从零开始学架构-day05
Posted Jeff、yuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始学架构-day05相关的知识,希望对你有一定的参考价值。
高性能缓存架构
当服务使用关系型数据库已经达到性能瓶颈的时候我们应该怎么办,数据库已经分片了,也分库分表了,索引什么也都极致了(一般不可能)但是还是扛不住高流量。有点经验的同学都会说:“加缓存,上redis or 直接应用内存(缓存)“。
什么时候用高性能缓存架构?
-
需要经过复杂运算后得出的数据,存储系统无能为力
- 当我们是一个用户中心的系统,需求是提供在线用户的人数,那我们肯定不能去select count(*) 数据库去统计吧,一般
-
读多写少的数据,存储系统有心无力
-
微信,我们每天发不了几个朋友圈,甚至不怎发的,然而我们每天都在看朋友圈(读多写少)
-
据个人经历,一般C端的系统大多是读多写少的,然而B端一般都是写多读少(但是B端一般流量都不会太大)
-
-
极端的热点数据查询
- 什么是极端 热点数据? 微博上的热搜,”爆“ ,一时间大家都去看这个点下的数据,微博如果不用缓存的结果是什么,下一个热搜又出来的 ”微博挂掉了“ (开个玩笑)。
什么是高性能缓存架构
- 先认识一下什么是缓存
- 缓存,是一种存储数据的组件,它的作用是让对数据的请求更快地返回。(上面的例子充分体现)
- 缓存一般都是放在内存中来做的,还有人认为缓存就是内存,这个世界上就没有什么绝对的事情, 见识不够,千万不要妄下定论。(360 开源的 Pika 就是使用 SSD 存储数据解决 Redis 的容量瓶颈的。)一般我们使用内存,因为我们常用的redis就是纯内存来进行存储的.
- 缓存常见的几种类型:
a. 静态缓存:静态缓存在 Web 1.0 时期是非常著名的,它一般通过生成 Velocity 模板或者静态 html 文件来实现静态缓存,在 nginx 上部署静态缓存可以减少对于后台应用服务器的压力
b. 分布式缓存:Memcached、Redis
c. 热点本地缓存: 热点本地缓存主要部署在应用服务器的代码中,用于阻挡热点查询对于分布式缓存节点或者数据库的压力,通过应用服务内部的容器进行存储:HashMap(currentHashMap,TreeMap等),Caffeine Cache,Guava Cache等
- 使用缓存带来的问题
不得不说,这都快被面试官问烂了,玩归玩,闹归闹,别拿缓存开玩笑(无里头)。来认真看下:
- 缓存穿透
- 缓存穿透是指缓存没有发挥作用,业务系统虽然去缓存查询数据,但缓存中没有数据,业务系统需要再次去存储系统查询数据。
- 通常情况下有两种情况:
- 存储数据不存在,有恶意请求,也有正常请求,请求本来就没有的用户
- 缓存数据生成耗费大量时间或者资源 ,我们都知道,内存是相对比较贵的资源,我们还是比较 省着点用的,热点缓存,然后到时见失效。(这里的失效只是一部分,也需有同学就会说:这不就是缓存雪崩吗?)
- 缓存雪崩
- 缓存雪崩是指当缓存失效(过期)后引起系统性能急剧下降的情况。其实很好理解也就是超热点的数据,然后key失效,导致查不到这个数据,直接击穿到数据库。
- 解决缓存问题的集中策略
大佬们的经验和总结,总结出来集中缓存的策略来解决我们遇到的问题,和缓存设计
-
Cache Aside(旁路缓存)策略
Cache Aside 策略(也叫旁路缓存策略),这个策略数据以数据库中的数据为准,缓存中的数据是按需加载的。它可以分为读策略和写策略,
其中读策略的步骤是:从缓存中读取数据;如果缓存命中,则直接返回数据;如果缓存不命中,则从数据库中查询数据;查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是:更新数据库中的记录;删除缓存记录。 -
Read/Write Through(读穿 / 写穿)策略
- 这个策略的核心原则是用户只与缓存打交道,由缓存和数据库通信,写入或者读取数据。这就好比你在汇报工作的时候只对你的直接上级汇报,再由你的直接上级汇报给他的上级,你是不能越级汇报的。
- Write Through 的策略是这样的:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做“Write Miss(写失效)”。
- 一般来说,我们可以选择两种“Write Miss”方式:一个是“Write Allocate(按写分配)”,做法是写入缓存相应位置,再由缓存组件同步更新到数据库中;另一个是“No-write allocate(不按写分配)”,做法是不写入缓存中,而是直接更新到数据库中。
- 在 Write Through 策略中,我们一般选择“No-write allocate”方式,原因是无论采用哪种“Write Miss”方式,我们都需要同步将数据更新到数据库中,而“No-write allocate”方式相比“Write Allocate”还减少了一次缓存的写入,能够提升写入的性能。

-
Write Back(写回)策略
-
这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。不描述那么多了,有兴趣的可以拜读这篇文章:https://time.geekbang.org/column/article/150881
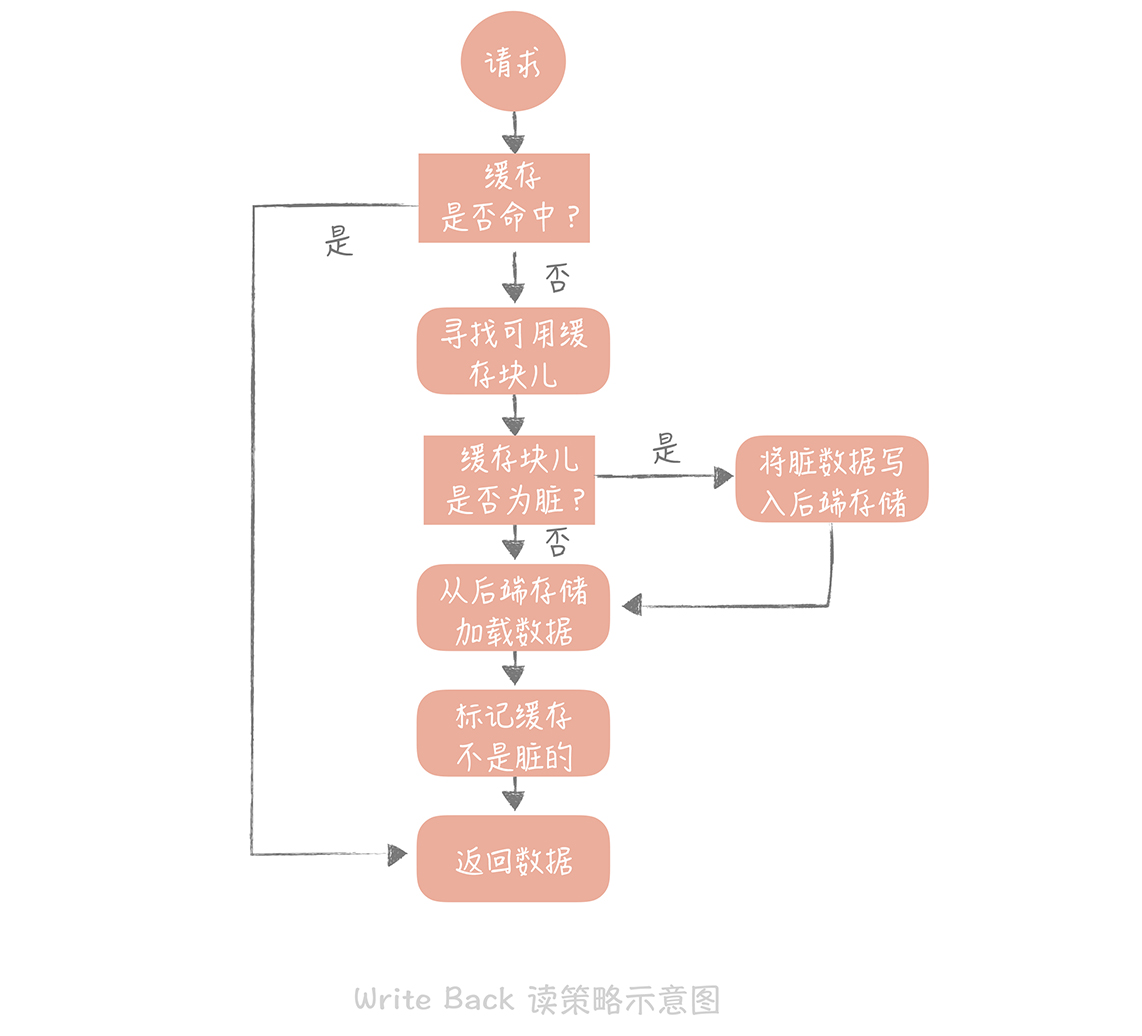
-
- 说了这么多那到底什么缓存是高性能缓存架构?
- 那就是我么通过自己的经验和具体的业务逻辑,通过某些缓存中间件设计一个可以达到高性能的高流量的服务架构。(怎么感觉我放了个屁)。
具体实现的一个高性能架构
使用到的中间件
redis ,guava cache , canal mysql kafka 。
业务场景
- 后台配置config ,应用需要读取config 进行使用,读取的量很大,有上万级别的QPS,再次更改的时候可以达到实时且安全的更新。
方案
-
数据的持久化,mysql
-
流量太高,mysql 甚至redis也有点危险,所以两级缓存,redis + guava cache (内存)
-
需要实时更新,监听mysql的binlog 发送消息给应用更新内存 canal + kafka (其他的消息队列也没什么问题)
-
具体的业务架构图:
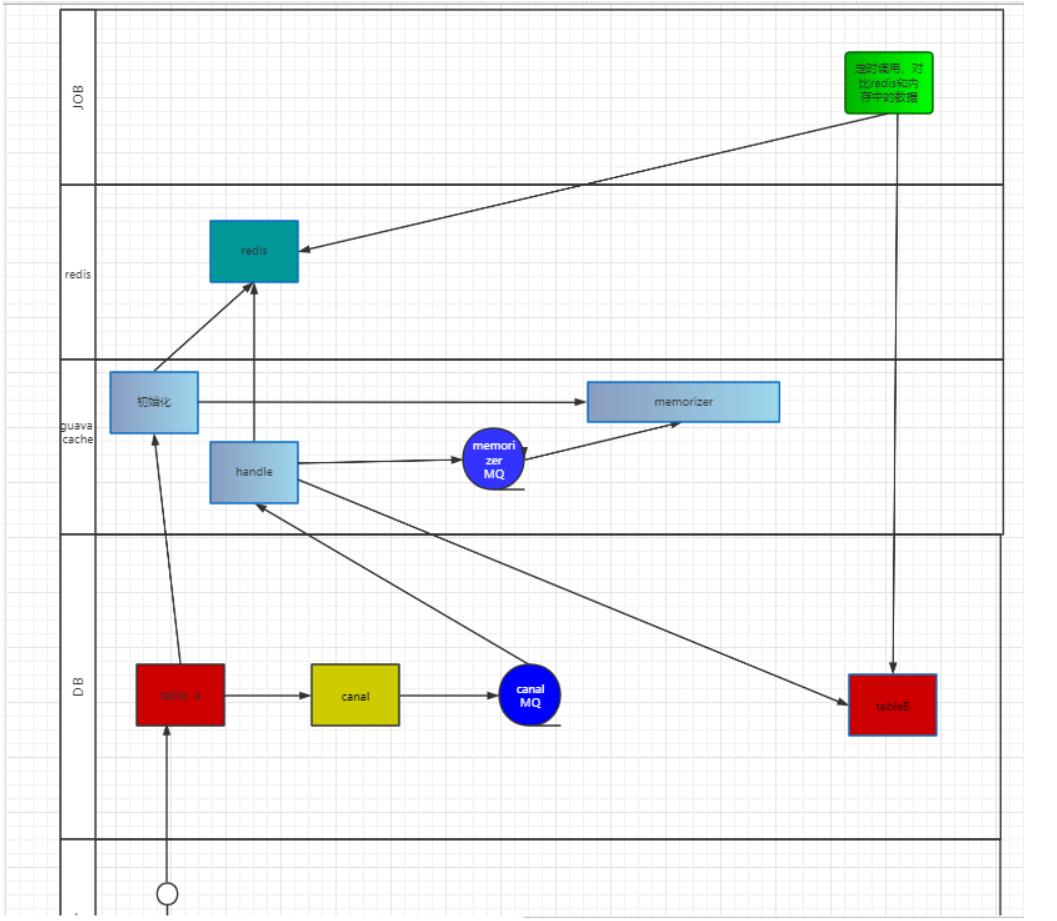
-
看完图,你也许心中会飘过:“画的这是个吊玩意!!!!“ 我接受批评,确实不好看,也不清晰
-
我大概描述一下过程:
- 更新表的过程:
后台更新table a 表,更新后canal监听binlog 通过队列消息推送给应用端,应用端拿到消息后 刷新redis ,
且同时再发送消息给一个内存队列(异步防止这个流程太长),且同时存储内存的时候,将key 存入tableB 中(后续进行对数,防止数据不一致的问题)
- 重新启动服务的过程:
分页拉去数据库数据,更新进内存和缓存中去。
-
job的作用是每周进行对数: 将内存和数据库,还有guava 中的进行对数更新。
-
我这只是画了存储的,读取的没有画,大家想想怎么读取数据呢?? (其实是我不想写了)
-
还有就是这种架构结合上面的集中策略,会有什么问题呢?(我们一块思考一下)
参考
https://time.geekbang.org/column/article/150881
https://time.geekbang.org/column/article/8640
以上是关于从零开始学架构-day05的主要内容,如果未能解决你的问题,请参考以下文章
《从零开始学Swift》学习笔记(Day 59)——代码排版
《从零开始学Swift》学习笔记(Day 2)——使用Web网站编写Swift代码
《从零开始学Swift》学习笔记(Day1)——我的第一行Swift代码