爬虫实战带你一步步破解亚马逊 淘宝 京东的反爬虫机制
Posted LexSaints
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫实战带你一步步破解亚马逊 淘宝 京东的反爬虫机制相关的知识,希望对你有一定的参考价值。
大家好,我是Lex 喜欢欺负超人那个Lex
擅长领域:python开发、网络安全渗透、Windows域控Exchange架构
今日重点:一步步分析and越过亚马逊的反爬虫机制
事情是这样的
亚马逊是全球最大的购物平台
很多商品信息、用户评价等等都是最丰富的。
今天,手把手带大家,越过亚马逊的反爬虫机制
爬取你想要的商品、评论等等有用信息

反爬虫机制
但是,我们想用爬虫来爬取相关的数据信息时
像亚马逊、TBao、JD这些大型的购物商城
他们为了保护自己的数据信息,都是有一套完善的反爬虫机制的
先试试亚马逊的反爬机制
我们用不同的几个python爬虫模块,来一步步试探
最终,成功越过反爬机制。
一、urllib模块
代码如下:
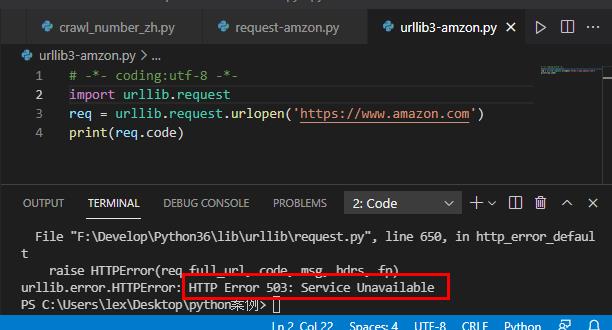
# -*- coding:utf-8 -*-
import urllib.request
req = urllib.request.urlopen('https://www.amazon.com')
print(req.code)返回结果:状态码:503。
分析:亚马逊将你的请求,识别为了爬虫,拒绝提供服务。
本着科学严谨的态度,我们拿万人上的百度试一下。
返回结果:状态码 200
分析:正常访问
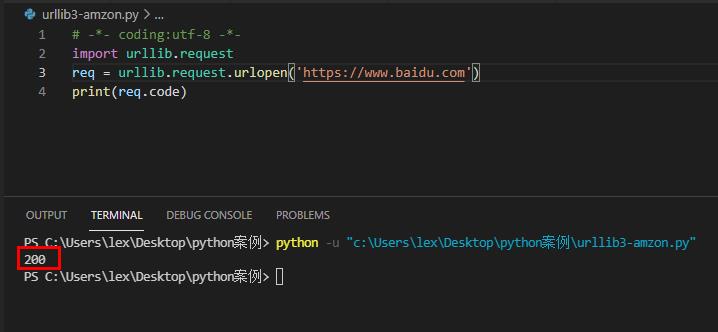
那说明,urllib模块的请求,被亚马逊识别为爬虫,并拒绝提供服务
二、requests模块
1、requests直接爬虫访问
效果如下 ↓ ↓ ↓
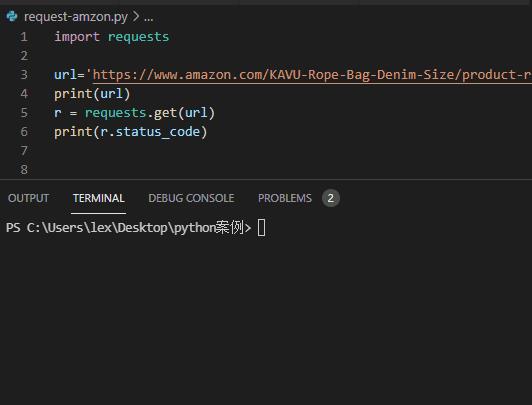
代码如下 ↓ ↓ ↓
import requests
url='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxx'
r = requests.get(url)
print(r.status_code)返回结果:状态码:503。
分析:亚马逊同样拒绝了requsets模块的请求
将其识别为了爬虫,拒绝提供服务。
2、我们给requests加上cookie
加上请求cookie等相关信息
效果如下 ↓ ↓ ↓
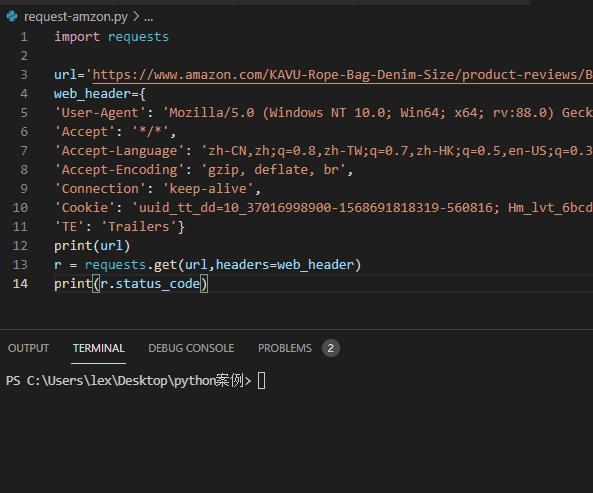
代码如下 ↓ ↓ ↓
import requests
url='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'
web_header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Cookie': '你的cookie值',
'TE': 'Trailers'}
r = requests.get(url,headers=web_header)
print(r.status_code)
返回结果:状态码:200
分析:返回状态码是200了,正常了,有点爬虫那味了。
3、检查返回页面
我们通过requests+cookie的方法,得到的状态码为200
目前至少被亚马逊的服务器正常提供服务了
我们将爬取的页面写入文本中,通过浏览器打开。

我踏马...返回状态是正常了,但返回的是一个反爬虫的验证码页面。
还是 被亚马逊给挡住了。
三、selenium自动化模块
相关selenium模块的安装
pip install selenium代码中引入selenium,并设置相关参数
import os
from requests.api import options
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#selenium配置参数
options = Options()
#配置无头参数,即不打开浏览器
options.add_argument('--headless')
#配置Chrome浏览器的selenium驱动
chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
#将参数设置+浏览器驱动组合
browser = webdriver.Chrome(chromedriver,chrome_options=options)测试访问
url = "https://www.amazon.com"
print(url)
#通过selenium来访问亚马逊
browser.get(url)
返回结果:状态码:200
分析:返回状态码是200了,访问状态正常,我们再看看爬到的网页信息。
将网页源码保存到本地
#将爬取到的网页信息,写入到本地文件
fw=open('E:/amzon.html','w',encoding='utf-8')
fw.write(str(browser.page_source))
browser.close()
fw.close()
打开我们爬取的本地文件,查看 ,
我们已经成功越过了反爬虫机制,进入到了Amazon的首页

结局
通过selenium模块,我们可以成功的越过
亚马逊的反爬虫机制。
下一篇:我们继续介绍,如何来爬取亚马逊的数十万商品信息及评论。
【有问题,请留言~~~】
推荐阅读
python实战
【python实战】前女友婚礼,python破解婚礼现场的WIFI,把名称改成了
【python实战】前女友发来加密的 “520快乐.pdf“,我用python破解开之后,却发现
【python实战】昨晚,我用python帮隔壁小姐姐P证件照 自拍,然后发现...
【python实战】女友半夜加班发自拍 python男友用30行代码发现惊天秘密
【python实战】python你TM太皮了——区区30行代码就能记录键盘的一举一动
【python实战】女神相册密码忘记了,我只用Python写了20行代码~~~
pygame系列文章【订阅专栏,获取完整源码】
一起来学pygame吧 游戏开发30例(四)——俄罗斯方块小游戏
CSDN官方学习推荐 ↓ ↓ ↓
CSDN出的Python全栈知识图谱,太强了,推荐给大家!

以上是关于爬虫实战带你一步步破解亚马逊 淘宝 京东的反爬虫机制的主要内容,如果未能解决你的问题,请参考以下文章
手把手教你写电商爬虫-第五课 京东商品评论爬虫 一起来对付反爬虫