使用C++编写一个DHT爬虫,实现从DHT网络爬取BT种子
Posted 彼 方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用C++编写一个DHT爬虫,实现从DHT网络爬取BT种子相关的知识,希望对你有一定的参考价值。
使用C++编写一个DHT爬虫,实现从DHT网络爬取BT种子

1、前言
通过前面两篇文章的科普,相信大家都一定程度上了解了DHT网络和BT种子的相关知识了,不了解也没关系,可以倒回去看下面两篇文章:
虽然前面介绍了很多理论相关的知识,但是光有这些理论是没用的,中看不中用,接下来我们就实战一下,自己编写一个DHT爬虫,达到种子自由的目的,不对,是达到提高我们编程水平的目的。

2、相关术语
2.1、P2P网络
对等计算(Peer to Peer,简称p2p)可以简单定义成通过直接交换来共享计算机资源和服务,而对等计算模型应用层形成的网络通常称为对等网络。相信大家都用过迅雷等p2p软件,这里就不赘述了。
2.2、DHT网络
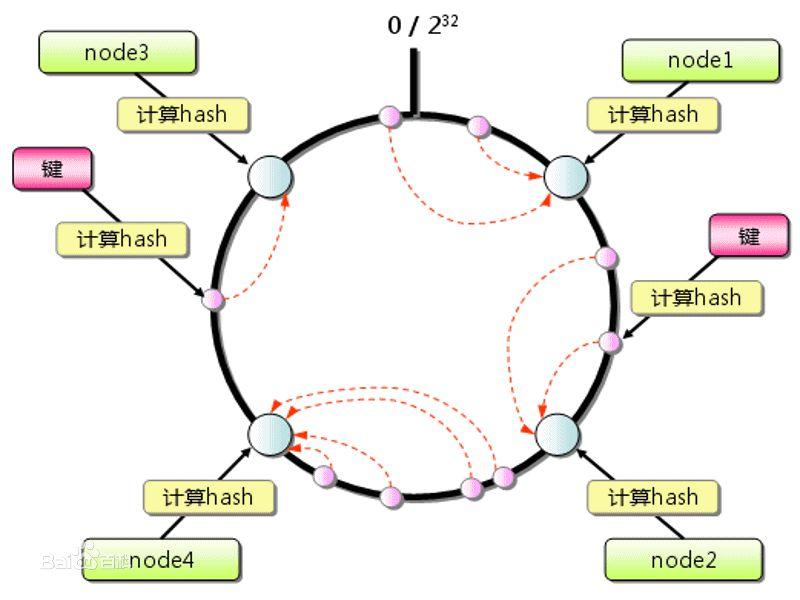
DHT(Distributed Hash Table,分布式哈希表),DHT由节点组成,它存储peer的位置,是一种分布式存储方法。在不需要服务器的情况下,每个客户端负责一个小范围的路由,并负责存储一小部分数据,从而实现整个DHT网络的寻址和存储,其中BT客户端包含一个DHT节点,用来联系DHT中其他节点,从而得到peer的位置,进而通过
BitTorrent协议下载。
简单点来说DHT就是负责管理提供信息和服务节点的管理与路由功能,这里有两个需要区分的概念:
- peer:是在一个 TCP 端口上监听的客户端/服务器,它实现了BitTorrent协议
- 节点:是在一个 UDP 端口上监听的客户端/服务器,它实现了DHT(分布式哈希表) 协议
2.3、Kademlia算法
Kademlia是DHT网络的一种实现。在Kademlia网络中,距离是通过异或(XOR)计算的,结果为无符号整数。distance(A, B) = |A xor B|,数值越小表示越近两个节点越接近,详细说明可以自行百度查阅。
2.4、KRPC协议
KRPC是节点之间的交互协议,是由B编码组成的一个简单的RPC结构,它使用UDP报文发送,一个独立的请求包发出去,然后由另一个独立的包来回复(这也是UDP无连接特性所决定的,所以协议中肯定也会有让我们区分报文包的方法),要注意的是这个协议没有重发机制。
2.5、MagNet协议
MagNet协议,也就是磁力链接。是一个通过sha1算法生成一个20字节长的字符串,P2P客户端使用磁力链接,下载资源的种子文件,然后根据种子文件下载资源。
3、BT下载的一些概念梳理
3.1、BT软件下载原理
BT软件使用
DHT协议,通过击鼓传花的方式,在DHT网络上搜寻磁力链接对应的资源,当找到拥有此资源的peer之后,使用BitTorrent协议先将种子下载下来,然后根据种子文件内容下载对应的资源。
3.2、迅雷获取种子的速度为什么那么快
从理论上来讲,由于BT软件要先去DHT网络搜寻种子,这个过程时需要耗费一定时间的,所以要做到大部分资源都迅速响应是不可能的,迅雷那么快的原因只有一个,就是迅雷自己有种子库,里面缓存了其他用户下载过的种子或者迅雷自己平时在DHT上面爬取的种子。
3.3、资源时效性问题
当DHT网络上持有某一资源的peer全部停止工作后,资源自然也就下不了了,迅雷由于自己有服务器缓存了以往一些热门的资源,所以往往会给人造成资源还在的假象,其实此时是迅雷自己充当服务器给你下发资源而已(这也就是为什么有些资源充了VIP才能下的原因了,毕竟服务器不能让你白用)。
3.4、好用的BT软件
既然BT的原理都是
DHT协议加上BitTorrent协议,所以不同软件下载速度啥的应该差别不大(有服务器缓存支撑的软件除外),比较出名的BT软件有迅雷、uTorrent、qBittorrent、比特彗星、Transmission、aria2等等,大家可以自行去百度去搜索。
3.5、有没有已经编写好的DHT爬虫
答案当然是有的啦,所有BT软件肯定都实现了
DHT协议和BitTorrent协议,可以看一些开源的BT软件里面的实现方法,有个叫做libtorrent的库非常著名,很多BT软件都是将其套个壳做出来的,只不过代码写的比较复杂,看起来有点难受。于是乎就想看看有没有人已经用比较简单的方式实现了DHT爬虫,而通过查阅了很多文章,发现有些人是只实现了DHT协议,然后拿那些通过DHT网络爬取到的hash去开源种子库获取种子,有些就是没有把BitTorrent协议的实现方法开源出来,所以萌生了自己做一个完整的DHT爬虫的想法(开源库无法获取到最新的资源,而且速度肯定是不如直接在DHT网络爬取的)。
4、使用C++编写DHT爬虫
4.1、实现原理
伪装成DHT节点加入DHT网络中收集信息,爬虫主要收集get_peer、announce_peer这两个请求的信息。当收到get_peer或者announce_peer的请求时,直接使用BitTorrent协议从请求发起者下载对应的种子信息(获取不到种子的概率会比较大,原因大家自行完整看一下DHT协议就明白了)
这里有一个疑问,要如何加入DHT网络,通过查看其他大神们的开源代码,我发现基本都是ping下面三个节点来加入DHT网络的
| 域名 | 端口 |
|---|---|
| router.utorrent.com | 6881 |
| router.bittorrent.com | 6881 |
| dht.transmissionbt.com | 6881 |
4.2、实现DHT协议
4.2.1、创建UDP服务
创建一个UDP服务,监听6881端口(DHT默认端口,可以自行修改,理论上啥端口都可以)
4.2.2、加入DHT网络
通过ping上面那几个节点来将自己加入到DHT网络中,这样才能获取到节点的消息,实现如下:
void DhtSearch::ping_root()
{
std::vector<std::pair<const char*, const char*>> ip_addr =
{
{"router.utorrent.com", "6881"},
{"router.bittorrent.com", "6881"},
{"dht.transmissionbt.com", "6881"}
};
for (auto addr : ip_addr)
{
struct addrinfo hints, *info;
memset(&hints, 0, sizeof(hints));
hints.ai_socktype = SOCK_DGRAM;
hints.ai_family = AF_UNSPEC;
int error = getaddrinfo(addr.first, addr.second, &hints, &info);
if (error)
{
log_error << "getaddrinfo fail, error=" << error << ", errstr=" << gai_strerror(error);
}
else
{
struct addrinfo* p = info;
while (p)
{
if (p->ai_family == AF_INET)
{
send_ping((struct sockaddr_in*)p->ai_addr, "");
log_debug << addr.first << ":" << addr.second << " is AF_INET";
}
else
{
log_debug << addr.first << ":" << addr.second << " is no support the family(" << p->ai_family << ")";
}
p = p->ai_next;
}
freeaddrinfo(info);
}
}
}
4.2.3、报文解析
收到其他节点发过来的报文之后,进行报文解析,DHT网络中互相之间通信的格式是B编码,不了解B编码的可以去看这篇文章《B编码与BT种子文件分析,以及模仿json-cpp写一个B编码解析器》,解析报文的代码如下:
// private
int DhtSearch::parse(const char* buf, int len, std::string& tid, std::string& id,
std::string& info_hash, unsigned short& port, std::string& nodes)
{
#define XX(str) \\
log_error << str; \\
return -1
int ret;
BEncode::Value root;
size_t start = 0;
if (BEncode::decode(buf, start, len, &root) || root.getType() != BEncode::Value::BCODE_DICTIONARY)
{
XX("bencode message is invalid");
}
// tid(始终在顶层)
{
auto value = root.find("t");
if (value != root.end())
{
if (value->getType() != BEncode::Value::BCODE_STRING)
{
XX("\\"t\\" value is must be string");
}
tid = value->asString();
}
}
// y(始终在顶层)
auto type_y = root.find("y");
if (type_y != root.end() && type_y->getType() == BEncode::Value::BCODE_STRING)
{
std::string value = type_y->asString();
if (value == "r")
ret = REPLY;
else if (value == "e")
{
XX("remote reply ERROR value");
}
else if (value == "q")
{
auto type_q = root.find("q");
if (type_q != root.end() && type_q->getType() == BEncode::Value::BCODE_STRING)
{
std::string v = type_q->asString();
if (v == "ping")
ret = PING;
else if (v == "find_node")
ret = FIND_NODE;
else if (v == "get_peers")
ret = GET_PEERS;
else if (v == "announce_peer")
ret = ANNOUNCE_PEER;
else if (v == "vote" || v == "sample_infohashes")
return -1;
else
{
XX("\\"q\\" value(" + v + ") is invaild");
}
}
else
{
XX("not found \\"q\\" value");
}
}
else
{
XX("\\"y\\" value(" + value + ") is invaild");
}
}
else
{
XX("not found \\"y\\" value");
}
BEncode::Value::iterator body_value;
if (ret == REPLY)
{
body_value = root.find("r");
if (body_value == root.end() || body_value->getType() != BEncode::Value::BCODE_DICTIONARY)
{
XX("not found \\"r\\" value");
}
}
else
{
body_value = root.find("a");
if (body_value == root.end() || body_value->getType() != BEncode::Value::BCODE_DICTIONARY)
{
XX("not found \\"a\\" value");
}
}
// id
{
auto value = body_value->find("id");
if (value != body_value->end())
{
if (value->getType() != BEncode::Value::BCODE_STRING)
{
XX("\\"id\\" value is must be string");
}
id = value->asString();
if (id.size() != 20)
id.clear();
}
else
id.clear();
}
// info_hash
{
auto value = body_value->find("info_hash");
if (value != body_value->end())
{
if (value->getType() != BEncode::Value::BCODE_STRING)
{
XX("\\"info_hash\\" value is must be string");
}
info_hash = value->asString();
if (info_hash.size() != 20)
info_hash.clear();
}
else
info_hash.clear();
}
// port
{
auto value = body_value->find("port");
if (value != body_value->end())
{
if (value->getType() != BEncode::Value::BCODE_INTEGER)
{
XX("\\"port\\" value is must be int");
}
port = (unsigned short)(value->asInt());
}
else
port = 0;
}
// nodes
{
auto value = body_value->find("nodes");
if (value != body_value->end())
{
if (value->getType() != BEncode::Value::BCODE_STRING)
{
XX("\\"nodes\\" value is must be string");
}
nodes = value->asString();
}
else
nodes.clear();
}
return ret;
#undef XX
}
4.2.4、对不同类型报文进行处理、回复
解析完成后,如果报文有效,则进行后续处理,由于我们的需求只是爬取其他人的种子,自己不进行主动查询,所以并不需要完整实现DHT协议,即不缓存其他节点信息,别人的请求有用的就接受,没用的返回一些假的信息给请求节点,通过这种骗、偷袭的方法可以使得编写出的爬虫的复杂度大大降低,接下来分析各个请求的回应方法(不知道DHT协议的请看这篇文章《DHT协议介绍》,请务必看完,不然接下来的内容很有可能无法看懂)
| 请求类型 | 回复方法 |
|---|---|
| PING | 直接按标准格式回复PONG就行 |
| FIND_NODE | 由于我们并没有缓存其他节点信息,来我们这里查找节点是不可能做到的,所以返回一个空的节点列表给它 |
| GET_PEERS | 这个对于我们是有用的,我们要通过GET_PEERS请求的发起者来下载种子文件,但是由于我们既没有缓存节点,也没有缓存peer,所以回复它一个空列表 |
| ANNOUNCE_PEER | 和GET_PEERS处理方式一样 |
| REPLY | 由于我们始终没有在主动查询任何资源,所以基本不太可能受到回复,收到的话检测报文中有没有nodes,有的话把里面的节点拿出来ping一遍,加入到更多的网络之中 |
4.2.5、隐藏自己,防止被其他节点拉进黑名单
由于整个过程中欺骗其他节点的成分很大,所以每次回复别人错误信息的时候最好修改一下自己的node id,防止被其他节点加入黑名单
4.2.6、获取info_hash和peer
通过获取GET_PEERS或者ANNOUNCE_PEER消息中的info_hash还有对端地址就可以开始使用BitTorrent协议来下载种子信息了(此时将对端节点视为peer,下载失败的概率会挺大,毕竟对端节点也有可能只是在找种子而已,而不是持有种子在下载资源)
4.3、实现BitTorrent协议
要想实现BitTorrent协议,就得先仔细看完下面两篇官方文档
http://www.bittorrent.org/beps/bep_0009.html
http://www.bittorrent.org/beps/bep_0010.html
里面的介绍非常简短,建议全部看完
4.3.1、HandShake(握手)
从bep_0010中可以看到,握手的报文消息格式为:19的ASCII码 + BitTorrent protocol + \\x00\\x00\\x00\\x00\\x00\\x10\\x00\\x04 + infohash的十六进制解码 + 二十字节长的nodeid,infohash是种子的hash,nodeid就是我们自己的id了,需要注意的是BitTorrent协议除了握手消息之外的其他所有的消息的开头四个字节是消息长度(不包含长度域),对端收到消息之后,会给你返回一个至少68字节的回复信息(为什么是至少,下面扩展握手那里会讲),至于如何判断对端是接受了我们的握手呢,判断返回信息的第25位和27位即可(这个是看其他开源代码这样写的,具体原因没去深究,通过测试之后证明确实是这样)
// 握手
std::string handshake_message;
handshake_message.resize(28);
handshake_message[0] = 19;
memcpy(&handshake_message[1], "BitTorrent protocol", 19);
char ext[8];
memset(ext, 0x00, sizeof(ext));
ext[5] = 0x10;
ext[7] = 0x04;
memcpy(&handshake_message[20], ext, 8);
handshake_message += m_info_hash + m_node_id;
m_sock->send(&handshake_message[0], handshake_message.size());
int len = m_sock->recv(buf, BUF_LEN);
if (len < 68)
{
log_debug << COMMON_PART << "(handshake) message size=" << len
<< " is too short(must be >= 68)";
delete buf;
return false;
}
std::string handshake_reply(buf, 68);
std::string ext_message;
if (len > 68)
ext_message = std::string(buf + 68, len - 68);
if (handshake_reply.substr(0, 20) != handshake_message.substr(0, 20))
{
log_debug << COMMON_PART << "(handshake) protocol fail, message:"
<< std::endl << dump(handshake_reply);
delete buf;
return false;
}
if ((int)handshake_reply[25] & 0x10 == 0)
{
log_debug << COMMON_PART << "(handshake) peer does not support extension protocol, message:"
<< std::endl << dump(handshake_reply);
delete buf;
return false;
}
if ((int)handshake_reply[27] & 0x04 == 0)
{
log_debug << COMMON_PART << "(handshake) peer does not support fast protocol, message:"
<< std::endl << dump(handshake_reply);
delete buf;
return false;
}
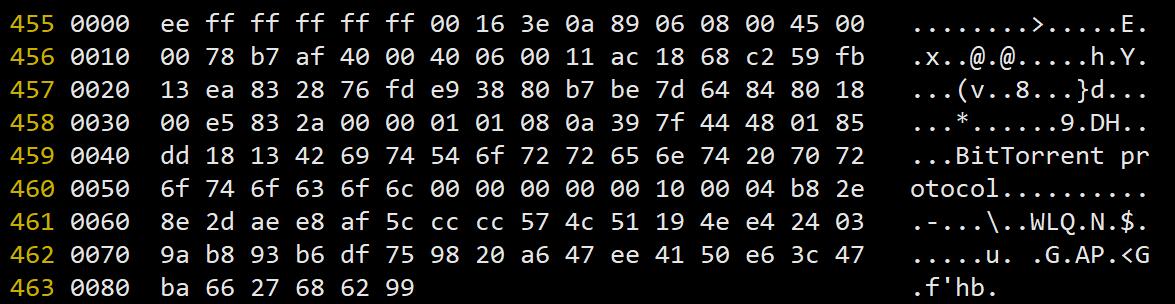
下面是请求报文示例
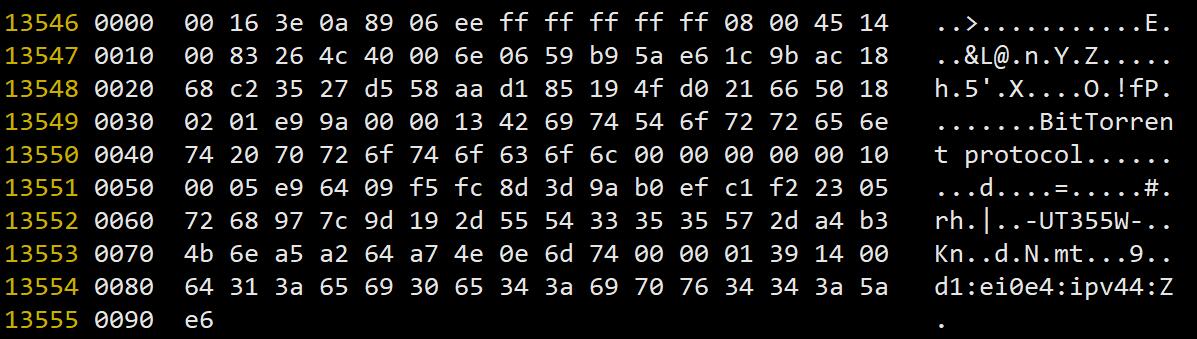
下面是响应报文示例,大家可以自己算一下,从第四行第7个字节0x13开始算起到报文结尾,长度确实是超过了68
4.3.2、Extend HandShake(扩展握手)
从bep_0010中可以看到,握手之后就要进行扩展握手了,而扩展握手是至关重要的,报文消息格式为:消息长度 + MSG_ID的ASCII + EXTEND_ID的ASCII + B编码的字典{‘m’:{‘ut_metadata’:1}}
其中MSG_ID为20,由于是扩展握手,EXTEND_ID是0,完成之后,peer的响应报文里面会包含了两个我们下一步用得到的键值:ut_metadata、和metadata_size,这两个非常重要,拿到之后要找个变量存起来
注意事项:协议中本来是要求握手协议和扩展握手是分开两步进行的,但是在实际测试中发现了很多peer会直接在第一次握手时就把全部数据发过来了,也就是把原本属于扩展握手的消息的应答也一并发过来,而且还有几率发不全。刚开始在写代码的时候,由于不知道这点,导致一直扩展握手失败,差点怀疑智商和码生,到后来通过抓包才了解到这个东西,所以在最终实现时必须这样做,就是第一次握手之后,如果数据量大于68个字节,把多余的内容保存下来,然后进行扩展握手,扩展握手后,把握手剩余的内容和扩展握手的内容一加,就得到正确的扩展握手数据了
代码实现如下:
// 扩展握手
std::string ext_handshake_message;
ext_handshake_message.append(1, 20);
ext_handshake_message.append(1, 0);
ext_handshake_message += "d1:md11:ut_metadatai2ee1:v" + std::to_string(m_v.size()) + ":" + m_v + 以上是关于使用C++编写一个DHT爬虫,实现从DHT网络爬取BT种子的主要内容,如果未能解决你的问题,请参考以下文章