图像分类一文彻底搞明白GoogLeNet
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像分类一文彻底搞明白GoogLeNet相关的知识,希望对你有一定的参考价值。
1、 模型介绍
GoogLeNet作为2014年ILSVRC在分类任务上的冠军,以6.65%的错误率力压VGGNet等模型,在分类的准确率上面相比过去两届冠军ZFNet和AlexNet都有很大的提升。从名字GoogLeNet可以知道这是来自谷歌工程师所设计的网络结构,而名字中GoogLeNet更是致敬了LeNet。GoogLeNet中最核心的部分是其内部子网络结构Inception,该结构灵感来源于NIN,至今已经经历了四次版本迭代(Inception_v1-4)。下表是Inception_v1-4提出的时间表
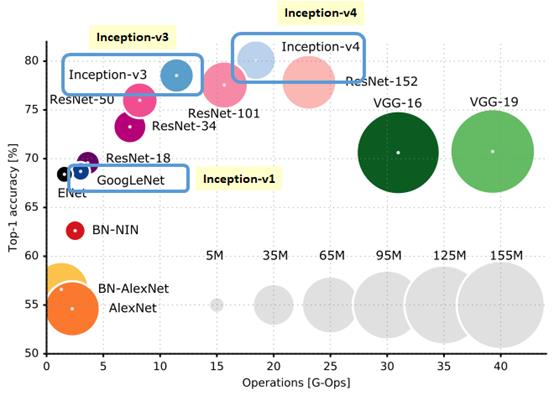
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,但一味地增加,会带来诸多问题:
1)参数太多,如果训练数据集有限,很容易产生过拟合;
2)网络越大、参数越多,计算复杂度越大,难以应用;
3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
我们希望在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。在这种需求和形势下,Google研究人员提出了Inception的方法。
2、 模型结构

如图所示,GoogLeNet相比于以前的卷积神经网络结构,除了在深度上进行了延伸,还对网络的宽度进行了扩展,整个网络由许多块状子网络的堆叠而成,这个子网络构成了Inception结构。为了更详细的了解Inception,下面对Inception_v1、Inception_v2、Inception_v3、Inception_v4做更详细的说明。
Inception_v1
Inception_v1在同一层中采用不同的卷积核,并对卷积结果进行合并; 下面的两张图展示Inception_v1采用的两种卷积模块a和b。

对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
具体改进后的Inception Module如下图:

GoogLeNet中Inception_v1网络参数配置
| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 参数个数 |
| 卷积层 C_ 11 | H× W ×C_1 | 1 ×1 × C_2 /2 | frac H 2 × frac W 2 × C_2 | (1 ×1 × C_1 +1) × C_2 |
| 卷积层 C_ 21 | H × W × C_2 | 1 ×1 × C_2 /2 | frac H 2 × frac W 2 × C_2 | (1 ×1 × C_2 +1) × C_2 |
| 卷积层 C_ 22 | H × W × C_2 | 3 ×3 × C_2 /1 | H × W × C_2 /1 | (3 ×3 × C_2 +1) × C_2 |
| 卷积层 C_ 31 | H × W × C_1 | 1 ×1 × C_2 /2 | frac H 2 × frac W 2 × C_2 | (1 ×1 × C_1 +1) × C_2 |
| 卷积层 C_ 32 | H × W × C_2 | 5 ×5 × C_2 /1 | H × W × C_2 /1 | (5 ×5 × C_2 +1) × C_2 |
| 下采样层 S_ 41 | H × W × C_1 | 3 ×3/2 | frac H 2 × frac W 2 × C_2 | 0 |
| 卷积层 C_ 42 | frac H 2 × frac W 2 × C_2 | 1 ×1 × C_2 /1 | frac H 2 × frac W 2 × C_2 | (3 ×3 × C_2 +1) × C_2 |
| 合并层 M | frac H 2 × frac W 2 × C_2 ( ×4) | 拼接 | frac H 2 × frac W 2 ×( C_2 ×4) | 0 |
Inception_v2
Inception_v2组合不同卷积核的堆叠形式,并对卷积结果进行合并;把5*5的卷积改成了两个3*3的卷积串联,它说一个5*5的卷积看起来像是一个5*5的全连接,所以干脆用两个3*3的卷积,第一层是卷积,第二层相当于全连接,这样可以增加网络的深度,并且减少了很多参数。模型的结构如下图:


Inception_v2还引入了使用了Batch Normalization,加了这个以后训练起来收敛更快,学习起来自然更高效,可以减少dropout的使用。
28x28 的 Inception 模块的数量由 2 增加到了 3.
Inception 模块,Ave 和 Max Pooling 层均有用到. 参考表格。
两个 Inception 模块间不再使用 pooling 层;而在模块 3c 和 4e 中的 concatenation 前采用了 stride-2 conv/pooling 层.
详细的参数列表

Inception_v3
Inception_v3则在v_2基础上进行深度组合的尝试,输入改为299×299×3。
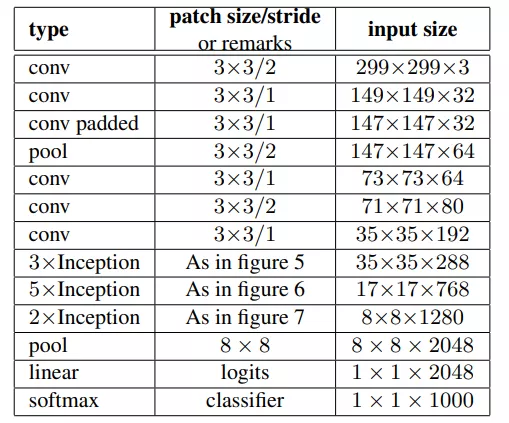
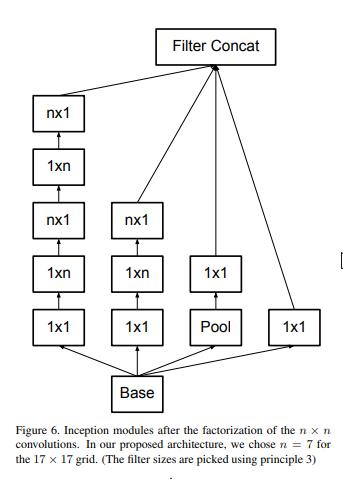
Inception_V3出了采用Inception_V2中,将5×5的卷积分解成两个3×3的卷积,还衍生出了非对称分解,将一个3x3的卷积分解为3x1和1x3,进一步衍生出了一种混合两种分解方式的结构Inception_V3三种结构如下图:


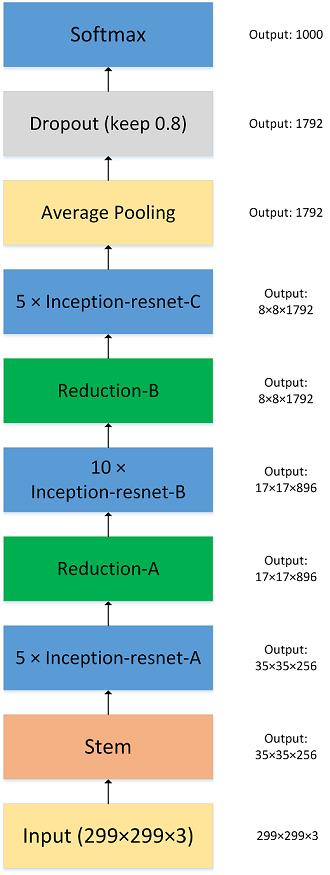
Inception_v4
Inception_v4结构相比于前面的版本更加复杂,不仅使用了前面的Inception,同时子网络中嵌套着子网络,作者还尝试了 Residual Connection。Inception_v4的输入是384×384×3

总结
-
Inception V1——构建了1x1、3x3、5x5的 conv 和3x3的 pooling 的分支网络,同时使用 MLPConv 和全局平均池化,扩宽卷积层网络宽度,增加了网络对尺度的适应性;
Inception V2——提出了 Batch Normalization,代替 Dropout 和 LRN,其正则化的效果让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高,同时学习 VGG 使用两个3´3的卷积核代替5´5的卷积核,在降低参数量同时提高网络学习能力;
Inception V3——引入了 Factorization,将一个较大的二维卷积拆成两个较小的一维卷积,比如将3´3卷积拆成1´3卷积和3´1卷积,一方面节约了大量参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力,除了在 Inception Module 中使用分支,还在分支中使用了分支(Network In Network In Network);
Inception V4——研究了 Inception Module 结合 Residual Connection,结合 ResNet 可以极大地加速训练,同时极大提升性能,在构建 Inception-ResNet 网络同时,还设计了一个更深更优化的 Inception v4 模型,能达到相媲美的性能
以上是关于图像分类一文彻底搞明白GoogLeNet的主要内容,如果未能解决你的问题,请参考以下文章
Keras CIFAR-10图像分类 GoogleNet 篇
Keras CIFAR-10图像分类 GoogleNet 篇