基于图数据库的物联网模型-模型的建立和数据导入
Posted 姚家湾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于图数据库的物联网模型-模型的建立和数据导入相关的知识,希望对你有一定的参考价值。
一个优秀的软件会带来一种全新的工作方式。例如CAD 软件solidworks 就带来了一整套三维模型的构建方式,它优点类似于物理零件的制作方法,拉伸,切成,旋转生成和切除。我们在设计3D模型时,心中有一个自己想要的物理模型,然后就像一个工匠或者艺术家那样将这个模型“建造”出来。你需要一些三维模型的想象力和木匠或者钳工的基本技能。正在这种直观的构建方式,我喜欢上了solidworks。
同样地,当我们采纳基于模型设计的方法来构建工业控制,物联网系统时。给使用者一种构建模型的方法。这种方法要易于理解,并且足够有效。这是工具软件成功的关键。自动控制系统 往往相当的复杂,要配置(OT工程师称为组态)的参数非常多。如果用户界面不合理,或者概念,术语很多,流程混乱,使用者会被搞得晕头转向。
另一方面,建立了模型之后,创建实例和数据导入也是一个工程量巨大的事情。比如在制造领域,物料数据就是一个巨量的数据。而在物联网中,涉及到的数据采集点,设备类型以及人员,机构等信息都是巨大的。拿一个学校的物联网系统来举例,其中有上万名学生,几千名教职员工。几千间房屋,电表,灯具,水表,开关,停车场设施等各种设备。其模型数据也是巨量的。构建学校物联网,要对所有的物理对象建模。工程量十分巨大。 工业控制领域的组态工具大多数采用人工操作的方式,建模和数据导入将是系统实施过程中工作量是耗费时间最多的。
在《基于图数据库的物联网模型1》中,我们讨论了基于涂数据库的方式来存储物联网模型。在本文我们研究如何快速建模和导入数据的问题。
模型中节点的几种类型
我们首先分析模型中节点的不同形式,在下一节你将会了解为什么要来研究这种分类,以及由此引出的一些术语。从模型中节点的属性类型来分,节点可以分为两类
- 基本类型
这种类型的节点中包含了基本的属性,没有其它模型类型的属性。例如一个学生节点
student={
"name":"david yao"
"sex":"male"
"age": 21
}具有姓名,性别和年龄。 这个节点没有关联的节点。
- 复合类型
这种类型的节点中除了包含了基本的属性,还包含了其它模型类型的属性。同样以学生为例。如果增加了班级和学生宿舍。那么节点写成:
student={
"name":"david yao"
"sex":"male"
"age": 21
"class":"computer-2017-1"
"room":"build-3-32"
}学生关联了两个节点,分别是班级(计算机系2017级-1班)和宿舍(3栋32室)
我们进一步可以发现,节点关联的节点可以分为两类:
- 子节点
属于节点本身的子节点。比如我们在学生中添加一个联系方式,包括了email 和电话号码。为了提高节点的颗粒度,写成为:
student={
"name":"david yao"
"sex":"male"
"age": 21
"class":"computer-2017-1"
"room":"build-3-32"
"contact":{
"email":"david@163.com"
'mobile":"1310510520"
}
}如何将contact 构建成为一个节点的话,contact 节点是这个student节点的子节点。
- 并行节点
如果与节点关联的节点同时与多个节点建立关系,那么它便是 并行节点 (外部节点)。显然,room和class 是并行节点。
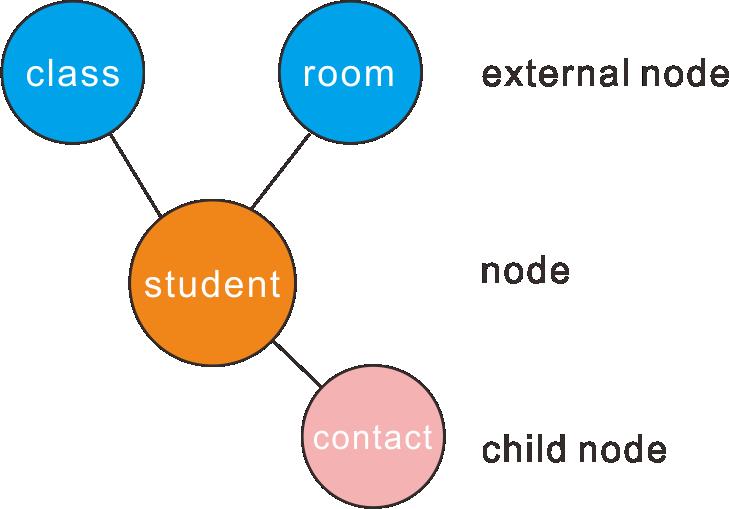
当一个节点引用一个外部节点时,要在模型中定义一个关系。在opc ua 中称为reference 。
OPC UA 中的reference 的语义是节点之间的关系。reference 类型可以理解为类似于C++ 中的指针类型(point) 它指向另外一个节点。
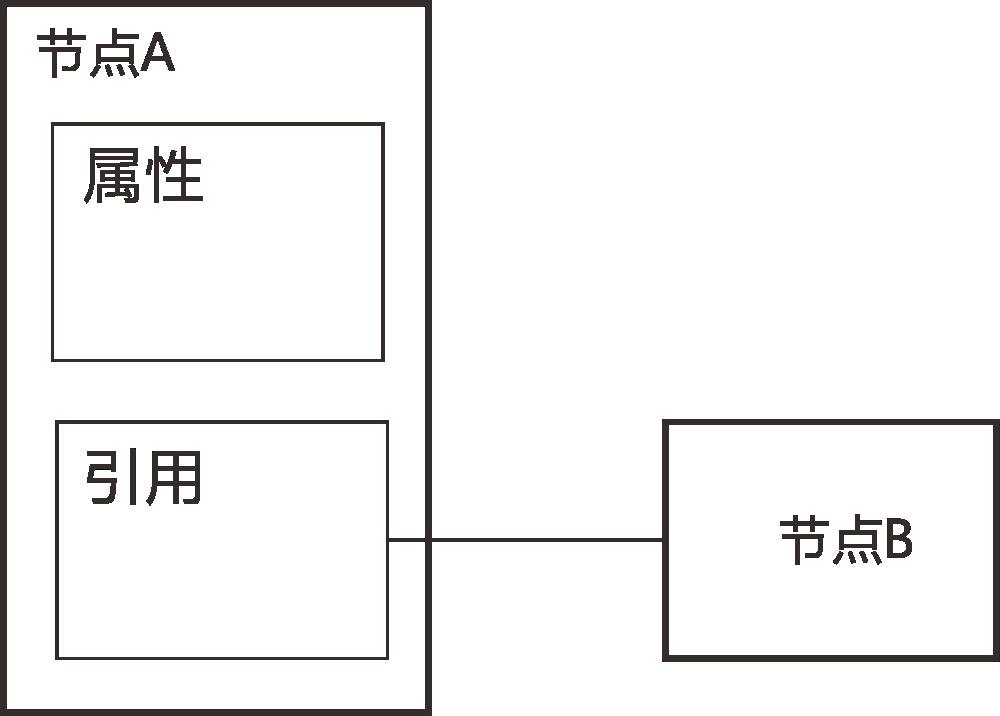
引用是类型的实例化。可以在object 节点中定义一个reference ,其中 target 指向另外一个节点。
其实,子节点和并行节点都需要定义引用,或者关系。只是节点和子节点之间的引用是蕴含的,不一定要在模型中定义,而并行节点的引用需要显式定义出来。
节点类型和实例
在面向对象的信息模型中,首先定义信息模型,然后将信息模型实例化。在数据库中,table 的类型称为”schema“。但是,在数据库技术中,schema 与数据库的table 之间的概念往往是模糊不清的。在mysql 的文档中称”模式和数据库是一回事(a schema is synonymous with a database)".在建立table 的适合就确定了table 的schama。而在mongoDB 中,预先设计了一个schema 然后使用这个schema 去建立和访问数据库。这个shcema 是使用json 来描述的。而数据库内部的数据也是使用json schema 表示的。
定义user模型
const mongoose = require('./db');
const UserSchema = mongoose.Schema({
name: String,
age: Number,
status: { // 默认参数
type: Number,
default: 1,
}
})
module.exports=mongoose.model('User',UserSchema,'user');
使用定义好的模型
const UserModel = require('./model/user');
var user = new UserModel({
name: '李四',
age: 20
});
user.save((err) => {
if (err) {
console.log('保存数据错误')
}
console.log('保存数据成功');
});
而在neo4j数据库中没有schema的概念。建立实例的同时就定义了这个节点的schema 。在OSISoft 的AF framework 中,schema 被称为templates。
由此看来 无论是schema 还是templates都是构建数据库或者访问数据库的时候需要使用的模型,与数据库本身并没有什么关系。
节点的构建和数据导入
那么,在实际的构建过程中十分需要节点的类型?应该使用什么样的方式来定义节点的类型?笔者认为关键是要看创建节点(实例)和导入节点数据的效率而定。
对于具有大量数据的物联网系统而言,如果使用传统控制系统的转台软件来人工地建立节点,并且设置数据效率会非常低。应该考虑采用自动化的方法来自动化产生。事实上许多节点数据来自于其它信息系统的数据库。
在neo4j 图数据库中,CQL 常见导入形式:
|
| CREATE语句 | LOAD CSV语句 | Batch Inserter | Batch Import | Neo4j-import |
|---|---|---|---|---|---|
| 适用场景 | 1 ~ 1w nodes | 1w ~ 10 w nodes | 千万以上 nodes | 千万以上 nodes | 千万以上 nodes |
| 速度 | 很慢 (1000 nodes/s) | 一般 (5000 nodes/s) | 非常快 (数万 nodes/s) | 非常快 (数万 nodes/s) | 非常快 (数万 nodes/s) |
| 优点 | 使用方便,可实时插入。 | 使用方便,可以加载本地/远程CSV;可实时插入。 | 速度相比于前两个,有数量级的提升 | 基于Batch Inserter,可以直接运行编译好的jar包;可以在已存在的数据库中导入数据 | 官方出品,比Batch Import占用更少的资源 |
| 缺点 | 速度慢 | 需要将数据转换成CSV | 需要转成CSV;只能在JAVA中使用;且插入时必须停止neo4j | 需要转成CSV;必须停止neo4j | 需要转成CSV;必须停止neo4j;只能生成新的数据库,而不能在已存在的数据库中插入数据。 |
到入CSV 文件最方便的。我们这里举个简单的例子。
使用EXECL 建立下列表格
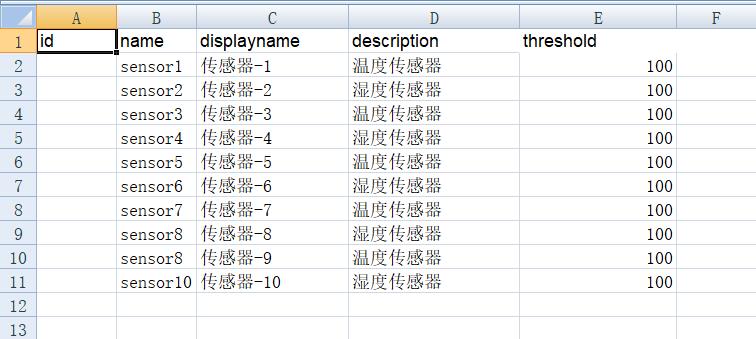
save As csv 格式。然后放置到 neo4j 的import 目录下。在我的电脑中是这个位置:
C:\\Users\\asus\\.Neo4jDesktop\\relate-data\\dbmss\\dbms-e5abcf4d-5377-4437-b757-5446ed7de4c5\\import在neo4j 中输入命令
USING PERIODIC COMMIT 10
LOAD CSV FROM "file:///sensor.csv" AS line
create(a:sensor{name:line[1],displayname:line[2],description:line[3],thredhold:line[4]
})
也可以写成WJTH HEARDERS 方式:
LOAD CSV WITH HEADERS FROM "file:///sensor.csv" AS line
create(a:sensor{name:line.name,displayname:line.displayname,description:line.description,thredhold:line.thredhold
})你可以看到新建的十个sensor的节点。在这里,节点建立和数据装入一次性建好了。
显然这种方式适合前面提到的基本类型。对于复合类型就不适合了。我们需要更为复杂的方式:
- 对于子节点 ,我们可以在建立节点的同时, 建立它的子节点。
LOAD CSV WITH HEADERS FROM "file:///sensor.csv" AS line
create(b:threadhold{name:"threadhold",value:line.threadhold})
create(a:sensor{name:line.name,displayname:line.displayname,description:line.description
})-[:REF]->(b)该CQL 命令建立了一个 sensor 节点,一个子节点,和一个REF 关系。
- 对于外部节点,可以通过不同的CSV 文件来建立节点。
节点模板的重要性
为了更加详细,精确地构建模型, 模型设计工具需要有一个节点的模板(schema 或者 templates),来决定如何构建节点,子节点和关系。
那么采用何种格式的templates 呢。opc ua 的信息模型节点的颗粒度非常高,使用起来比较麻烦,描述的模型过于复杂。让用户直接拿来构建模型难以理解,并且效率低下。我更倾向使用采用更加高级的模型描述方式。 比如json 对象描述方式。
下面我们通过一些实例来进一步探讨使用json的节点模板(templates)。
Templates 的若干实例
水泵模型
{
"pump":{
"name":"string" ,
"displayname":"string" ,
"description":"string",
"motor":"motor" ,
"location":"location"
},
"motor":{
"name":"string" ,
"displayname":"string" ,
"description":"string",
"speed":"int",
"power":"float"
},
"location" :{
"name":"string" ,
"displayname":"string" ,
"description":"string",
"latitude":"float",
" longitude":"float"
}
}使用模板和CSV 文件来建立节点和数据装入
当需要建立pump 节点并装入数据时,首先要选择pump 模型。发现类别有两个属性 motor和location可以认为打勾选择是否自动建立。在csv 文件中要包含motor和location 的属性。
大部分节点都可以使用csv 文件来建立和装入。
结束语
大多数传统的自动控制组态工具都是为有限设备和模型而设计的。大部分工作是通过人工的方式构建的。对于一个大型物联网系统而言,人工方式建立模型实例和装入数据的方式效率低下。需要寻找更为有效的建模和数据装入方法。这是工具软件成功的关键。
以上是关于基于图数据库的物联网模型-模型的建立和数据导入的主要内容,如果未能解决你的问题,请参考以下文章