环境大数据MapReduce
Posted 一 研 为定
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了环境大数据MapReduce相关的知识,希望对你有一定的参考价值。
目录
一、题目要求

原数据如下:

第一题:月平均气温统计
得到示例结果如下:

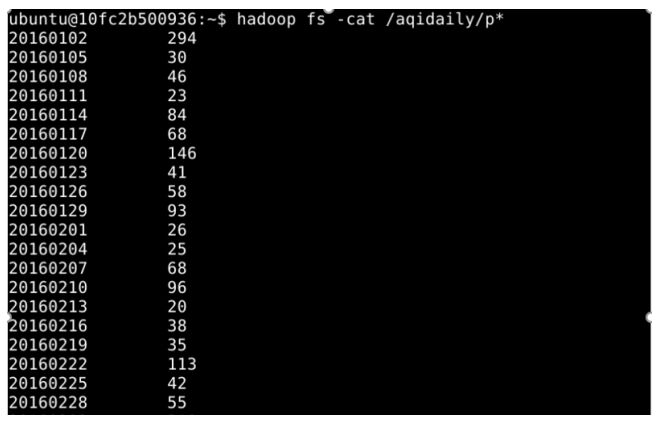
第二题:每日空气质量统计
示例结果如下:
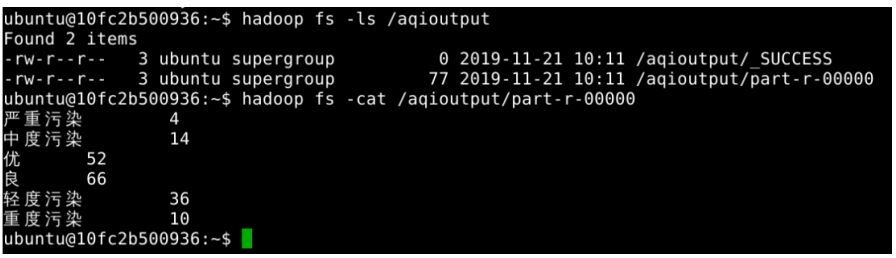
第三题:各空气质量分类天数统计
结果示例如下:
下面我将对这三个问题进行详细解答。
二、问题思路
(一)、月平均气温统计
1、思路
这道题的解题思路是,要求每月的平均气温,但数据给的是每天的气温,所以需要将每天的数据分片,将每日编号(20160101)切片成每月编号(201601),这样再进行对每月的气温取平均值就可以了。
写这道题之前可以先把mapper和reducer里的k,v都想好了,然后再写。mapper里是k1,v1,k2,v2,reducer里是k3,v3,k4,v4。如下:
k1 0行,1行 偏移量 LongWritable
v1 每一行的数据 Text
k2 201601 Text
v2 201601 对应的所有气温 -2,-3,。。。 IntWritable
k3 201601 Text
v3 {-2,-3,-3。。。} IntWritable
k4 201601,201602。。。 Text
v4 avg(每月气温平均值) FloatWritable
avg = total/count
2、代码
配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ST1-weather</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
</project>mapper:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MavgtmpMapper extends Mapper<LongWritable, Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//忽略首行
//用key判断,第一行的key一定是0
if (key.get()==0) {
return;
}
//字符串类型转成java类型
String data = value.toString();
//切片成数组,一共有9个元素
String[] msgs = data.split(",");
//切片,将20160101(精确到日期),变成201601(精确到月)
if (!(msgs[5].equals("N/A"))){
String s1 = msgs[0].substring(0,6);
context.write(new Text(s1),new IntWritable(Integer.parseInt(msgs[5])));
}
}
}
reducer
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MavgtmpReducer extends Reducer<Text, IntWritable,Text, FloatWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//把处理的每一个201601的value值都加起来
int total = 0;
int count = 0;
for (IntWritable v:values){
//把IntWritable类型转化为int型
count++;
total += v.get();
}
float avg = total/count;
//total由int类型变为FloatWritable类型
context.write(key,new FloatWritable(avg));
}
}
main
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MavgtmpMain {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
//程序主类
job.setJarByClass(MavgtmpMain.class);
//Mapper类的相关设置
job.setMapperClass(MavgtmpMapper.class);
//Map输出key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//Reducer类的相关设置
job.setReducerClass(MavgtmpReducer.class);
//程序运行输出key,value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
//设置输入,输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交任务,并等待任务运行完成
job.waitForCompletion(true);
}
}
(二)、每日空气质量统计
1、思路
求每日空气质量统计,由题目可以确定k4是每日编号,v4是每日空气质量AQI,由于每日每时有多个AQI,所以应取平均值。由此可以推出k3是每日编号,v3是每日AQI的集合,那末k2也能确定是每日编号,v2是每日编号对应的AQI。
k1 0行,1行 LongWritable
v1 每一行的数据 Text
k2 20160101 Text
v2 20160101对应的AQI值,即msg[6],212 IntWritable
k3 20160101 Text
v3 {212,209,204,194。。。} IntWritable
k4 20160101,20160102,20160103.。。 Text
v4 avg(每天AQI平均值) IntWritable
avg = total/count
2、代码
mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MavgaqiMapper extends Mapper<LongWritable, Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//忽略首行
//用key判断,第一行的key一定是0
if (key.get()==0) {
return;
}
//字符串类型转成java类型
String data = value.toString();
//切片成数组,一共有9个元素
String[] msgs = data.split(",");
if (!(msgs[6].equals("N/A"))){
context.write(new Text(msgs[0]),new IntWritable(Integer.parseInt(msgs[6])));
}
}
}
reducer
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MavgaqiReducer extends Reducer<Text, IntWritable,Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//把处理的每一个201601的value值都加起来
int total = 0;
int count = 0;
int avg = 0;
for (IntWritable v:values){
//把IntWritable类型转化为int型
count++;
total += v.get();
}
avg = total/count;
//total由int类型变为FloatWritable类型
context.write(key,new IntWritable(avg));
}
}
main
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MavgaqiMain {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
//程序主类
job.setJarByClass(MavgaqiMain.class);
//Mapper类的相关设置
job.setMapperClass(MavgaqiMapper.class);
//Map输出key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//Reducer类的相关设置
job.setReducerClass(MavgaqiReducer.class);
//程序运行输出key,value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入,输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交任务,并等待任务运行完成
job.waitForCompletion(true);
}
}
(三)、各空气质量分类天数统计
1、思路
问题是求解各空气质量分类天数,可知k4是空气质量,v4是天数,可以借助第二题求得的数据,第二题求的数据第一列是天数,第二列是该天的AQI,可以根据AQI的大小评估出该天的空气质量等级,如下图:,并将评估出的等级放入字符串s。即k2为空气质量等级,v2赋值为1;

k1 问题二的 0、1行 LongWritable
v1 每一行的数据 Text
k2 优、良、轻度污染 Text
v2 1 IntWritable
k3 优、良 Text
v3 {1,1,1...} IntWritable
k4 优,良 Text
v4 count求和 IntWritable
读第二个文件,的时候把text类型转发为integer类型,区分不同等级,分类写出来,把数据改成分为类的字符,
2、代码
mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class McountaqiMapper extends Mapper<LongWritable, Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//忽略首行
//用key判断,第一行的key一定是0
//if (key.get()==0) {
// return;
// }
//字符串类型转成java类型
String data = value.toString();
//切片成数组
String[] msgs = data.split("\\t");
//索引下标为1的数值,并赋值给aqi
int aqi = Integer.parseInt(msgs[1]);
//s是字符串
String s = "";
if (aqi<=50){
s = "优";
}
else if (aqi<=100){
s = "良";
}
else if (aqi<=150){
s = "轻度污染";
}
else if (aqi<=200){
s = "中度污染";
}
else if (aqi<=300){
s = "重度污染";
}
else {
s = "严重污染";
}
context.write(new Text(s),new IntWritable(1));
}
}
reducer
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class McountaqiReducer extends Reducer<Text, IntWritable,Text, IntWritable> {
@Override
protected void reduce(Text s, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//把处理的每一个201601的value值都加起来
int daycount = 0;
for (IntWritable v:values) {
//把IntWritable类型转化为int型
daycount += v.get();
}
context.write(s,new IntWritable(daycount));
}
}
main
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class McountaqiMain {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
//程序主类
job.setJarByClass(McountaqiMain.class);
//Mapper类的相关设置
job.setMapperClass(McountaqiMapper.class);
//Map输出key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//Reducer类的相关设置
job.setReducerClass(McountaqiReducer.class);
//程序运行输出key,value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入,输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交任务,并等待任务运行完成
job.waitForCompletion(true);
}
}
题都不难,好好思考就能解出来,加油!!!
以上是关于环境大数据MapReduce的主要内容,如果未能解决你的问题,请参考以下文章