spark作业--实时分析springboot日志
Posted 一加六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark作业--实时分析springboot日志相关的知识,希望对你有一定的参考价值。
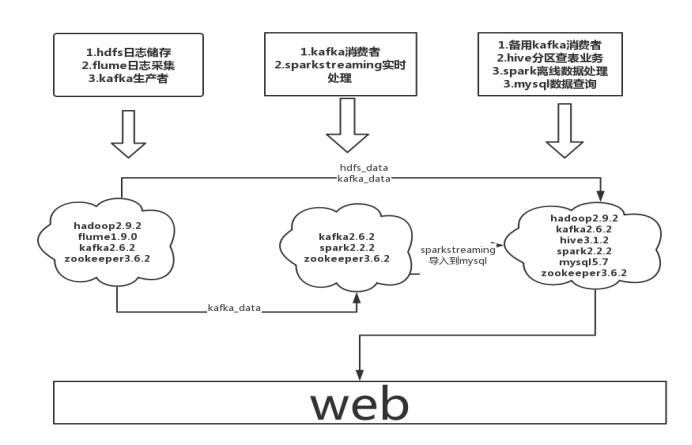
在云服务器上做的,由于白嫖的云服务器性能比较差,就设计了如下架构。
功能与设计
(大数据集群+架构设计+功能分析与设计)
总体架构图
功能:
订单成交量统计分析
历史成交总金额
热门分类的实时和离线统计分析
热门商品的实时和离线统计分析
活跃用户统计分析
项目实现
SpringBoot tmall商城部署
在服务器git拉取tmall springboot项目到本地,配置mysql,创建对应数据库,运行sql文件,复制数据库,运行springboot项目,生成日志文件到/root/log/info/下
flume采集
flume采集数据有两个流向,一个存入hdfs,另一个为kafkachannel。
数据存入hdfs的用作离线分析,kafkachannel则将数据给到sparkstreaming实时处理
数据流向
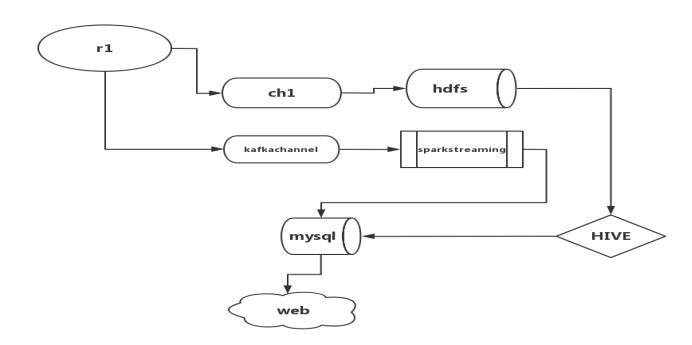
flume采集方案配置文件如下:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a3.sources = r3
a3.sinks = sinkhdfs
a3.channels = ch1 kafka-channel
# Define an Avro source called avro-source1 on a3 and tell it
a3.sources.r3.channels = ch1 kafka-channel
#a3.sources.r3.type = spooldir
#a3.sources.r3.spoolDir = /root/logs/info
#a3.sources.r3.ignorePattern = ^(.)*\\\\.tmp$
a3.sources.r3.type = exec
a3.sources.r3.command = tail -F /root/logs/info/info.log
# Define a memory channel called ch1 on a3
a3.channels.ch1.type = memory
a3.channels.ch1.capacity = 10000000
a3.channels.ch1.transactionCapacity = 100000
a3.channels.ch1.keep-alive = 10
a3.channels.kafka-channel.type = org.apache.flume.channel.kafka.KafkaChannel
a3.channels.kafka-channel.kafka.bootstrap.servers = master:9092,slave2:9092
a3.channels.kafka-channel.kafka.topic = tmalllog
a3.channels.kafka-channel.kafka.producer.acks = 1
a3.sinks.k1.serializer.class=kafka.serializer.StringEncoder
a3.channels.kafka-channel.parseAsFlumeEvent = false
kafka-streaming实时处理
需搭建zookeeper、kafka集群,消费来自kafka生产者的消息
编写sparkstreaming应用程序
(1)添加kafka的pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.hgu</groupId>
<artifactId>sparkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.3</spark.version>
<hadoop.version>2.9.2</hadoop.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>provided</scope>
</dependency>
<!-- 导入scala的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- 导入spark的依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.2.3</version>
</dependency>
<!-- 指定hadoop-client API的版本 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<!-- 编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<!-- 编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
<filter>
<artifact>junit:junit</artifact>
<includes>
<include>junit/framework/**</include>
<include>org/junit/**</include>
</includes>
<excludes>
<exclude>org/junit/experimental/**</exclude>
<exclude>org/junit/runners/**</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
实时处理代码
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.regexp_extract
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import java.util.{Date, Properties}
object Kafka_spark_streaming {
def main(args: Array[String]): Unit = {
// offset保存路径
val checkpointPath = "file:///export/data/kafka/checkpoint/kafka-direct"
val conf = new SparkConf()
.setAppName("ScalaKafkaStreaming")
.setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint(checkpointPath)
val spark: SparkSession = new SparkSession.Builder().master("local").appName("sqlDemo").getOrCreate()
val bootstrapServers = "master:9092,slave1:9092,slave2:9092"
val groupId = "flume"
val topicName = "tmalllog"
val maxPoll = 500
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> bootstrapServers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> maxPoll.toString,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
)
case class schema(mytime: String, action: String, frequency: Int)
val kafkaTopicDS = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set(topicName), kafkaParams))
import spark.implicits._
val properties = new Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "kun/roo123")
properties.setProperty("driver", "com.mysql.jdbc.Driver")
val uri = "jdbc:mysql://slave2:3306/tmalldata?useSSL=false"
kafkaTopicDS.foreachRDD(
foreachFunc = rdd => if (!rdd.isEmpty()) {
//数据业务逻辑处理
val now: Long = new Date().getTime
val now2: String = now.toString
val action_df = rdd.map(_.value)
.map(_.split("-"))
.filter(x => x.length == 3)
.map(x => x(2))
.map(x => (x, 1))
.reduceByKey(_ + _)
.map(x => (now2, x._1, x._2))
.toDF("mytime", "action", "frequency")
val top_category = action_df.select("*").where("action like '%分类ID为%'").orderBy(action_df("frequency").desc)
if (top_category.count()>0){
top_category.show()
top_category.write.mode("append").jdbc(uri, "category", properties)}
val product_Popular_Buy = action_df.select("*").where("action like '%通过产品ID获取产品信息%'").orderBy(action_df("frequency").desc)
if (product_Popular_Buy.count()>0){product_Popular_Buy.show()
product_Popular_Buy.write.mode("append").jdbc(uri, "product", properties)}
val Active_users = action_df.select("*").where("action like '%用户已登录,用户ID%'").orderBy(action_df("frequency"))
if(Active_users.count()>0){
Active_users.show()
Active_users.write.mode("append").jdbc(uri, "activeusers", properties)}
val money = action_df.select("*").where("action like '%总共支付金额为%'").orderBy(action_df("frequency").desc)
val money2 = money.withColumn("single_transaction", regexp_extract($"action", "/d+", 0))
if(money2.count()>0){
money2.show()
money2.write.mode("append").jdbc(uri, "trading", properties)
}
}
)
ssc.start