关注了Apache Spark的人同时关注了什么项目?
Posted 架构587
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关注了Apache Spark的人同时关注了什么项目?相关的知识,希望对你有一定的参考价值。
在写了《》文章后, 手上有了处理数据的“锤子”,总想找些“钉子”敲敲。
由于工作需要,我对Apache Spark关注比较多,所以,我想知道的一个问题便是:关注了Spark的人同时还关注了啥项目?是否有些我还不了解的神秘项目?
于是,开始动手~ 目标是清楚了,但是实际用 universe-lite 调用Github API获取数据的过程则是有各种挑战的,但是“办法总比困难多”,在解决了多个问题,并持续爬了几天数据后,终于有了全量数据集(总共1211万5030行数据)。具体遇到的挑战和解决方案将在后续文章中介绍,这里就不说了。
1. Spark的星星数是怎么随时间变化的
-
柱状图代表每月的净增加数,坐标轴为左侧 -
折线图代表累计的总star数,坐标轴为右侧
2. 关注Spark的人同时关注了哪些项目
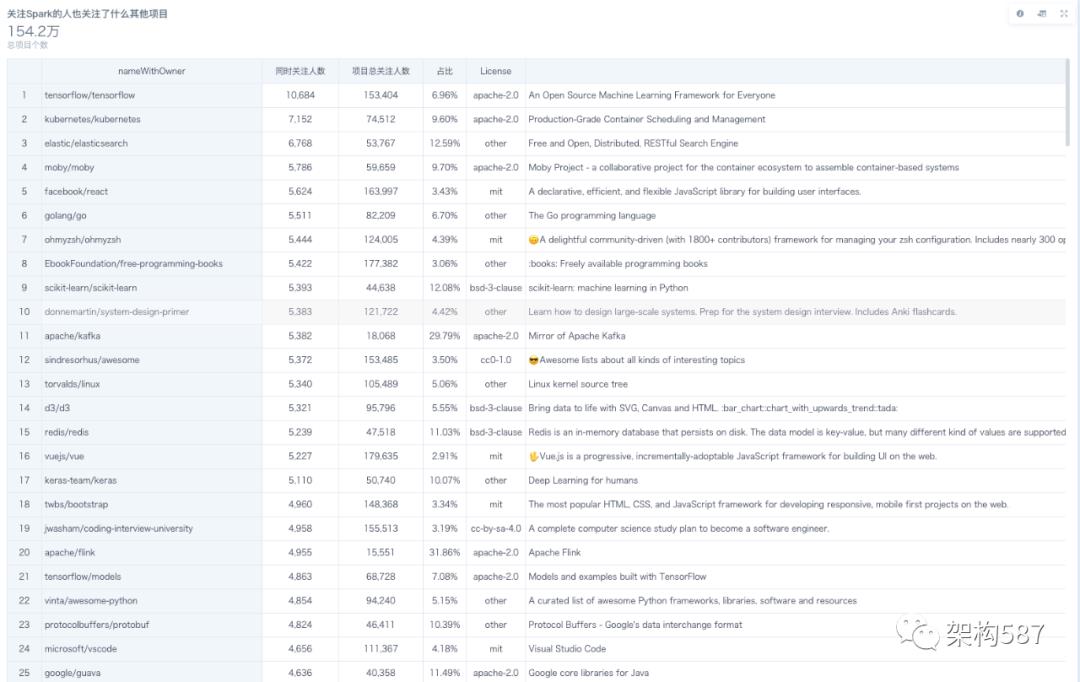
前五名分别是:
-
tensorflow (10684) -
kubernetes (7152) -
elasticsearch (6768) -
moby (5786) (改名前是 docker) -
react (5624)
都是非常成功和流行的开源项目。
3. 关注Spark的人同时都关注了哪些Spark相关项目
上面的图主要都是列出了一些流行的开源项目,但是我更想知道的是那些和Spark紧密相关的项目。
那我怎么才能简单筛选出哪些是Spark相关项目呢。 光靠在“名字”或者“描述”字段搜索是否存在“spark”的效果不太理想。
另一个思路是: 只筛选上图中 “占比”值比较大的项目。这个“占比”高,意味着:关注这些项目的人很高比率关注了Spark,更说明是属于Spark生态。
那我们把 “占比”阈值设置为 20%, 得到如下的项目列表:
前五名分别为:
-
kafka (5382) -
flink (4955) -
hadoop (4473) -
scala (3693) -
akka (3236)
可以说和之前的理解还是比较一致的。
4. 关注Spark的人中,大家都关注了多少个项目
我在Github上目前关注了700+项目,我想知道我在这些用户中,关注的数量到底算是多还是少。那我们来看一下数据
可以看出:
-
关注了10个以下项目的人数有 3634 -
大多数人都只关注了小于1000个项目 -
关注项目最多的人关注了有近5万个项目
结尾
数据是非常有价值的,图表也能够“说话”。未来也会继续为大家带来一些“数据”故事。
以上是关于关注了Apache Spark的人同时关注了什么项目?的主要内容,如果未能解决你的问题,请参考以下文章