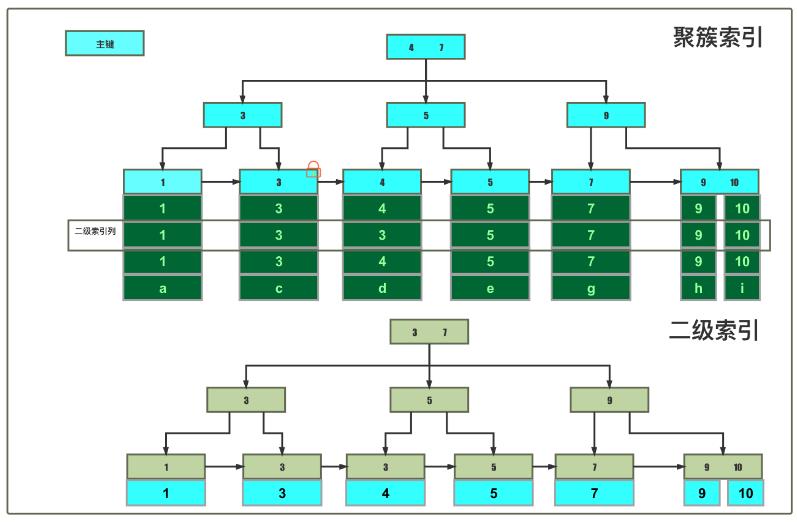
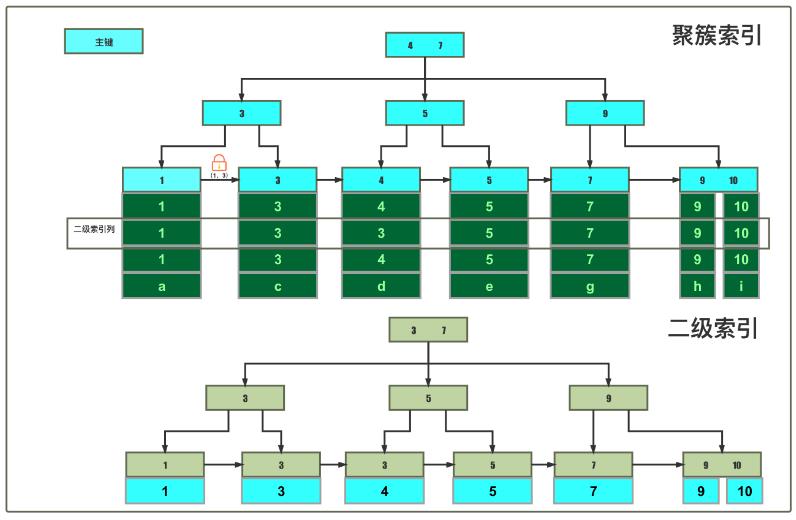
· begin;update test_lock set random_col = 'b_new' where id = 2;聚簇索引未命中
聚簇索引树间隙锁(1, 3)
· begin;update test_lock set random_col = 'c_new' where unique_col = 3;唯一索引命中
聚簇索引树记录锁(id=3)+唯一索引树记录锁(unique_col=3)
· begin;update test_lock set random_col = 'b_new' where unique_col = 2;唯一索引未命中
唯一索引树间隙锁(1, 3)
范围查询加锁规则
搜寻索引树使用next-key加锁算法,命中结果默认使用记录锁和间隙锁( a,b ],未命中退化为在叶子区间加间隙锁。
注:MySQL8.0.18以前的版本中,在RR可重复读级别下,索引上的范围查询,需要访问到不满足条件的第一个值为止。
· begin;update test_lock set random_col = 'cd_new' where nonunique_col = 3; 普通索引命中
普通索引树next-key锁( 1, 3 ],( 3, 3 ],( 3, 5 )+聚簇索引树记录锁(id=3,4)
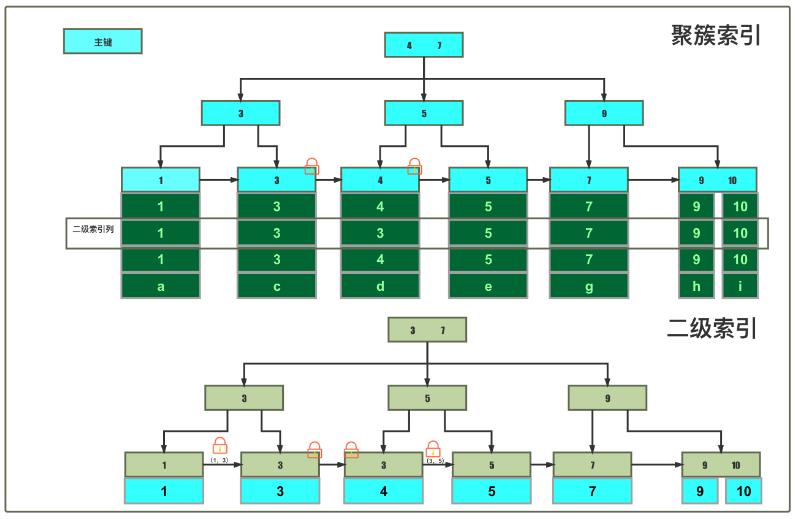
· begin;update test_lock set random_col = 'b_new' where nonunique_col = 2; 普通索引未命中
普通索引树next-key退化为间隙锁( 1, 3 ),注:仅在二级索引树上加锁表示,只有当索引列插入到被锁住区间时才会发生阻塞。
· begin;update test_lock set random_col = 'all4' where id < 5; 主键范围查询
聚簇索引树next-key锁( -∞, 1 ],( 1, 3 ],( 3, 4 ],( 4, 5 ]
· begin;update test_lock set random_col = 'all4' where nonunique_col <= 4; 普通索引范围查询
普通索引树next-key锁( -∞, 1 ],( 1, 3 ],( 3, 3 ],( 3, 5 ]+聚簇索引树记录锁(id=1,3,4,5)
全表遍历加锁规则
从头开始搜寻聚簇索引树,使用next-key加锁算法,在每条记录加( a,b ],无论是否查到结果,等于表锁。
· begin;update test_lock set random_col = 'all4' where normal_col = 4;非索引条件查询
全表锁=聚簇索引树next-key锁( -∞, 1 ],( 1, 3 ],( 3, 4 ],( 4, 5 ], ( 5, 7 ],( 7, 9 ] ( 9, 10 ],( 10, +∞ ],无论是否命中
· begin;update test_lock set random_col = 'all4' where normal_col = 4 limit 1; 非条件查询加limit
由于limit短路了搜寻范围,所以加锁为聚簇索引树next-key锁( -∞, 1 ],( 1, 3 ],( 3, 4 ]
2、RC隔离级别
加锁规则
遍历各个索引树,在命中的结果上加记录锁,未命中不加锁。
锁监控
当事务内语句获得锁且尚未提交释放时,部分信息将展现在innodb status里,可以用SET GLOBAL innodb_status_output
_locks=ON 开启更详细的监控。
mysql > show eninge innodb statusG;
...
RECORD LOCKS space id 143 page no 6 n bits 384 index PRIMARY of table `dtadb`.`test_lock` trx id 1800698 lock_mode X locks rec but not gap
# 在聚簇索引PRIMARY上加记录锁,模式为写锁
...
RECORD LOCKS space id 143 page no 5 n bits 1272 index idx2 of table `dtadb`.`test_lock` trx id 1800701 lock_mode X locks gap before rec
# 在二级索引idx2上加间隙锁,模式为写锁
...
RECORD LOCKS space id 143 page no 5 n bits 1272 index idx2 of table `dtadb`.`test_lock` trx id 1800701 lock_mode X
# 在二级索引idx2上加next-key锁,模式为写锁
INSERT
插入意向锁模式为X:
情况一:没有锁阻塞,直接插入,且在各个索引树上加上该记录的写锁
情况二:存在间隙锁,阻塞等待
情况三:存在记录则出现duplicate key错误
情况四:insert ... on duplicate key update将在修改的记录加next-key lock
情况五:自增列具有自增特性,互相阻塞保证序列递增
根据锁模式兼容矩阵判断事务阻塞
现在已经知道了事务的加锁情况,在并发下,每个事务中的修改数据语句都可能诱发在索引上加锁。当一个事务持有了索引上的某区间锁,另一个事务期望也拥有该区间内的锁,此时需要根据锁模式的兼容矩阵判断,是否能同时持有两把锁,如果不能,后面的事务将出现阻塞情况。
01
对结果持有读锁的事务不阻塞其他事务期望持有另一个读锁
02
对结果持有间隙锁的事务不阻塞其他事务期望持有另一个间隙锁
判断锁等待情况的指标
mysql> show global status like 'Innodb_row_lock_waits';
#事务等待锁的次数
mysql> show global status like 'Innodb_row_lock_time';
#事务等待持有锁的总时间(毫秒)
mysql> show global status like 'innodb_row_lock_time_max';
#事务最大等待时间(毫秒)
mysql> show global status like 'Innodb_row_lock_time_avg';
#事务平均等待时间(毫秒)
举几个例子
1. RR:索引未命中导致间隙锁
create table t1 (a int primary key ,b int);
insert into t1 values (1,2),(2,3),(3,4),(11,22);
2. RR:查询同一时刻的数据
两张表:账户、账单(实时更新)
想要校对某一时刻的信用上限、账单事项与余额,采用可重复读隔离级别的查询是基于当前的快照,具备时间一致性。
3. RC:加锁过程
RC隔离级别的范围扫描查询时,会在未命中的记录上有个快速加锁解锁的过程,速度极快,但当该类查询并发性提高时,锁的开销大大增加了CPU的负载。
总结
本质上讲,MySQL查询是一个搜索数据树的过程,爬完一棵再爬一棵。从上面各种情况描述,RC隔离级别加的锁远远少于RR,RR在索引未命中或者全表扫描时加间隙锁,锁住的数据多,所以推荐设置默认数据库隔离级别为RC,当特殊需求可重复读时,可以临时设置RR:set session transaction isolation level REPEATABLE READ;以满足使用需求。
建议
1.在业务环境允许的情况下,尽量使用RC事务隔离级别,以减少MySQL占用的锁资源。
2.当制定业务查询语句时,特别是使用RR隔离级别,应结合已经存在的查询,事先做一个具体的加锁范围评估,判断是否存在阻塞影响高并发。
3.合理设计索引,让 InnoDB 在索引键上面加锁的时候尽可能准确,尽可能的缩小锁定范围,从RR级别方面来看,索引值连续性高能减少间隙锁范围。
4.尽量控制事务中语句的数量,减少锁住的资源和时间。
以上是关于云原生技术分享 | MySQL锁与事务的并发性的主要内容,如果未能解决你的问题,请参考以下文章