DL4J实战之二:鸢尾花分类
Posted 程序员欣宸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DL4J实战之二:鸢尾花分类相关的知识,希望对你有一定的参考价值。
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 本文是《DL4J》实战的第二篇,前面做好了准备工作,接下来进入正式实战,本篇内容是经典的入门例子:鸢尾花分类
- 下图是一朵鸢尾花,我们可以测量到它的四个特征:花瓣(petal)的宽和高,花萼(sepal)的 宽和高:

- 鸢尾花有三种:Setosa、Versicolor、Virginica
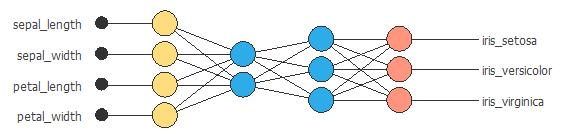
- 今天的实战是用前馈神经网络Feed-Forward Neural Network (FFNN)就行鸢尾花分类的模型训练和评估,在拿到150条鸢尾花的特征和分类结果后,我们先训练出模型,再评估模型的效果:
源码下载
- 本篇实战中的完整源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
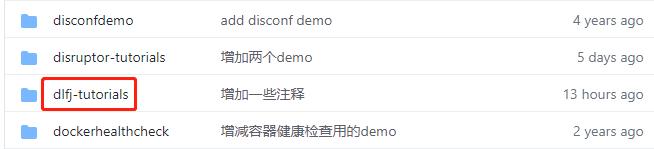
- 这个git项目中有多个文件夹,《DL4J实战》系列的源码在dl4j-tutorials文件夹下,如下图红框所示:
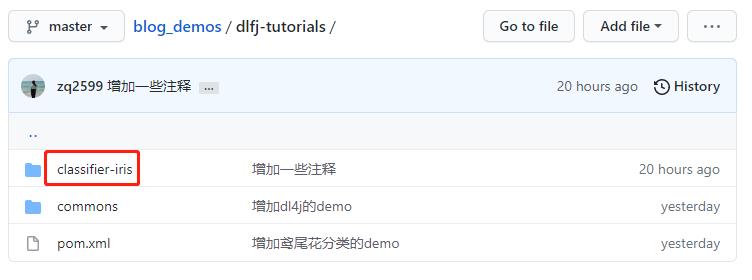
- dl4j-tutorials文件夹下有多个子工程,本次实战代码在dl4j-tutorials目录下,如下图红框:
编码
- 在dl4j-tutorials工程下新建子工程classifier-iris,其pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>dlfj-tutorials</artifactId>
<groupId>com.bolingcavalry</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>classifier-iris</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.bolingcavalry</groupId>
<artifactId>commons</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>${nd4j.backend}</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
</dependencies>
</project>
- 上述pom.xml有一处需要注意的地方,就是${nd4j.backend}参数的值,该值在决定了后端线性代数计算是用CPU还是GPU,本篇为了简化操作选择了CPU(因为个人的显卡不同,代码里无法统一),对应的配置就是nd4j-native;
- 源码全部在Iris.java文件中,并且代码中已添加详细注释,就不再赘述了:
package com.bolingcavalry.classifier;
import com.bolingcavalry.commons.utils.DownloaderUtility;
import lombok.extern.slf4j.Slf4j;
import org.datavec.api.records.reader.RecordReader;
import org.datavec.api.records.reader.impl.csv.CSVRecordReader;
import org.datavec.api.split.FileSplit;
import org.deeplearning4j.datasets.datavec.RecordReaderDataSetIterator;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.SplitTestAndTrain;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.NormalizerStandardize;
import org.nd4j.linalg.learning.config.Sgd;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import java.io.File;
/**
* @author will (zq2599@gmail.com)
* @version 1.0
* @description: 鸢尾花训练
* @date 2021/6/13 17:30
*/
@SuppressWarnings("DuplicatedCode")
@Slf4j
public class Iris {
public static void main(String[] args) throws Exception {
//第一阶段:准备
// 跳过的行数,因为可能是表头
int numLinesToSkip = 0;
// 分隔符
char delimiter = ',';
// CSV读取工具
RecordReader recordReader = new CSVRecordReader(numLinesToSkip,delimiter);
// 下载并解压后,得到文件的位置
String dataPathLocal = DownloaderUtility.IRISDATA.Download();
log.info("鸢尾花数据已下载并解压至 : {}", dataPathLocal);
// 读取下载后的文件
recordReader.initialize(new FileSplit(new File(dataPathLocal,"iris.txt")));
// 每一行的内容大概是这样的:5.1,3.5,1.4,0.2,0
// 一共五个字段,从零开始算的话,标签在第四个字段
int labelIndex = 4;
// 鸢尾花一共分为三类
int numClasses = 3;
// 一共150个样本
int batchSize = 150; //Iris data set: 150 examples total. We are loading all of them into one DataSet (not recommended for large data sets)
// 加载到数据集迭代器中
DataSetIterator iterator = new RecordReaderDataSetIterator(recordReader,batchSize,labelIndex,numClasses);
DataSet allData = iterator.next();
// 洗牌(打乱顺序)
allData.shuffle();
// 设定比例,150个样本中,百分之六十五用于训练
SplitTestAndTrain testAndTrain = allData.splitTestAndTrain(0.65); //Use 65% of data for training
// 训练用的数据集
DataSet trainingData = testAndTrain.getTrain();
// 验证用的数据集
DataSet testData = testAndTrain.getTest();
// 指定归一化器:独立地将每个特征值(和可选的标签值)归一化为0平均值和1的标准差。
DataNormalization normalizer = new NormalizerStandardize();
// 先拟合
normalizer.fit(trainingData);
// 对训练集做归一化
normalizer.transform(trainingData);
// 对测试集做归一化
normalizer.transform(testData);
// 每个鸢尾花有四个特征
final int numInputs = 4;
// 共有三种鸢尾花
int outputNum = 3;
// 随机数种子
long seed = 6;
//第二阶段:训练
log.info("开始配置...");
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(seed)
.activation(Activation.TANH) // 激活函数选用标准的tanh(双曲正切)
.weightInit(WeightInit.XAVIER) // 权重初始化选用XAVIER:均值 0, 方差为 2.0/(fanIn + fanOut)的高斯分布
.updater(new Sgd(0.1)) // 更新器,设置SGD学习速率调度器
.l2(1e-4) // L2正则化配置
.list() // 配置多层网络
.layer(new DenseLayer.Builder().nIn(numInputs).nOut(3) // 隐藏层
.build())
.layer(new DenseLayer.Builder().nIn(3).nOut(3) // 隐藏层
.build())
.layer( new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) // 损失函数:负对数似然
.activation(Activation.SOFTMAX) // 输出层指定激活函数为:SOFTMAX
.nIn(3).nOut(outputNum).build())
.build();
// 模型配置
MultiLayerNetwork model = new MultiLayerNetwork(conf);
// 初始化
model.init();
// 每一百次迭代打印一次分数(损失函数的值)
model.setListeners(new ScoreIterationListener(100));
long startTime = System.currentTimeMillis();
log.info("开始训练");
// 训练
for(int i=0; i<1000; i++ ) {
model.fit(trainingData);
}
log.info("训练完成,耗时[{}]ms", System.currentTimeMillis()-startTime);
// 第三阶段:评估
// 在测试集上评估模型
Evaluation eval = new Evaluation(numClasses);
INDArray output = model.output(testData.getFeatures());
eval.eval(testData.getLabels(), output);
log.info("评估结果如下\\n" + eval.stats());
}
}
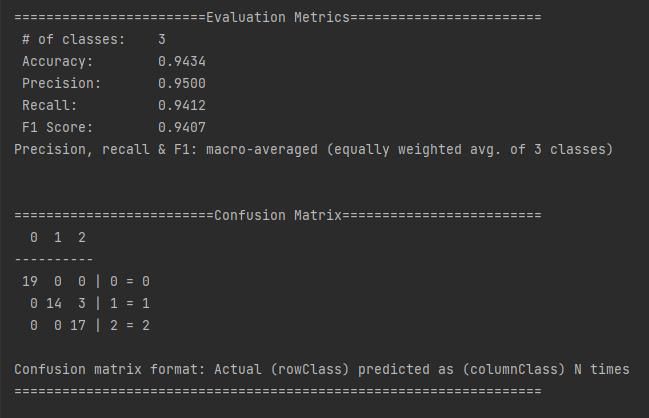
- 编码完成后,运行main方法,可见顺利完成训练并输出了评估结果,还有混淆矩阵用于辅助分析:
- 至此,咱们的第一个实战就完成了,通过经典实例体验的DL4J训练和评估的常规步骤,对重要API也有了初步认识,接下来会继续实战,接触到更多的经典实例;
你不孤单,欣宸原创一路相伴
以上是关于DL4J实战之二:鸢尾花分类的主要内容,如果未能解决你的问题,请参考以下文章