MIT6.814实验1:MapReduce 实现笔记
Posted 守夜人爱吃兔子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MIT6.814实验1:MapReduce 实现笔记相关的知识,希望对你有一定的参考价值。
简介
MapReduce,简称 MR,是 mit6.824 的第一个实验,主要是掌握如何在多物理机分布式的环境下实现大数据的计算,MR 是 Google 三驾马车中的计算引擎。
实验任务为: 实现一个 MapReduce 系统。工作进程(worker)负责调用 map 和 reduce 函数和处理文件读写,协调(coordinator)进程负责给工作进程派发任务并处理工作错误,这里的 coordinator 正是论文中的 Master 进程。
单进程 MR
首先从一个单进程的 MapReduce 入手,看看 MR 是如何工作的。
进入src/main文件,然后编译mrapps/wc.go插件,该插件下有基本的 Map 和 Reduce 函数实现:
cd src/main
go build -race -buildmode=plugin ../mrapps/wc.go编译 wc 插件后,运行 mrsequential.go:
rm mr-out*
go run -race mrsequential.go wc.so pg*.txtmrsequential.go 文件会通过 loadPlugin 函数加载 MR 函数,然后调用它进行 word count,如下:
func loadPlugin(filename string) (func(string, string) []mr.KeyValue, func(string, []string) string)wordcount 结果会写入 mr-out-* 文件,如下:
more mr-out-0
A 509
ABOUT 2
ACT 8
ACTRESS 1
ACTUAL 8
....注意:这里有一个很重要,也是很坑的一个点,无论任何代码发生了更改,wc.so 插件都必须重新编译,否则就会发生插件加载失败。
分布式 MR
在分布式环境下,MR 有两个角色,分别是:coordinator 和 worker。协调者负责协调任务,工作者负责任务处理,工作者可以有多个。在这个实验中,协调者和工作者以进程的方式运行在同一个物理机下,即一个协调进程,多个工作进程。
在真实的系统中,coordinator 和 worker 运行在不同的机器上,但是在本次实验中,它们运行在用一个物理机上。
worker 进程通过 RPC 请求 master 进程获取任务,拿到任务后,根据任务类型,进行 Map 和 Reduce 操作,然后输出到本地文件,如果 worker 进程执行任务超时,如 10s,那么 coodinator 将其任务视为失败,并将这个任务交给其它 worker 进程执行。
分布式 MR 原理
在具体的实现之前,我们来思考一下,分布式 MR 实现的原理,为什么海量数据可以在多个物理机上执行,产生多个结果文件,但是结果却是正确而又有序呢?
这个问题困扰了我很久,以至于我在实现 MR 的时候,功能都实现了,但是结果却一直错误,直到我看了别人实现的 Map 操作,我一下就明白了。
这个问题的关键点在Hash 拆分,将所有 keys 以哈希的方式拆分到不同的物理机上,由于哈希的作用,相同的 key 会被拆分到同一个物理机,因此多个物理机做 Reduce 时,key 是不会混淆的。这种哈希拆分的思想被广泛运行,如 redis cluster。
分布式 MR 实现
实现分布式 MR 整体流程图如下:
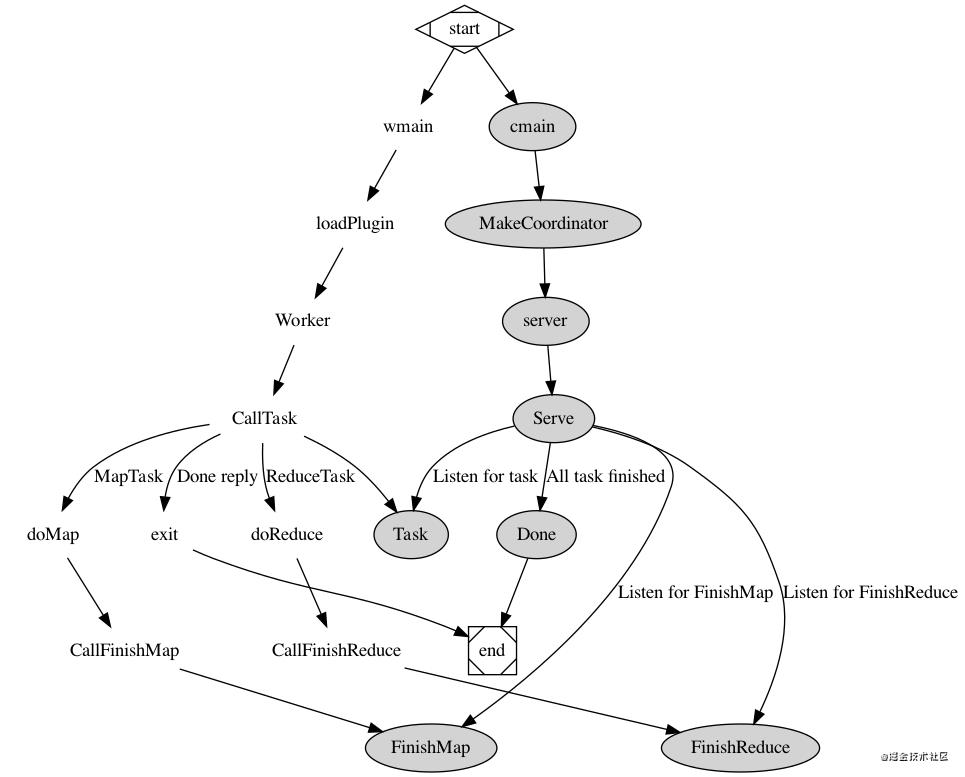
- 首先从 worker 开始,向 coordinator 发送任务请求,然后 coordinator 根据当前任务状态,返回任务,worker 根据任务类型决定调用 Map 还是 Reduce,如果被通知 Done,那么 worker 退出程序。
- coordinator 时刻监控每个 worker 的进程,如果 Map 任务没有完成,则不能进入 Reduce 阶段,待所有 Map、Reduce 任务完毕后,coordinator 检测到 Done 函数返回 true,则程序退出。
Coodinator
type Coordinator struct {
files []string // map 文件
status CoordinatorPhrase // 当前 master 状态,map|reduce|finish
mapTask map[int]*MapTask // map 任务
reduceTask map[int]*ReduceTask // reduce 任务
mapTaskChan chan *MapTask // map 任务通道
reduceTaskChan chan *ReduceTask // reduce 任务通道
nMapComplete int // map 任务完成数
nReduceComplete int // reduce 任务完成数
intermediateFile map[int][]string // 中间文件,map 产生
nReduce int // reduce 个数
r int // reduce 任务序号记录
mu sync.Mutex
}Coordinator 的实现是重点,也是难点。Coordinator 不处理 Map、Reduce 具体任务,而是负责协调这些任务之间的数据以及编排,主要功能如下:
- 记录任务状态,哪些任务未完成,哪些任务待完成,整体状态,处于 Map、Reduce 还是 Finished。
- 派发任务,当 Worker 空闲向 Coordinator 请求时,Coordinator 根据当前任务状态,给 Worker 派发任务。
任务编排与派发必须遵守如下规定:
- Reduce 任务必须在所有 Map 任务完成后才能进行派发,否则必须等待。
- 任务执行是并发的,但是状态信息却只有一份,因此在更改任务状态信息时,必须加锁。
- 如果 worker 执行任务失败,在本实验中,如果任务超过 10s 未完成,则被认为失败,那么该任务将重新派发,交给其他 worker 执行。
下面简单说明一下 Coordinator 中的几个重要字段:
- r:记录下一个 reduce 任务序号,reduce 任务总数为 nReduce
- intermediateFile:map 任务产生的中间文件,文件名格式为 mr-x-y,x 是 map 任务序列号,y 是 reduce 任务序列号。
- nMapComplete:map 任务完成个数
- nReduceComplete:reduce 任务完成个数
- mapTaskChan:map 任务派发通道
- reduceTaskChan:任务派发通道
- status:当前状态,map、reduce 还是 finish
TIPS
在 MR 代码书写过程中,有几个比较重要的技巧。
技巧
如何监控任务超时,实验规定任务 10s 未完成,则视为超时,且重新分发。借用 Ticker 和 select 我们可以如下轻松实现:
func (c *Coordinator) monitorMapTask(task *MapTask) {
t := time.NewTicker(time.Second * 10)
defer t.Stop()
for {
select {
case <-t.C:
c.mu.Lock()
task.Status = Ready
c.mapTaskChan <- task
c.mu.Unlock()
default:
c.mu.Lock()
if task.Status == Complete {
c.mu.Unlock()
return
}
c.mu.Unlock()
}
}
}select 第一个 case 对应超时情况,将 Task 状态重新设置为 Ready,然后加入任务通道;default 情况对应未超时,则不断检查任务状态看其是否完成,如果完成则退出函数。
最后
最近我整理了整套《JAVA核心知识点总结》,说实话 ,作为一名Java程序员,不论你需不需要面试都应该好好看下这份资料。拿到手总是不亏的~我的不少粉丝也因此拿到腾讯字节快手等公司的Offer
进[Java进阶之路群] ,找管理员获取哦-!
以上是关于MIT6.814实验1:MapReduce 实现笔记的主要内容,如果未能解决你的问题,请参考以下文章