OpenstackNova-KVM性能调优
Posted rayylee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenstackNova-KVM性能调优相关的知识,希望对你有一定的参考价值。
前言:请勿轻易调优,除非很清楚在干什么
KVM 作为 Nova 的虚拟化 Driver,是真正意义上负责虚拟机生命周期管理虚拟化基础设施,所以,如果清楚 KVM 的某些调优参数和策略,就有可能为 Nova 提供调优的基础和入口。Qemu-KVM 负责虚拟机的 CPU、Memory、存储和网络的虚拟化,所以可从该四个方面进行调优。
1. CPU Tuning
1.1 Cache share tuning
参考: https://libvirt.org/formatdomain.html#cpu-allocation
对于物理 CPU,同一个 core 的 threads 共享 L2 Cache,同一个 socket 的 cores 共享 L3 cache,所以虚拟机的 vcpu 应当尽可能在同一个 core 和 同一个 socket 中,增加 cache 的命中率,从而提高性能。IBM 测试过,合理绑定 vcpu 能给 JVM 来的 16% 的性能提升。
虚拟机 vcpu 尽可能限定在一个 core 或者一个 socket 中。例如:当 vcpu 为 2 时,2 个 vcpu 应限定在同一个 core 中,当 vcpu 大于 2 小于 12 时,应限定在同一个 socket 中。对 Nova 而言,需要搜集 CPU 详细的拓扑信息,并根据虚拟机 vcpu 的信息和绑定策略生成 libvirt 所需要的 xml 文件。
<vcpu placement='static' cpuset='0-5'>4</vcpu> # cpuset 限定 vcpu
1.2 NUMA tuning
参考: https://libvirt.org/formatdomain.html#numa-node-tuning
网易运维团队测试得出:2 个 vcpu 分别绑定到不同 numa 节点的非超线程核上和分配到一对相邻的超线程核上的性能相差有 30%~40%(通过 SPEC CPU2006 工具测试)。可见,同一个虚拟机的 vcpu 需限定在同一个 NUMA 节点,并且分配该 NUMA 节点下的内存给虚拟机,保证虚拟机尽可能访问 local memory 而非 remote memory。对 Nova 而言,可增加配置项,并在 nova/virt/libvirt/config.py 代码中增加该字段。
关于 memory allocation mode: If memory is overcommitted in strict mode and the guest does not have sufficient swap space, the kernel will kill some guest processes to retrieve additonal memory. Red Hat recommends using preferred allocation and specifying a single nodeset (for example, nodeset=’0’) to prevent this situation[1].
<numatune>
<memory mode="preferred" nodeset="0"/>
</numatune>
1.3 IRQ tuning
CPU0 常用于处理中断请求,本身负荷较重。事实上,线上环境 CPU0 完全处理 eth0 的 IRQ,eth1 的 IRQ 完全由另一个 CPU 处理,同时 CPU0 处理着大量的 CAL 类型中断。预留 2 个或者 4 个物理 CPU,这些 CPU 和对应网卡中断做绑定,使得其它 CPU 更好更完整的为云主机所用。对 Nova 而言,在生成 libvirt 所需要的 xml 文件时,需避免写入 cpu0等信息。
2. Disk IO Tuning
2.1 Disk IO cache Tuning
kvm 支持多种虚拟机多种 IO Cache 方式:writeback, none, writethrough 等。
- 性能上: writeback > none > writethrough
- 安全上 writeback < none < writethrough。
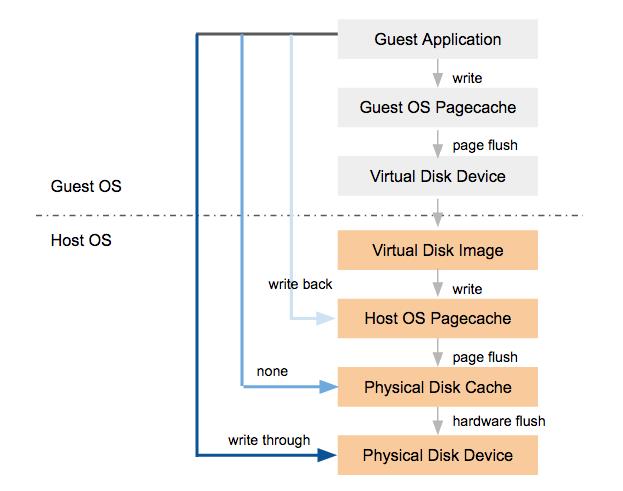
权衡安全性和性能,Kvm 推荐使用 none,Nova 也是默认选用 none cache mode。
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2' cache='none'/> # cache 可为 writeback, none, writethrough,directsync,unsafe 等
...
</disk>
2.2 Disk IO scheduler
Linux kernel 提供了三种 Disk IO 的调度策略,分别为 noop,deadline,cfq。
- noop: noop is often the best choice for memory-backed block devices (e.g. ramdisks) and other non-rotational media (flash) where trying to reschedule I/O is a waste of resources
- deadline: deadline is a lightweight scheduler which tries to put a hard limit on latency
- cfq: cfq tries to maintain system-wide fairness of I/O bandwidth
由于一个宿主机上会运行大量虚拟机,为了防止某个因某个虚拟机频繁的 IO 操作影响其它虚拟机,所以应该选择 cfq 这种公平的调度策略。
2.3 Disk format
KVM 常用 Raw 和 Qcow2 格式作为虚拟机的镜像文件。对虚拟机而言,通俗的说,Raw 格式相当于裸盘,Qcow2 是 copy on write,二者对比如下:
- 性能:Raw > Qcow2
- 节省空间:Qcow2 > Raw
- 安全:Qcow2 > Raw
Qcow2 格式发展到现在,已经有和 Raw 相近的性能,同时能较好的节省空间,所以 Nova 推荐使用 Qcow2 镜像,但是要最大可能的发挥性能,使用 Raw 格式也未尝不可。
3. Memory Tuning
3.1 Disable KSM
参考: https://libvirt.org/formatdomain.html#memory-backing
When KSM merges across nodes on a NUMA host with multiple guest virtual machines, guests and CPUs from more distant nodes can suffer a significant increase of access latency to the merged KSM page. Disable KSM 方式有两种:
- 禁止某个 Guest 与其它 Guest 共享内存,XML 文件可配置为:
<memoryBacking>
<nosharepages/>
</memoryBacking>
- 禁止所有 Guest 直接共享内存,Host 配置为:
echo 0 > /sys/kernel/mm/ksm/pages_shared
echo 0 > /sys/kernel/mm/ksm/pages_sharing
3.2 Open huge page
KVM guests can be deployed with huge page memory support in order to improve performance by increasing CPU cache hits against the Transaction Lookaside Buffer (TLB)。打开透明大页方式有两种:
- 允许某个 Guest 开启透明大页
<memoryBacking>
<hugepages/>
</memoryBacking>
echo 25000 > /pro c/sys/vm/nr_hugepages
mount -t hugetlbfs hugetlbfs /dev/hugepages
service libvirtd restart
- 允许 Host 中所有 Guest 开启透明大页
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo 0 > /sys/kernel/mm/transparent_hugepage/khugepaged/defrag
4. Network IO Tuning
4.1 Enable vhost_net
VhostNet provides better latency (10% less than e1000 on my system) and greater throughput (8x the normal virtio, around 7~8 Gigabits/sec here) for network.
modprobe vhost-net
4.2 Mutil-queue
对虚拟机而言,virtio-net 不能并行的处理网络包,当网络流量很大时,单个 vCPU 有限的处理能力将直接影响虚拟机的网络流量,所以可以通过多队列的 virtio-net 提高虚拟机网络吞吐量,该特性已合入 L 版本。
<devices>
<interface type='network'>
...
<driver name='vhost' txmode='iothread' ioeventfd='on' event_idx='off' queues='N'/> # queues=N
</interface>
</devices>
5. 一次调优的悲剧
Libvirt [CPU host passthrough](https://libvirt.org/formatdomain.html# elementsCPU)支持把宿主机的 CPU 指令集透传给虚拟机,如此虚拟机尽可能的利用宿主机的指令集,从而提升效率。事实上,更改后的短短的三天时间里,有多台宿主机莫名其妙的 kernel panic,虽然未能查明具体原因,但是禁止该配置后,宿主机和虚拟机稳定如初。
Reference
以上是关于OpenstackNova-KVM性能调优的主要内容,如果未能解决你的问题,请参考以下文章