许嵩音乐智能问答系统微信小程序之获取数据及文本分类
Posted 猫猫头丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了许嵩音乐智能问答系统微信小程序之获取数据及文本分类相关的知识,希望对你有一定的参考价值。
许嵩音乐智能问答系统微信小程序之获取数据及文本分类
数据获取
今天我们正式开始获取数据和对文本进行分类,我的信息都还是从百度百科和网易云上获取的,因为信息量比较少就没有使用爬虫,直接自己手动获取,然后复制在excel里面。
主要获取的信息有
-
个人信息
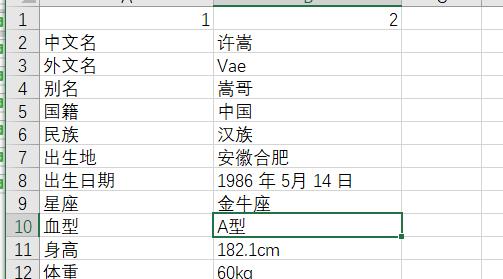
-
演唱会
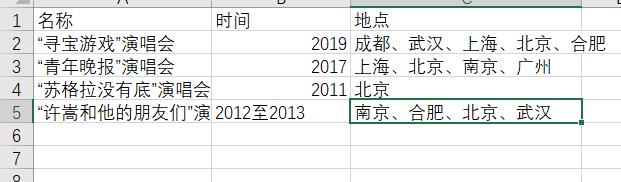
-
专辑
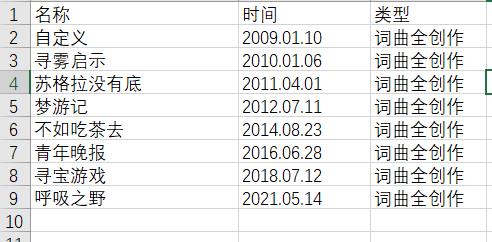
-
为他人创作
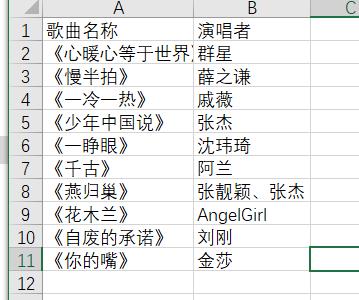
-
歌曲
-
歌曲关键词

-
推荐

文本分类
获取了这些信息以后,我们就先将此次的文本分类任务定为这7大类,接下来我们开始训练分类模型。
首先我们先获取训练好的文本数据集,关于这7大类的询问方式找不到现成的,我就自己写了大概150条,然后给他们分别打上一个标签,如下:
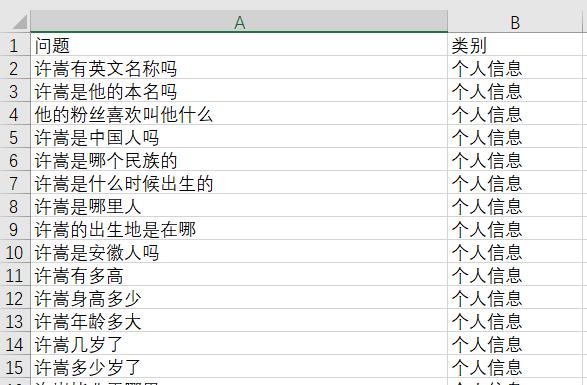 因为时间仓促,感觉这个训练集是有点小的,而且一个人容易思维定型,如果邀请大家一起来想问题应该会更全面一点,这些所有的信息都上传资源了,大家可以下载之后,再加以补充。
因为时间仓促,感觉这个训练集是有点小的,而且一个人容易思维定型,如果邀请大家一起来想问题应该会更全面一点,这些所有的信息都上传资源了,大家可以下载之后,再加以补充。
接下来,正式使用朴素贝叶斯进行训练。
##导入需要的包,读入excel文件
import pandas as pd
import numpy as np
import jieba
import os
import re
import copy
from collections import Counter
import joblib
data = pd.read_excel('问题.xlsx')
x_train=data['问题']
y_train=data['类别']
使用词库表示法进行特征提取,也就是一个字就是一个特征
##文本特征提取(词库表示法)
#sklearn库CountVectorizer转词向量
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(max_features=5000)
vectorizer.fit(x_train_fenci)
# 进行文本转化为特征
x_train = vectorizer.transform(x_train_fenci)
接下来训练模型并保存,保存了模型,下次调用就直接测试出结果,不需要再从头训练开始,非常节省时间。
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
#模型训练
classifier.fit(x_train, y_train)
#将模型持久化,以便以后使用
joblib.dump(classifier, 'clf_model.pkl')
#将词库持久化,以便以后使用
joblib.dump(vectorizer, 'vec_model.pkl')
如果大家的jupyter notebook上面还没有安装joblib,可以安装一下。
!pip install joblib
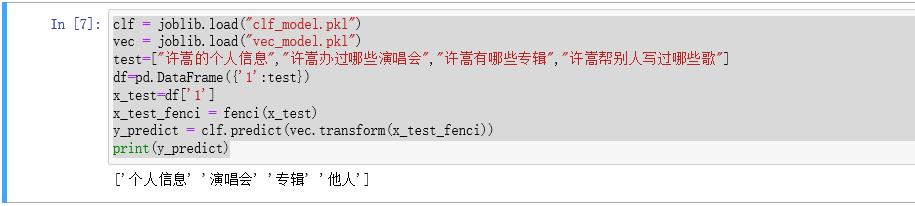
OK,大功告成,我们可以测试一下,看看训练效果如何。
clf = joblib.load("clf_model.pkl")
vec = joblib.load("vec_model.pkl")
test=["许嵩的个人信息","许嵩办过哪些演唱会","许嵩有哪些专辑","许嵩帮别人写过哪些歌"]
df=pd.DataFrame({'1':test})
x_test=df['1']
x_test_fenci = fenci(x_test)
y_predict = clf.predict(vec.transform(x_test_fenci))
print(y_predict)
效果还是非常不错的。
完整的数据集、代码、训练好的模型都已经上传资源啦!
链接: https://download.csdn.net/download/weixin_46570668/19666781.
以上是关于许嵩音乐智能问答系统微信小程序之获取数据及文本分类的主要内容,如果未能解决你的问题,请参考以下文章