第七篇:并发-恢复机制
Posted flying_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第七篇:并发-恢复机制相关的知识,希望对你有一定的参考价值。
目录
复习
ACID 属性
❖ 原子性:Xact 中的所有动作都发生,或者不发生。
❖ 一致性:如果每个 Xact 是一致的,并且 DB 开始一致,则它最终一致。
❖ 隔离:一个 Xact 的执行与其他 Xact 的执行隔离。
❖ 持久性:如果 Xact 提交,其效果将持续存在。
❖ 恢复管理器(Recovery manager)保证原子性和持久性。
动机
❖ 原子性:
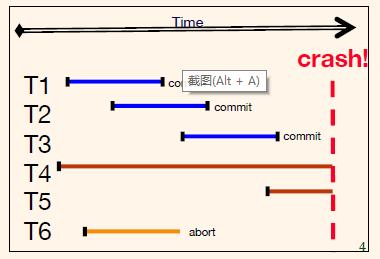
– 交易可能会中止(“回滚”)。 例如。 T6
❖ 持久性:
– 如果 DBMS 停止运行怎么办? (原因?)
❖ 系统重启后的期望行为:
– T1、T2 和 T3 应该是耐用持久的,因为它们是在崩溃前提交的。
– T4、T5、T6 应中止(未见效果)。
假设
❖ 并发控制生效。
– 特别是严格的 2PL(两段锁定)。
❖ 更新正在“就地”进行。
– 即数据在磁盘上被覆盖(删除)。
❖ 保证原子性和持久性的简单方案?
缓冲区缓存(池)
1. 数据存储在磁盘上
2. 读取数据项需要从磁盘到包含该项目的内存读取整页数据(通常为 4K 或 8K 字节的数据,具体取决于页面大小)。
3. 修改数据项需要将整个页面从磁盘读取到包含该项目的内存中,修改内存中的项目并将整个页面写入磁盘。
4. 步骤 2 和 3 可能非常昂贵,我们可以通过在内存中存储尽可能多的磁盘页面(缓冲区缓存)来最小化磁盘读取和写入的次数——这意味着如果感兴趣的磁盘页面总是在缓冲区缓存中检查, 如果不将关联的页面复制到缓冲区缓存就执行必要的操作。
5. 当缓冲区缓存已满时,我们需要从缓冲区缓存中驱逐一些页面,以便从磁盘中获取所需的页面。
6. 驱逐需要确保没有其他人正在使用该页面,并且任何修改过的页面都应该被复制到磁盘。
7. 由于多个事务同时执行,因此需要使用锁存器的附加锁定过程。 这些锁存器仅在操作期间使用(例如 READ/WRITE)并且可以立即释放,这与必须保持锁定直到事务结束的记录锁不同。
❖ 修复(pageid)
– 如果页面不在缓冲区缓存中,则从磁盘读取页面到缓冲区缓存中
– 由于事务正在访问内容,因此无法从缓冲区缓存中删除固定页面
❖ unfix(pageid)
– 该页面未被事务使用,就 unfix 调用事务而言,该页面可以被驱逐。 (我们需要检查以确保没有其他人想要该页面,然后才能将其驱逐)
数据库系统的主要组成部分
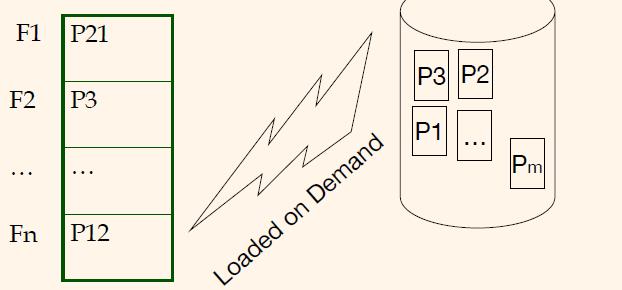
❖ 缓冲区管理器
从数据库按需加载到缓冲区
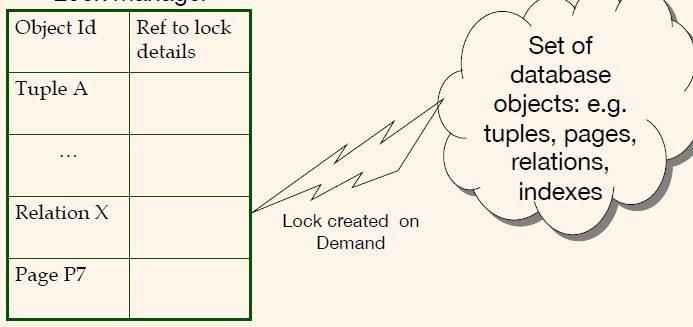
锁管理器
按需加锁
 处理缓冲池(缓存)
处理缓冲池(缓存)
❖ 在提交时强制写入磁盘?
– 响应时间短。
– 但提供耐用性/持久性。
❖ 不强制,即使提交后也不修改磁盘上的数据,尽可能将页面留在内存中。
– 提高响应时间和效率,因为许多读取和更新可以在主内存中而不是在磁盘上进行。
- 持久性成为问题,因为如果发生崩溃,更新可能会丢失
❖ 从未提交的 Xacts 中窃取缓冲池帧?
– 如果不是,则吞吐量较差。
– 如果是这样,我们如何确保原子性?
更多关于窃取和强制
❖ STEAL(为什么很难执行原子性)
– 窃取 帧F:F 中的当前页(比如 P)被写入磁盘; 一些 Xact 锁定 P。
◆ 如果锁定P 的Xact 中止怎么办?
◆ 必须记住窃取时P 的旧值(以支持撤销对页P 的写入)。
❖ NO FORCE(为什么执行 Durability 很难)
– 如果系统在修改页面写入磁盘之前崩溃怎么办?
– 在提交时,在方便的地方,尽可能少写,以支持 REDOing 修改。
基本想法:日志记录
❖ 在日志中记录每次更新的 REDO(新值)和 UNDO(旧值)信息。
– 顺序写入日志(将其放在单独的磁盘上)。
– 写入日志的最少信息 (diff),因此多个更新在单个日志页面。
❖ 日志:REDO/UNDO 操作的有序列表
– 日志记录包含:
<XID、pageID、偏移量、长度、旧数据、新数据>
– 以及其他控制信息(我们很快就会看到)。
预写日志 (WAL)
❖ 预写日志协议:
1. 必须在相应的数据页到达磁盘(被盗)之前强制更新具有旧值和新值的日志记录。
2. 必须在提交前将所有日志记录写入磁盘(强制)以用于 Xact。
❖ 1. 保证原子性,因为我们可以撤消由中止事务执行的更新并重做那些已提交事务的更新。
❖ 2. 保证耐用性。
❖ 日志记录(和恢复!)究竟是如何完成的? – 我们研究 ARIES 算法。
WAL 和日志
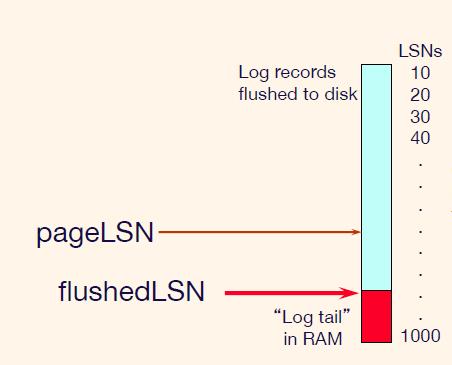
❖ 每条日志记录都有一个唯一的日志序列号 (LSN)。
– LSN 一直在增加。
❖ 每个数据页包含一个pageLSN。
– 更新该页面的最新日志记录的 LSN。
❖ 系统跟踪flushedLSN。
– 到目前为止已刷新最大 LSN 。
❖ WAL:在页面写入磁盘之前确保
pageLSN <= flushedLSN
如下图,此时无法将页面写入磁盘
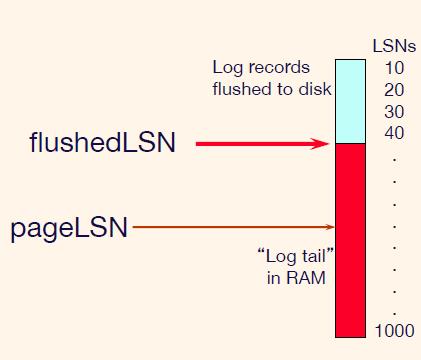
如下图,此时可以将页面写入磁盘
日志记录
| 日志记录字段 | 可能的日志记录类型(对应左侧的type) |
| prevLSN XID type length pageID offset before-image after-image | ❖ Update 表示提交结束或中止结束 补偿日志记录 |
其他日志相关状态
❖ 事务表:
– 每个活动的 Xact 一个条目。
– 包含 XID、状态(运行/提交/中止)和 lastLSN。
❖ 脏页表:
– 缓冲池中每个脏页一个条目。
– 包含 recLSN -- 日志记录的 LSN,自从从磁盘加载到缓冲区缓存后,首先导致页面变脏的日志记录的 LSN。
事务Xact 的正常执行
❖ 一系列读写,然后是提交或中止。
– 我们假设在磁盘上写操作是原子的。
◆ 在实践中,处理非原子写入的附加细节。 我们之前讨论过如何做到这一点。
❖ 严格的 2PL两段锁。
❖ STEAL、NO-FORCE 缓冲区管理,带有预写日志WAL。
检查点
❖ DBMS 会定期创建检查点,以最大限度地减少系统崩溃时恢复所需的时间。 写入日志:
– 开始检查点记录:指示 检查点 何时开始。
– 结束检查点记录:包含当前 Xact 事务表和脏页表。 这是一个“模糊检查点”:
◆ 其他Xacts 继续运行; 所以这些表仅在开始检查点记录时准确。
◆ 不尝试将脏页强制写入磁盘; 检查点的有效性受到对脏页的最旧未写入更改的限制。 (因此,定期将脏页刷新到磁盘是个好主意!)
– 将 检查点 记录的 LSN 存储在安全的地方(主记录)。
大图:什么存储在哪里
| Log | DB | RAM |
| LogRecords(日志记录) prevLSN | Data pages(数据页) each with a pageLSN | Xact Table(事务表) lastLSN status Dirty Page Table(脏页表) recLSN flushedLSN |
简单事务中止
❖ 现在,考虑 Xact 事务的显式中止。
– 不涉及故障。
❖ 我们要以相反的顺序“回放”日志,UNDOing 更新。
– 从 Xact 表中获取 Xact 的 lastLSN。
– 可以通过 prevLSN 字段向后跟踪日志记录链。
– 在开始 UNDO 之前,写入 Abort 日志记录。
◆ 用于在UNDO 期间从崩溃中恢复!
❖ 要执行UNDO,必须有数据锁!
- 没问题!
❖ 在恢复一个页的旧值之前,写一个 CLR(补偿日志记录):
– 您在撤消时继续记录!!
– CLR 有一个额外的字段:undonextLSN
◆ 指向下一个要撤销的 LSN(即我们当前正在撤销的记录的 prevLSN)。
– CLR 永远不会撤消(但在重复历史时它们可能会重做:保证原子性!)
❖ 在 UNDO 结束时,写入“结束”日志记录。
事务中止示例

事务提交
❖ 将提交记录写入日志。
❖ 刷新到 Xact 的 lastLSN 的所有日志记录。
– 保证flushedLSN >= lastLSN。
– 请注意,日志刷新是顺序的、同步写入到磁盘 –(写入磁盘的速度非常快)。
– 每个日志页有许多日志记录 –(由于多次写入而非常高效)。
❖ Commit() 提交返回。
❖ 将结束记录写入日志。
故障恢复:大图
❖ 从检查点开始(通过主记录找到)。
❖ 三阶段。 需要:
– 找出自检查点以来提交的 Xact,哪些失败(分析)。
– 重做所有动作。
◆(重复历史)
– 失败的 Xacts 的 UNDO 效果。
恢复:分析阶段
❖ 在检查点重建状态。
– 通过 end_checkpoint(最后的检查点) 记录。
❖ 从检查点向前扫描日志。
– 结束记录:从 Xact 事务表中删除 Xact。
– 其他记录:将 Xact 添加到 Xact 表,设置 lastLSN=LSN,在提交时更改 Xact 状态。
– 更新记录:如果 P 不在脏页表中,
◆ 将 P 添加到 D.P.T.脏页表,设置其 recLSN=LSN。
恢复:重做阶段
❖ 我们重复历史以重建崩溃时的状态:
– 重新应用所有更新(即使是中止的 Xact!),重做 CLR(补偿日志记录)。
❖ 从 D.P.T. 中包含最小 recLSN 的 log rec 向前扫描。 对于每个 CLR 或更新日志 recLSN,重做操作,除非:
– 受影响的页面不在脏页表中,或
– 受影响的页面在 D.P.T. 脏页表中,但 recLSN > LSN,或
– pageLSN(在数据库中)>=LSN。
❖ 重做一个动作:
– 重新应用记录的操作。
– 将 pageLSN 设置为 LSN。 没有额外的日志记录!
恢复:UNDO 阶段
ToUndo={ l | l 是“失败者”Xact 事务的最后一个 LSN}
我们可以从 Xtable 形成这个列表。
重复:
– 在 ToUndo 中选择最大的 LSN。
– 如果这个 LSN 是一个 CLR 并且 undonextLSN==NULL
◆ 为这个Xact 写一个结束记录。
– 如果这个 LSN 是一个 CLR,并且 undonextLSN != NULL
◆ 将undonextLSN 添加到ToUndo
◆ (问:其他 CLR 会发生什么情况?)
– 否则此 LSN 是更新。 撤消更新,编写 CLR,将 prevLSN 添加到 ToUndo。
直到 ToUndo 为空。
恢复示例
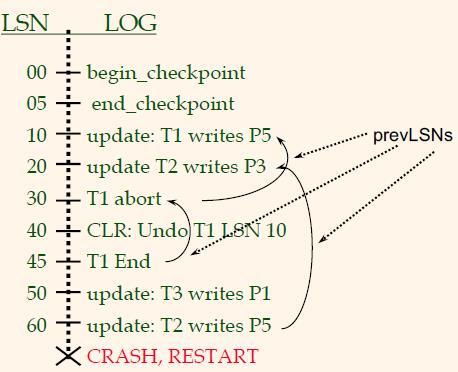
示例:重启时崩溃!

其他崩溃问题
❖ 如果系统在分析过程中崩溃会怎样? 在重做期间?
❖ 你如何限制REDO的工作量?
– 在后台异步刷新。
– 观看“热点”!
❖ 如何限制 UNDO 的工作量?
– 避免长时间运行的 Xact事务。
日志/恢复总结
❖ 恢复管理器保证原子性和持久性。
❖ 使用 WAL 允许 STEAL/NO-FORCE 而不牺牲正确性。
❖ LSN 识别日志记录; 每个交易链接到反向链(通过 prevLSN)。
❖ pageLSN 允许比较数据页和日志记录。
❖ 检查点:一种限制恢复时要扫描的日志量的快速方法。
❖ 恢复工作分 3 个阶段:
– 分析:从检查点转发。
– 重做:从最旧的 recLSN 转发。
– 撤消:从末尾向后倒退到崩溃时存活的最旧 Xact 的第一个 LSN。
❖ 在撤消时,写入 CLR。
❖ 重做“重复历史”:简化逻辑!
分布式事务处理中的原子性
两阶段提交协议(2PC)有助于在分布式事务处理中实现原子性
两阶段提交协议
– 协调者或参与者可以中止交易
- 如果参与者中止,它必须通知协调员
- 如果参与者在超时时间内没有响应,协调器将中止
– 如果中止,协调器要求所有参与者回滚
– 如果中止,中止日志将被强制写入协调器和所有参与者的磁盘
OK,今天的内容就到这里告一段落,基本这一部分我想要讲的东西也差不多了,后续可能会针对后面几篇章节较为繁琐抽象的概念进行细节或者专题式的讲解,敬请期待哟!谢谢!有问题还是欢迎随时评论交流!
以上是关于第七篇:并发-恢复机制的主要内容,如果未能解决你的问题,请参考以下文章