突遇mysql 5.7中导致SQL执行结果出错的严重bug
Posted 数据库随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了突遇mysql 5.7中导致SQL执行结果出错的严重bug相关的知识,希望对你有一定的参考价值。
两天前接到研发同学反馈,说是怀疑数据库执行SQL出错了,一个查询sql ,本来应该需要输出1000条结果的,但偶尔只出来一条结果。因为研发同学开始不太相信数据库会出现这样的错误,所以自己在程序端自行研究一段时间,始终没有找出问题的原因,最后向DBA求证是否真的只返回一条结果,然后DBA在数据库端确认这个现象。
案例中出错的sql很简单,就是根据一天的时间范围,将一天内的数据按1000条分批取出,但偶尔这条SQL的执行结果只返回1条记录,但实际上,应该是1000条记录。
这种并非100%复现的bug,而且是导致执行结果错误的bug,让DBA倍感恐惧跟压力。BUG已经出现,我们得尽快弄清楚bug的所有触发条件,以便评估这个bug是否会在我们的生产环境中可能被触发。如果存在触发的风险,则可能需要立即修改应用程序规避这个bug 或者升级数据库。
经过两天的学习跟研究,基本弄清楚这个Bug产生的原因,以及反推出触发条件,然后对bug进行稳定地多种场景复现。
经过跟踪,最终定位导致bug产生的代码段如下图,这是mvcc数据查找的核心函数row_search_mvcc中的一段代码(之前也曾想对这个函数进行仔细的研究,但这段代码逻辑有点复杂,里面的goto 语句到处跳转,看不下去,也弄不明白,这次在bug的压迫下弄明白了)。row_search_mvcc这个函数的整体逻辑还是有点复杂,在这里不打算去介绍,我们的目的是弄清楚bug的触发条件,下面这段代码提供了非常关键的信息。
我们来解析上面这段代码:
page_rec_is_supremum(rec) 用来判断这个行是否是本数据块(页)的最后一行,如果是,进入下面的判断(以前以为数据查找一定是精确到行的,看来不是,至少范围查找会把本页内所有行都查了)。
接下来,end_loop>100, 这个条件也非常重要。也就是说,循环次数少于100,这个bug 也不会触发。
prebuilt->m_mysql_handler->end_range!= NULL 表示范围的右区间不能为空。如果作者不偷懒,在后面会举例说明这个值(右区间)在什么情况下为空,什么情况下不为空。不为空也是触发bug的必要条件,但限定左右两端的范围的查询,大部分情况下都不为空。所以从代码上看,只有大于条件的查询,可能就不会触发这个bug. (作者尚未做实验证实这个结论)
再往里看,因为当前行是superemum,不包含业务数据, 则需要取前一行,来判断查询是否已经越界,越界的话,就可以终止查询了。
offsets = rec_get_offsets(prev_rec, prebuilt->index,
offsets,ULINT_UNDEFINED, &heap);
所以,上面这一行是获取前一行数据的页面内位置点offset,prev_rec为前一行, 然后通过
row_sel_store_mysql_rec 函数将这行数据格式化成row in the MySQL format,保存在变量end_range_cache 中,然后再通过函数row_search_end_range_check 来判断该行是否已经越界,如果越界,则可以终止查询。终止查询的代码为err = DB_RECORD_NOT_FOUND; goto normal_return;
但在跳转到normal_return:之前,会判断fetch_cache 里面是否有记录(补充一下,fetch cache的作用是为了加速获取行而采用的机制),如果有,则prebuilt->n_fetch_cached> 0, 则设置为prebuilt->m_end_range = true;
但prebuilt->m_end_range设置为true 时,同一个会话(更恐怖的是,不同会话也有可能出现,但出现的概率低,这种情况本篇文章不再扩展下去),再对这个表进行范围查询时,如果有超过一条的结果,也只能获取一条结果,bug就是这样产生的。
原因如下:当再一次对这个表执行SQL时,在执行到函数row_search_mvcc时,该函数的最前面的部分,有如下代码:
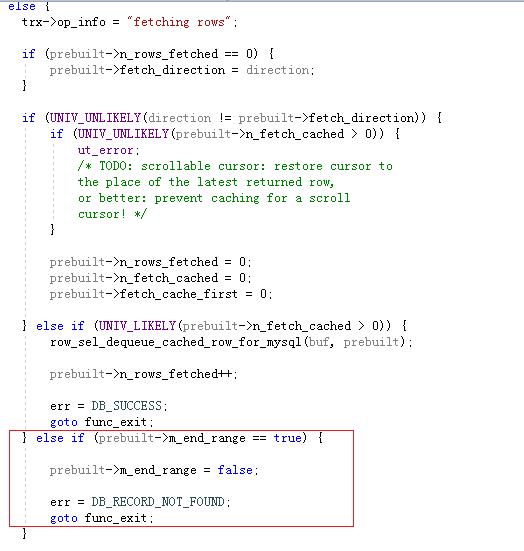
在执行到第二次循环的时候,会命中prebuilt->m_end_range == true 这个条件,然后
设置返回码为DB_RECORD_NOT_FOUND,同时跳转到func_exit代码块,终止了本次sql执行时的数据查找,所以不管这个SQL正确的结果集会有多少条记录,只会返回1条记录。
上面是这个BUG 的源码分析过程, 有个非常重要的关键点,就是end_loop>100, 这个循环次数,
我们简单的理解为查找过程中跳过的行数。下面我们来举例复现这个bug .
表跟数据准备:
创建t2表:
CREATE TABLE `t2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `cid` (`cid`)
)
插入测试数据:
insert into t2 values(1,1);
insert into t2 values(2,2);
insert into t2 values(3,3);
insert into t2 values(4,4);
insert into t2 values(5,5);
insert into t2 values(6,6);
insert into t2 values(7,7);
insert into t2 values(8,8);
insert into t2 values(9,9);
insert into t2 values(10,10);
insert into t2 values(11,11);
insert into t2 values(12,12);
insert into t2 values(13,13);
依次按先后顺序执行如下步骤:
会话1:
Begin;
会话2:
Begin;
然后会话2 插入数据, 插入数据超过100行。
insert into t2 values(14,14);
insert into t2 values(15,15);
insert into t2 values(16,16);
insert into t2 values(17,17);
insert into t2 values(18,18);
insert into t2 values(19,19);
…………………………………………………
…………………………………………………
………………………………………………..
insert into t2 values(124,124);
insert into t2 values(125,125);
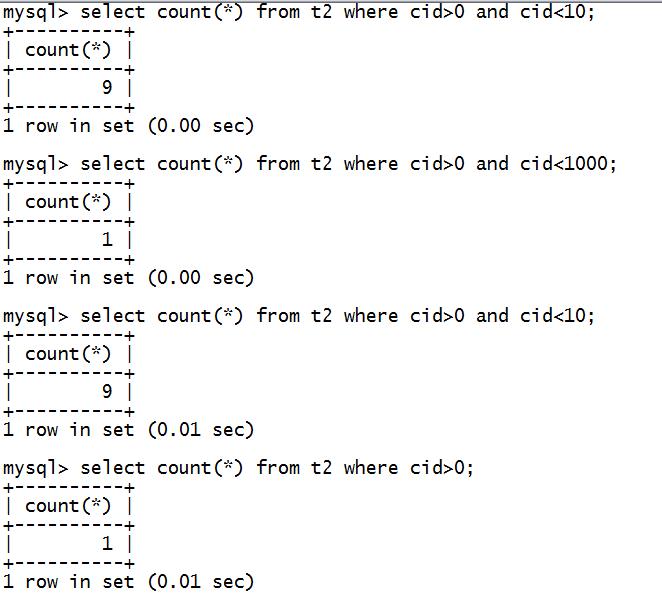
然后会话1执行
select * from t2 where cid>0 andcid<12;
再次执行
select * from t2 where cid>0 andcid<12;
“不可思议的神奇结果出现了”,以下是结果截图:
在这里,将测试案例再扩展一下,请注意观察测试结果是否发生变化。注意,每次测试时只进行一种扩展。
扩展1:如果会话1的sql “select count(*) from t2 where cid>0 and cid<10;”改成
select count(*) from t2 where cid>0and cid<14,现象会发生变化吗?
扩展2:如果会话2的插入数据量少于90行,现象是否会发生变化吗?
这两个扩展测试案例有兴趣的朋友可以自行测试一下,测试完,可以让大家更深入了解上面提到的bug产生的条件。
但是,上述的测试案例中,有insert 操作,而我们研发同事上报的案例,查询结果产生错误的表,曾经只做过delete 操作。于是如法炮制delete 操作案例,希望bug也会复现。
但是,很失望,通过delete 操作,并没有手工复现这个现象,然后一度怀疑,我们遇到的问题可能跟上面的测试案例里的问题不是同一个。
为什么delete 操作导致查询结果出错的案例没有被复现?为什么delete 操作的案例难以复现?猜测原因是:在delete 操作commit 之前,查询语句能从回滚段查到正常结果。事务提交之后,被标记为delete 的行,可能很快就被purge 线程清理,所以不太好手工复现。同时,我们研发同学遇到的情况:是在大并发的delete 情况下,同时进行查询,偶尔遇到只返回1条记录的情况,并非手工测试能触发。
为了验证上面的猜测,决定临时禁用purge线程,但purge线程无法通过参数禁用,所以只能在purge线程的工作函数中加入跳出代码,使purge线程不再实际工作,然后进行测试。
会话1
将数据删除,并进行commit:(注:因为强行禁用了purge线程的功能,数据库在工作一段时间后自动crash,如下图所示)
会话2执行查询,bug出现了。
至此,已经定位了我们研发同事在测试过程中遇到的问题。
以上是关于突遇mysql 5.7中导致SQL执行结果出错的严重bug的主要内容,如果未能解决你的问题,请参考以下文章