每天学一点系列~一文带你彻底弄懂结构体大小和内存对齐
Posted 白龙码~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每天学一点系列~一文带你彻底弄懂结构体大小和内存对齐相关的知识,希望对你有一定的参考价值。

Part I、结构体对齐规则
对齐规则1
要想知道如何计算结构体的大小,必须先了解结构体的对齐规则
结构体对齐规则为:
1、第一个成员在与结构体变量偏移量为0的地址处
假设我们创建了一个结构体:
struct A
{
char a;
int b;
char c;
}A;
并由此创建了一个类型为结构体A的变量:
struct A s;
我们知道,一旦我们创建了一个变量,那么系统就会给它开辟一片空间,这片空间有一个起始地址0X…;
而偏移量的意思,简单来说就是:某两个地址之间的距离,这个距离可以用两个十六进制的地址相减得到。
如0x000004与0x00001的地址偏移量就是3(0x000004-0x00001得到)。
那么这里的第一个对齐规则就很好理解了:由于我们创建的结构体变量具有一个起始地址,那么我们的第一个成员就要从这个地址开始存放,也就是我们所说的:第一个成员在与结构体变量偏移量为0的地址处。
对齐规则2
2、其他成员变量要对齐到某个数(这里指对齐数)的整数倍地址处
注:对齐数=min{编译器默认对齐数,该成员类型的大小}
我们常用的VS编译器的默认对齐数为8,Linux系统下无默认对齐数
了解了默认对齐数的概念后,我们不妨画一个图:
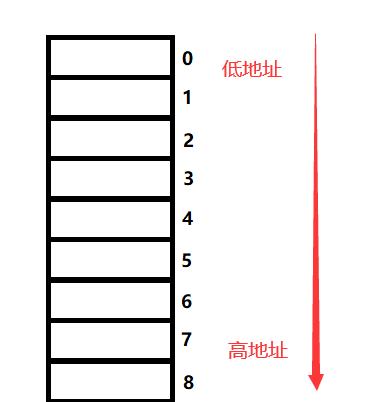
方格表示我们的内存单元,右边的数字表示偏移量(0偏移量处就是我们假定的结构体变量起始地址)
我们这里所说的对齐数,本质上就是与起始地址的偏移量。而对齐数的确定与编译器和成员的类型有关,具体公式:对齐数=min{编译器默认对齐数,该成员类型的大小}
也就是说,我们取成员类型大小和默认对齐数二者的较小值作为对齐数。
这里用一个例题帮助讲解:(为方便讲解,我们选择VS编译器下的默认对齐数)
struct A
{
char a;
int b;
short c;
}A;
通过上述的两个规则我们知道:第一个成员a从偏移量为0处开始存放,即:

而我们的第二个成员b,由于它是int类型,占4个字节,那么取min{sizeof(int),默认对齐数8},于是我们得到:成员b的对齐数为4,那么它就要从偏移量为4的倍数处开始存放:
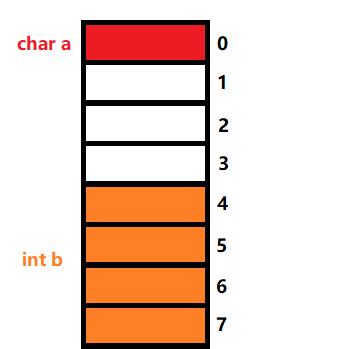
注:这里白色的部分,即偏移量为1~3的地址并不存放结构体成员数据,可以说是浪费掉了,但这是值得的,原因我们后面具体解释。
我们继续分析第三个成员c;
由于它是short类型,那么我们依然取min{sizeof(short),默认对齐数8},由此得到c的对齐数为2,那么它将从偏移量为2的整数倍处往后存放,即:
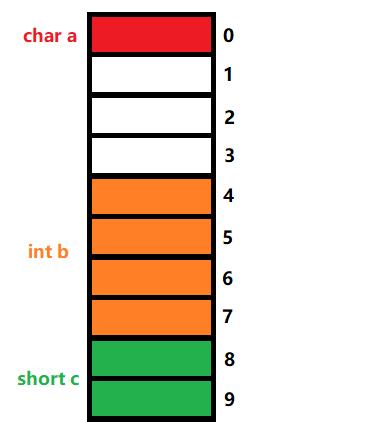
综上我们可以得知:这个结构体的成员总共占了偏移量为0~9的这十个内存单元,那么这是否意味着它的大小为10呢?我们继续看第三个对齐规则——
对齐规则3
3、结构体的总大小为最大对齐数(结构体的每个成员都有一个对齐数)的整数倍
这里又出现了一个新名词:最大对齐数。什么意思呢?由上述的第二条规则和例题我们知道,结构体的每一个成员的类型大小与编译器的默认对齐数比较后,都能得到一个对齐数,而我们需要取这些成员的对齐数中最大的那一个作为我们整个结构体的对齐数,最后我们的结构体大小要是这个结构体对齐数的最小整数倍。
我们接着上一道例题分析——
我们知道,a的对齐数为1,b的对齐数为4,c的对齐数为2,那么我们结构体的对齐数取这三者的最大值,也就是4。由于a,b,c三个成员占了0~9这十个内存单元,所以结构体最终的大小应该是大于等于10且是4的倍数,于是我们得到答案:12。
VS编译器下运行:
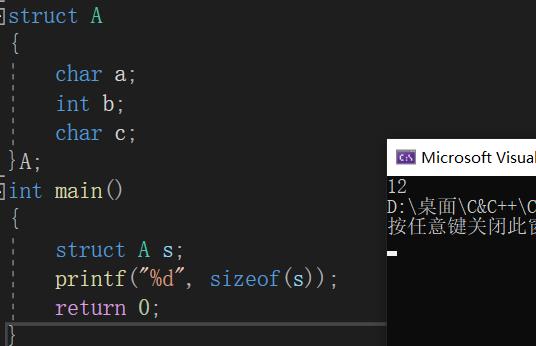
答案正确!
上面我们分析了一类简单的结构体,但是较为复杂的结构体嵌套的情况该怎么解决对齐数的问题呢?对齐规则4为我们解释了——
对齐规则4
4、如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
意思就是说,结构体如果有嵌套,那么我们把他单独地看作一个变量,对于它的最大对齐数的分析方法依据上述的三个对齐法则,那么这个结构体类型成员的大小就是它本身的大小,对齐数就是它本身的最大对齐数。
还是用例题说话:
struct A
{
char a;
int b;
char c;
}A;
struct B
{
int a;
struct A b;
char c;
};
我们算这个结构体B的大小(注意,它的成员中嵌套了一个结构体A)
我们看结构体B的第一个成员a,它直接对齐到0偏移量处:
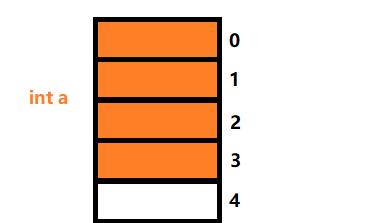
第二个成员b,它的类型为struct A,对齐数为4(4是它自己的最大对齐数),大小为12(这个是我们上面分析过的那个结构体,所以直接列出对齐数与大小),所以它的存放位置就是:
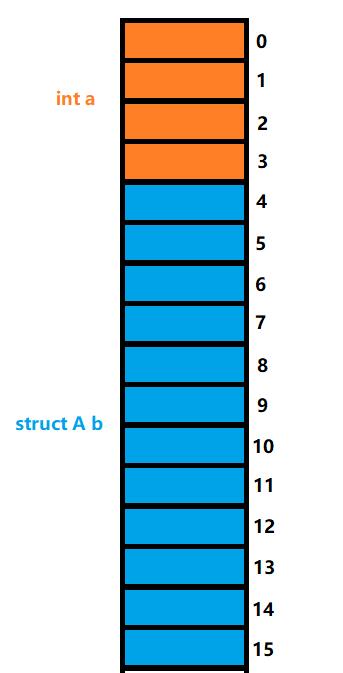
最后成员c,由于是char类型,所以对齐数=min{sizeof(char),默认对齐数8}=1,所以——
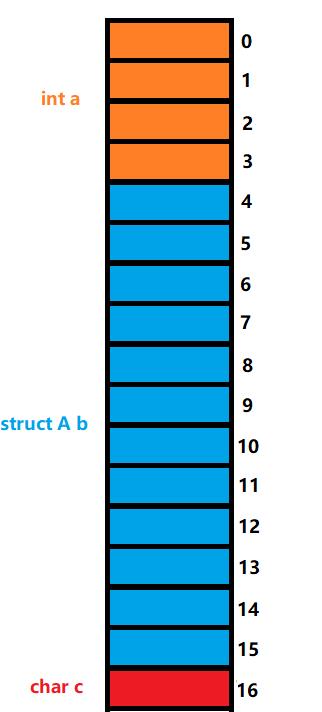
最终我们得到,这个结构体占据了偏移量为0~16的这17个内存单元,由于成员a,b,c的对齐数分别为4,4,1,所以取最大对齐数为三者的最大值:4,最终我们的结构体B的大小为大于等于17且为4的倍数的最小整数,即:20;
VS编译器下运行:
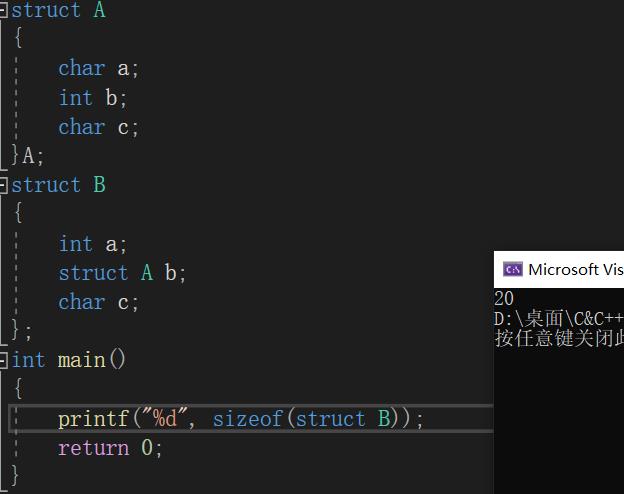
答案正确!
Part II、进阶例题分析
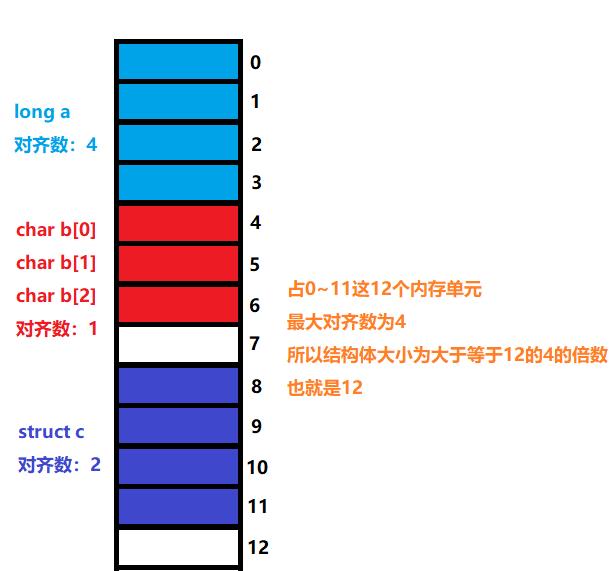
struct A
{
char a;
short b;
}A;
struct B
{
long c;
char a[3];
struct A b;
};
这题融合了上述讲解的四个对齐规则并且新添了一个数组成员。
对于数组而言,我们可以把它理解为n个连在一起的type类型的成员(其中n为数组大小,type为数组的成员类型),如这里的char a[3],就可以理解为3个连在一起的char类型成员。
篇幅起见,我们不再具体分析这道题了,读者可以自行分析然后对照着下面这张图来理解——
Part III、内存对齐有啥用?
这个问题,我想在刚刚做例题的时候你就已经发现了。内存对齐,算起来麻烦不说,还相当的浪费空间。按顺序存放不行么,为什么偏要按照对齐数存储呢?
大部分的参考资料都是如是说的:
- 平台原因(移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址 处取某些特定类型的数据,否则抛出硬件异常。
意思就是说:有的硬件平台能力达不到,只能在特定位置上访问数据:如这里的对齐数的整数倍;
- 性能原因: 数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问
什么意思呢?
我们知道,CPU实际上是有寻址步长的,32位的CPU一次能处理4个字节的数据,那么也就是寻址步长为4,只对编号为4的倍数的地址进行访问;64位CPU一次能处理8个字节的数据,寻址步长为8,只对编号为8的倍数的地址进行访问。
如图为64位下的示意图——

那么假设我们的数据是按照对齐数排列的,即:
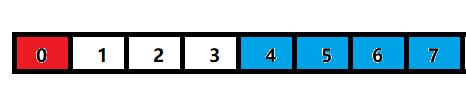
注:白色部分为浪费掉的内存
那么在32位系统下,通过一次访问就可以访问并获取蓝色方块的数据
倘若没有内存对齐:
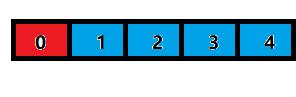
那么在32位系统下,我们需要先访问一次编号0往后的4个字节以获取蓝色方块数据的前三个,然后再访问编号4往后的4个字节的内存获取最后一份数据。这意味着,为了访问一个数据,本来需要两次解决的现在只要一次就可以搞定。
也许你还会疑问,说:为什么没有内存对齐的情况下,我不能直接从编号1开始往后获取数据呢?这样也是一次就搞定了啊?
这又得回到我们的第一点原因上了:并非所有硬件平台都能做到访问任意编号的内存地址的!所以,为了在所有平台上都能达到相对理想的访问速度,计算机系统采取了这样的一种以空间换取时间的做法!
Part IV、系列文章索引
【每天学一点系列~】字符串左/右旋的本质,你真的认清了嘛?
【每天学一点系列~】这些内存函数你知道么?还记得么[\\doge]
这篇文章带你弄懂了结构体大小的计算了嘛?如果是的话,给个三连呗亲!

以上是关于每天学一点系列~一文带你彻底弄懂结构体大小和内存对齐的主要内容,如果未能解决你的问题,请参考以下文章