Hadoop小练习:女朋友问我,作业重要还是她重要?
Posted 加辣椒了吗?
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop小练习:女朋友问我,作业重要还是她重要?相关的知识,希望对你有一定的参考价值。
前言:
作业来了~~~
某天,我本来在陪女朋友的,看到老师发期末作业了,就跟打了鸡血一样,我一脚把女朋友踢开了,自己从外面跑到宿舍,开始了写作业之旅。女朋友问我,作业重要还是她重要?我犹豫了一会,告诉她:假如百年之后,我的学习通上还出了新的作业,还请在我坟头告知我,吾自当破土而出,认真完成!记住别用混凝土,我怕我拱不出来。如果要对这份热爱加一份期限,我希望是一万年!

文章目录
MapReduce—数据去重多表查询
一、题目
计算机学院要组织各班级打疫苗,现在有两份数据,一份数据包含计算机学院所有的班级,另一份包含计算机学院已经打疫苗的班级,请统计出目前计算机学院还没有打疫苗的班级。
请设计你的输入文件,通过MapReduce完成一次多表关联。
要求:
① 请阐述你的解题思路;
② 提交你的输入文件、输出文件和程序运行截图,以及代码。
思路:
设计2个输入文件(一个是计算机学院所有的班级,一个是计算机学院已经打疫苗的班级),1个java(MapReduct)文件。输入文件作为输入数据,Java文件作为处理数据,将3个文件打包并发送到集群中,在集群中运行。
这就是一个简单的数据去重问题,不同的是,普通的数据去重是将多行重复的数据输成一行,而这个数据去重是将重复的数据全部去掉。
二、解题步骤
1.启动集群
输入jps命令,如下:
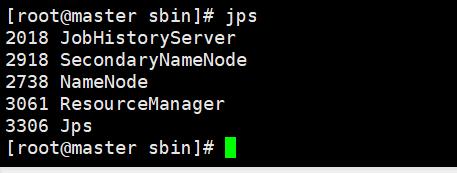
2.设计MapReduce文件和输入文件
处理数据(MapReduce):
数据去重多表查询
package Three;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Data_deduplication {
// map阶段
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text line = new Text();
@Override
protected void map(Object key, Text value,Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
line = value;
context.write(line, new Text(""));
}
}
// reduce阶段
public static class Reduce extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
int count = 0;
for (Text val : values) {
count ++;
}
// 输出没有重复的行
if(count==1) {
context.write(key, new Text(""));
}
}
}
// Driver 程序主类
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:Score Avg");
System.exit(2);
}
Job job = new Job(conf,"Data Deduplication");
job.setJarByClass(Data_deduplication.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
设计计算机学院所有的班级one.txt:

设计计算机学院已经打疫苗的班级two.txt:
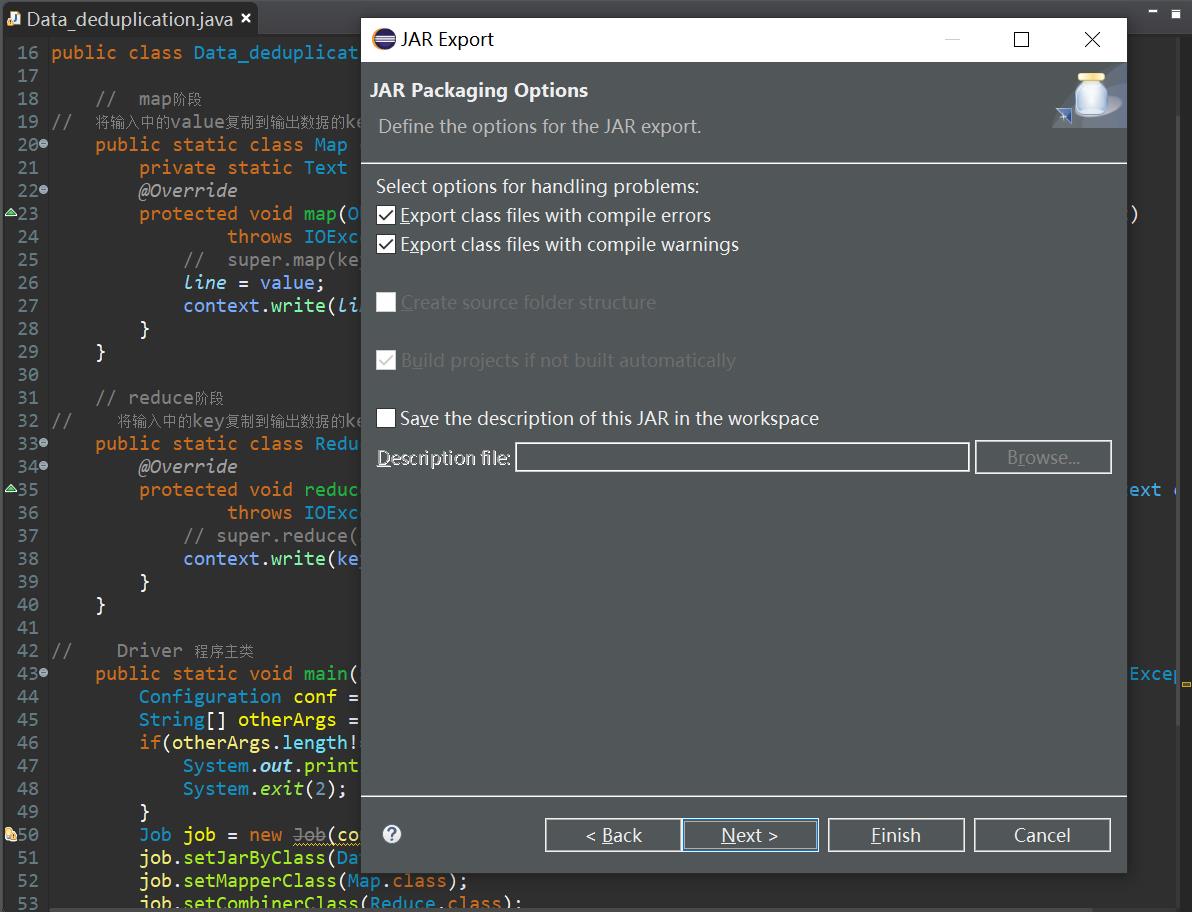
3.将java文件打包为jar包
4.上传jar文件和两个输入文件到centos的opt目录中
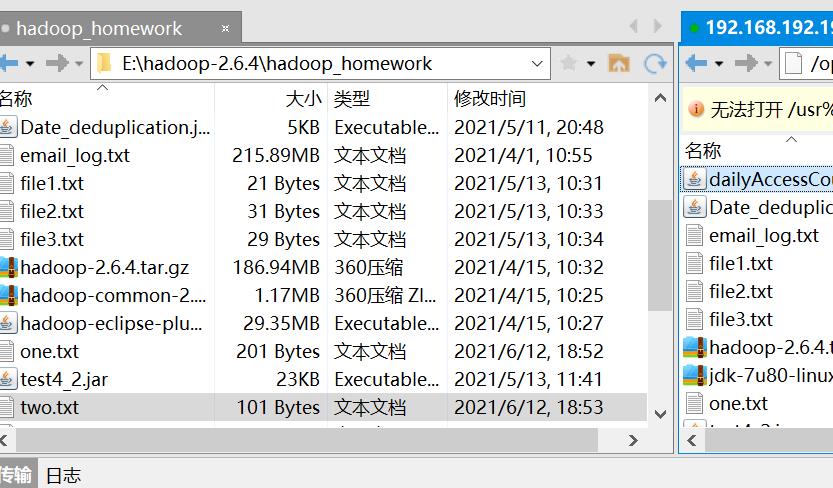
5.在hdfs新建目录output3并移入文件
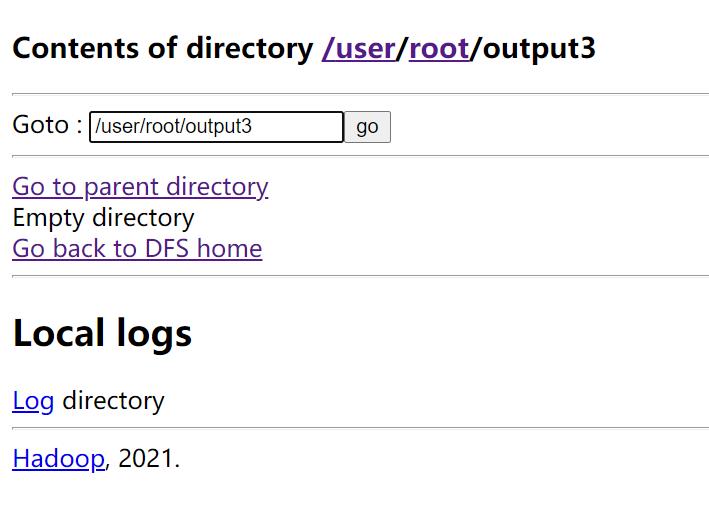
1.新建目录output3
命令:
hadoop fs -mkdir /user/root/output3
output3:存输入文件ont.txt,two.txt:
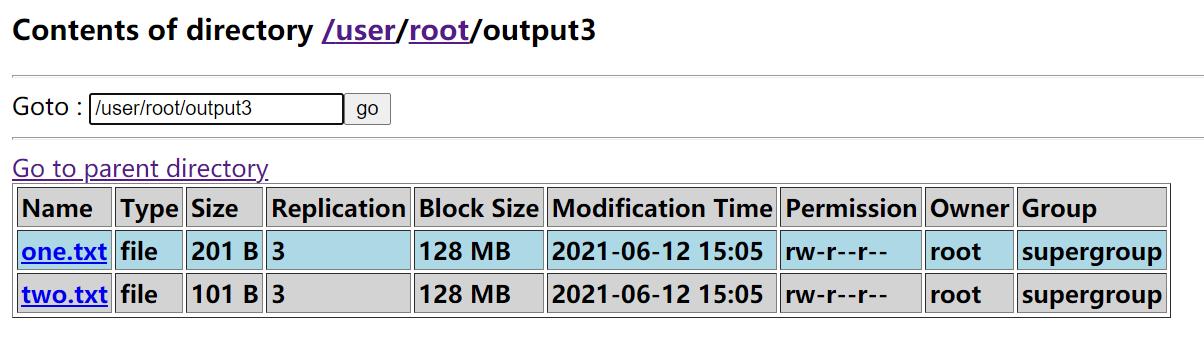
2.移入txt文件
命令:
hadoop fs -put /opt/one.txt /user/root/output3
hadoop fs -put /opt/two.txt /user/root/output3
6.执行
将执行结果输入到out目录:
hadoop jar /opt/Date_deduplication.jar /user/root/output3 /user/root/output3/out
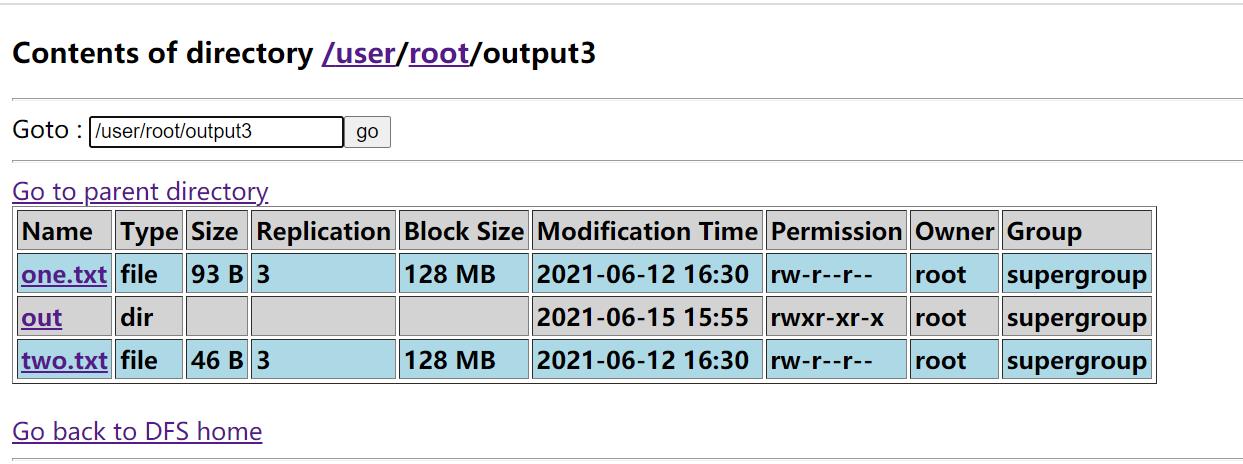
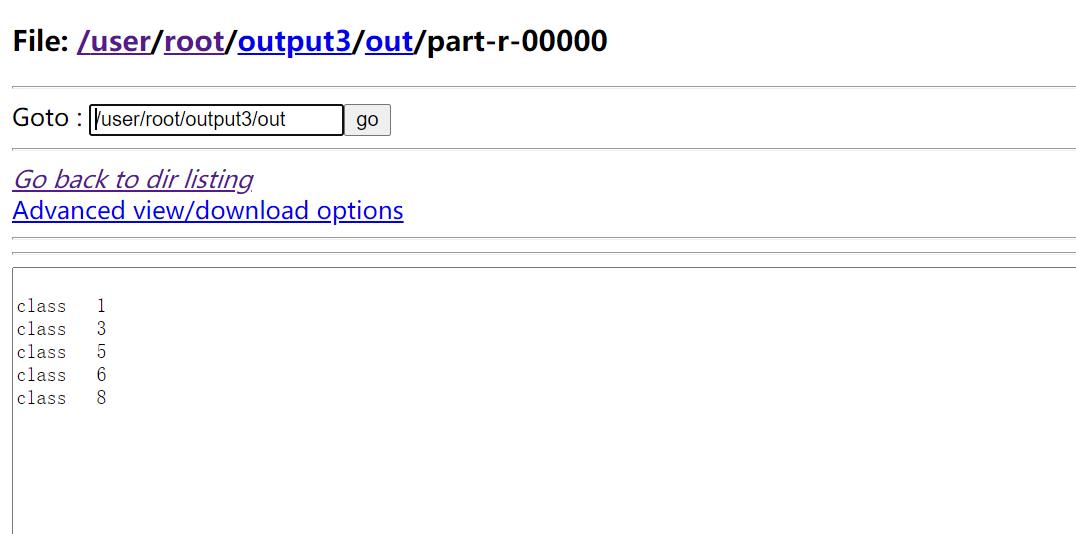
得出没有打疫苗的班级:
结果如下:
合并两个文件,输出结果
总结
题目不难,主要是思路!
适合入门,我把思路,步骤,代码,截图都放出来啦!
求求给个一键3连!!!
@作者:加辣椒了吗?
简介:憨批大学生一枚,喜欢在博客上记录自己的学习心得,也希望能够帮助到你们!

以上是关于Hadoop小练习:女朋友问我,作业重要还是她重要?的主要内容,如果未能解决你的问题,请参考以下文章