家长叫我别天天我在房间没事多看看新闻,我说我马上写个爬虫爬新闻看!!!
Posted CRUD速写大师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了家长叫我别天天我在房间没事多看看新闻,我说我马上写个爬虫爬新闻看!!!相关的知识,希望对你有一定的参考价值。
前言
真的好久好久没写爬虫了,都快忘干净了,简历上写了熟悉爬虫,我总不能跟面试官说我忘记了吧🤣
正好今天抽点空,写个爬虫来回忆回忆。
标题是真的,只不过是没上大学之前家长说的,我记得他们说的以后出去了要学会跟人交流,不能在那大眼瞪小眼,多看看新闻,跟人家还有点话题说说…
其实长时间没写爬虫不是因为不想写,是不知道写什么了,小伙伴们有什么建议写的可以在评论区留下言,我有空有能力就写写,当然,必须是正经的网站(手动狗头)
话不多说,开造!!!
撸起袖子开始看新闻(爬新闻)
先看网页
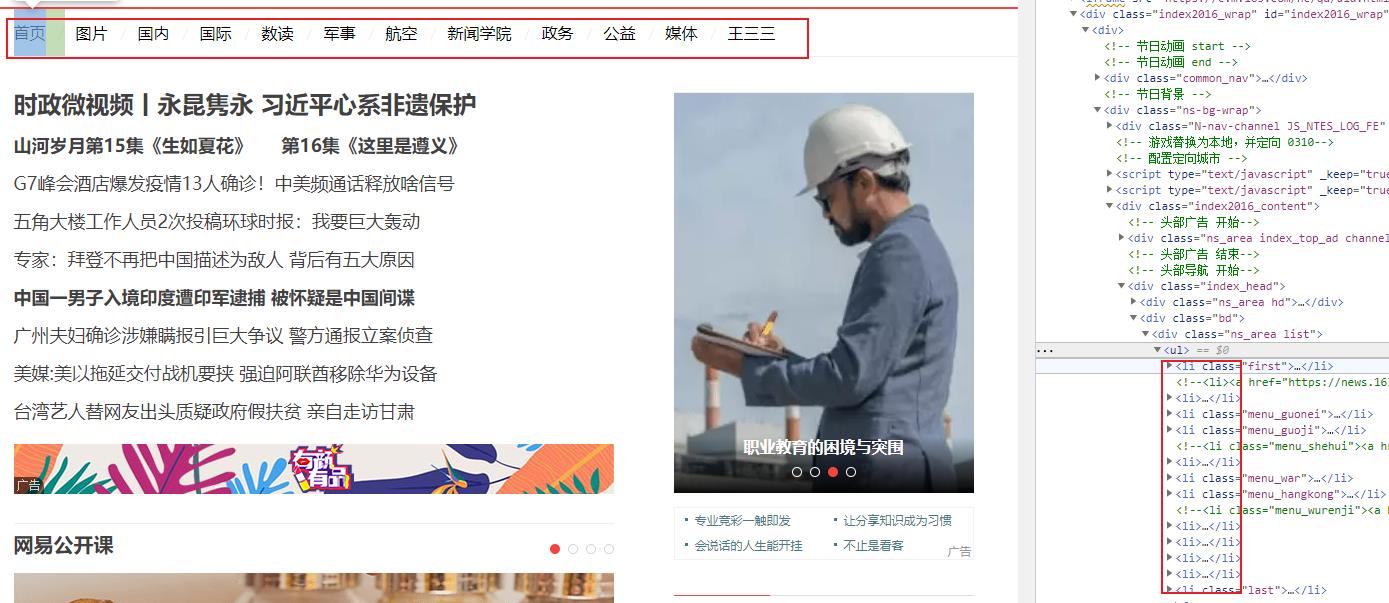
一个个模块对应着一个 li,所以我们拿到 li 的父标签 ul 遍历即可获得所有 li(模块)
插上一句,本片文章适合有基础的小伙伴们看,如果是刚入门的小伙伴可来我的爬虫专栏学习,一步步成为大佬!!!
import requests
from bs4 import BeautifulSoup
import os
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41"
}
url = "https://news.163.com/"
response = requests.get(url=url,headers=headers)
data = BeautifulSoup(response.text,"html.parser")
li_list = data.find(class_="ns_area list").find_all("li")
print(li_list)
这样就拿到了标题和标题详情页的URL
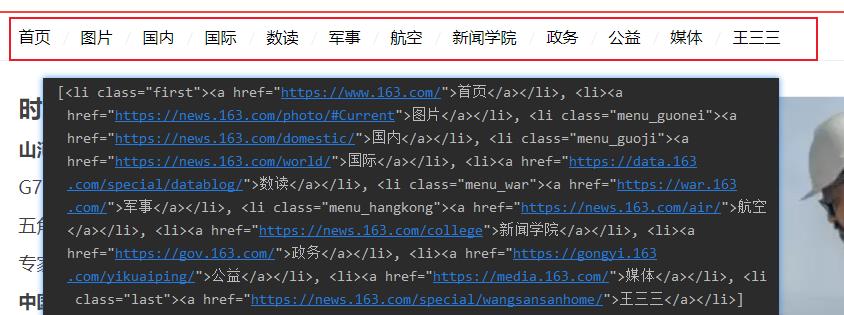
拿到这些模块的URL,那么我们就要去获取这些模块详情页一片片文章的URL了
一篇文章对应一个div,所以我们去获取这些文章的父标签

根据class定位到父标签之后,在获取改标签下的所有div标签即可获得所有文章的div标签
而所有文章div标签下有共同点,那就是在文章div标签下有 <div class= new_title>标签,在这个标签下有a标签存放着文章详情页的URL
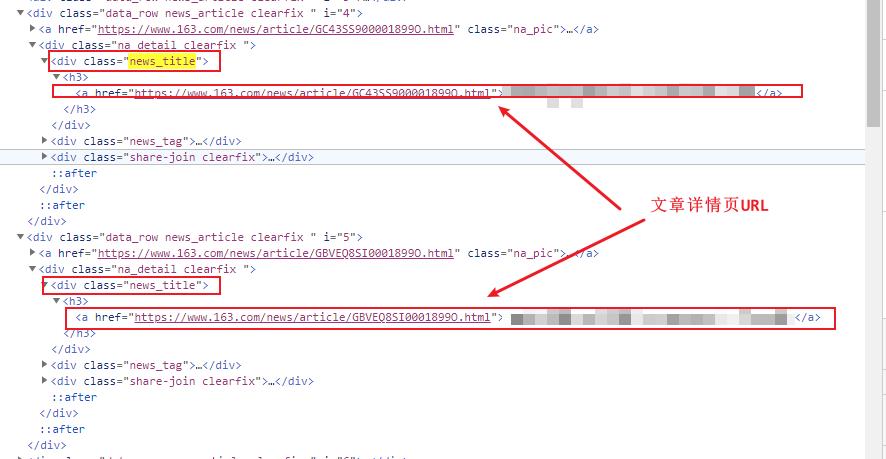
#获取文章标签下所有class为news_title的标签
div_list = model_data.find(class_="ndi_main").find_all(class_="news_title")
for i in div_list:
#获取news_title标签下的a标签的href属性,即文章详情页URL
detail_url = i.find("a")["href"]
parse_detail(detail_url, model_path)
获得到文章详情页URL后,那么就要去文章详情页获取数据了
可见文章内容都在一个class值为post_body的div标签下,而文章的内容也都是在一个个p标签下
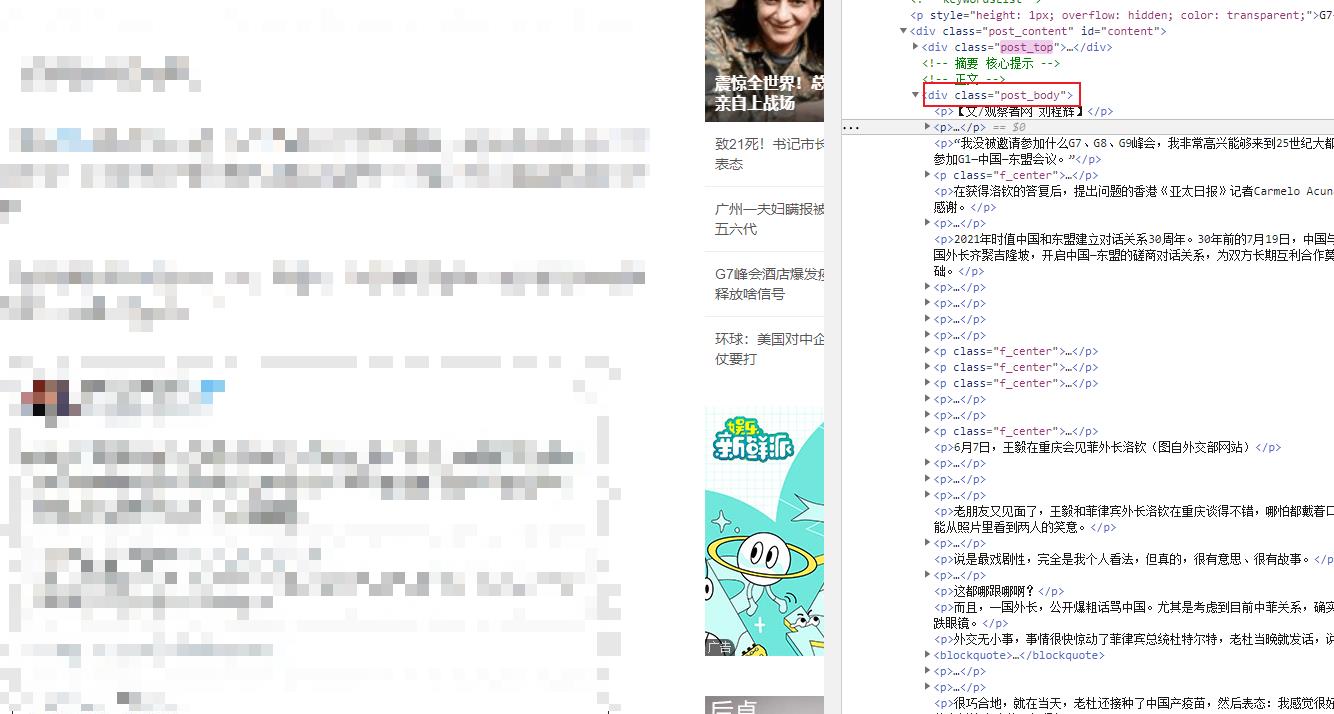
#文章标题
title = detail_data.find(class_="post_title").text
#因为要保存为txt文件所以要把标题有些字符替换掉
title = replaceTitle(title)
#获取所有p标签
body = detail_data.find(class_="post_body").find_all("p")
完整代码
from selenium import webdriver
import time
import os
import requests
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup
path = "./网易新闻"
# 初始化
def init():
# 实现无可视化界面得操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 设置chrome_options=chrome_options即可实现无界面
driver = webdriver.Chrome(chrome_options=chrome_options)
# driver = webdriver.Chrome()
# 把浏览器实现全屏
# driver.maximize_window()
# 返回driver
return driver
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41"
}
# 获取模块URL
def getUrl(driver):
url = "https://news.163.com/"
driver.get(url)
response = driver.page_source
# 目标标题索引
target_list = [2, 3, 5]
data = BeautifulSoup(response, "html.parser")
li_list = data.find(class_="ns_area list").find_all("li")
for index in target_list:
url = li_list[index].find("a")["href"]
title = li_list[index].find("a").text
# 如果模块文件埃及不存在就要创建
if not os.path.exists(path):
os.mkdir(path)
model_path = path + "/" + str(title)
# 如果模块文件不存在就要创建
if not os.path.exists(model_path):
os.mkdir(model_path)
parse_model(driver, url, model_path)
# 获取模块页面URL
def parse_model(driver, url, model_path):
driver.get(url)
model_response = driver.page_source
model_data = BeautifulSoup(model_response, "html.parser")
div_list = model_data.find(class_="ndi_main").find_all("div")
for i in div_list:
if i.find("a") is not None and i.find("a").find("img") is not None:
detail_url = i.find("a")["href"]
parse_detail(detail_url, model_path)
# 爬取详情页
def parse_detail(detail_url, model_path):
detail_response = requests.get(url=detail_url, headers=headers).text
detail_data = BeautifulSoup(detail_response, "html.parser")
if detail_data.find(class_="post_title") is None:
return
#文章标题
title = detail_data.find(class_="post_title").text
title = replaceTitle(title)
body = detail_data.find(class_="post_body").find_all("p")
print("正在保存:" + title)
try:
with open(model_path + "/" + title + ".txt", "w", encoding="utf-8") as f:
for i in body:
f.write(str(i.text.strip()) + "\\n")
f.close()
except:
os.remove(model_path + "/" + title + ".txt")
symbol_list = ["\\\\", "/", "<", ":", "*", "?", "<", ">", "|","\\""]
def replaceTitle(title):
for i in symbol_list:
if title.find(str(i)) != -1:
print(title)
title = title.replace(str(i),"")
return title
if __name__ == '__main__':
driver = init()
getUrl(driver)
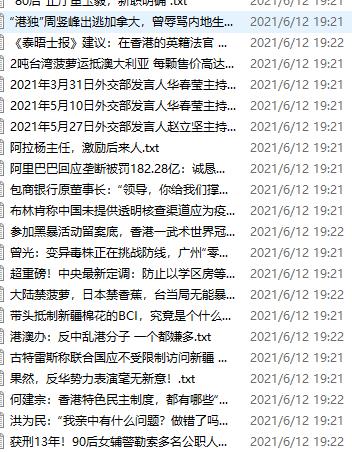
爬取结果(看新闻喽)


CSDN独家福利降临!!!
最近CSDN有个独家出品的活动,也就是下面的《Python的全栈知识图谱》,路线规划的非常详细,尺寸 是870mm x 560mm 小伙伴们可以按照上面的流程进行系统的学习,不要自己随便找本书乱学,要系统的有规律的学习,它的基础才是最扎实的,在我们这行,《基础不牢,地动山摇》尤其明显。
最后,如果有兴趣的小伙伴们可以酌情购买,为未来铺好道路!!!
最后
我是 CRUD大师,一个热爱分享知识的 皮皮虾爱好者,未来的日子里会不断更新出对大家有益的博文,期待大家的关注!!!
创作不易,如果这篇博文对各位有帮助,希望各位小伙伴可以一键三连哦!,感谢支持,我们下次再见~~~
分享大纲
更多精彩内容分享,请点击 Hello World (●’◡’●)
以上是关于家长叫我别天天我在房间没事多看看新闻,我说我马上写个爬虫爬新闻看!!!的主要内容,如果未能解决你的问题,请参考以下文章