06 关于 dict
Posted 蓝风9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了06 关于 dict相关的知识,希望对你有一定的参考价值。
前言
关于 redis 的数据结构 dict[hashtable]
相关介绍主要围绕着如下测试用例, 来看看 dict[hashtable] 的存储, 以及 相关的 api
本文的 dict[hashtable] 相关代码 拷贝自 redis-6.2.0
代码来自于 https://redis.io/
dict[hashtable] 这个数据结构映射到 jdk 这边 类似于 java.util.HashMap/HashTable
很多操作 也是哈希表的基础操作, 呵呵 相当于又温习了一遍
测试用例
//
// Created by Jerry.X.He on 2021/2/24.
//
#include <iostream>
#include "../libs/sds.h"
#include "../libs/dict.h"
using namespace std;
// dict funcs
uint64_t dictSdsHash(const void *key);
int dictSdsKeyCompare(void *privdata, const void *key1, const void *key2);
void dictSdsDestructor(void *privdata, void *val);
// clearCallback
void clearCallback(void *value);
int main(int argc, char **argv) {
static dictType dt = {
dictSdsHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCompare, /* key compare */
dictSdsDestructor, /* key destructor */
NULL, /* val destructor */
};
sds name = sdsnew("name");
// dictCreate
dict *dict = dictCreate(&dt, NULL);
dictAdd(dict, sdsfromlonglong(11), sdsfromlonglong(11));
dictAdd(dict, sdsfromlonglong(12), sdsfromlonglong(12));
dictAdd(dict, sdsfromlonglong(13), sdsfromlonglong(13));
dictAdd(dict, sdsnew("key"), sdsnew("value"));
// dictAdd
int addResult = dictAdd(dict, name, sdsnew("jerry"));
int duplicatedAddResult = dictAdd(dict, name, sdsnew("jerryUpdated"));
// dictReplace
int replaceResult = dictReplace(dict, name, sdsnew("jerryReplace"));
// dictFind
dictEntry *nameEntry = dictFind(dict, name);
sds nameValue = (sds) (nameEntry->v.val);
// dictFetchValue
sds nameFetchValue = (sds) dictFetchValue(dict, name);
// dictResize
int resizedResult = dictResize(dict);
// dictGetIterator & dictNext
dictIterator *ite = dictGetIterator(dict);
dictEntry *iteEntry = NULL;
while ((iteEntry = dictNext(ite)) != NULL) {
cout << (sds) iteEntry->key << " -> " << (sds) iteEntry->v.val << endl;
}
dictReleaseIterator(ite);
// dictGetRandomKey
dictEntry *randomEntry = dictGetRandomKey(dict);
// dictGenHashFunction
int dicGenHash = dictGenHashFunction("jerry", 5);
int dicGenCaseHash = dictGenCaseHashFunction((const unsigned char *) "jerry", 5);
// dictEmpty
dictEmpty(dict, clearCallback);
int x = 0;
}
// dictSdsHash
uint64_t dictSdsHash(const void *key) {
return sdslen((sds) key);
}
// dictSdsKeyCompare
int dictSdsKeyCompare(void *privdata, const void *key1,
const void *key2) {
int l1, l2;
DICT_NOTUSED(privdata);
l1 = sdslen((sds) key1);
l2 = sdslen((sds) key2);
if (l1 != l2) return 0;
return memcmp(key1, key2, l1) == 0;
}
// dictSdsDestructor
void dictSdsDestructor(void *privdata, void *val) {
DICT_NOTUSED(privdata);
sdsfree((sds) val);
}
void clearCallback(void *value) {
cout << "clearCallback" << endl;
// cout << value << endl;
}
数据结构
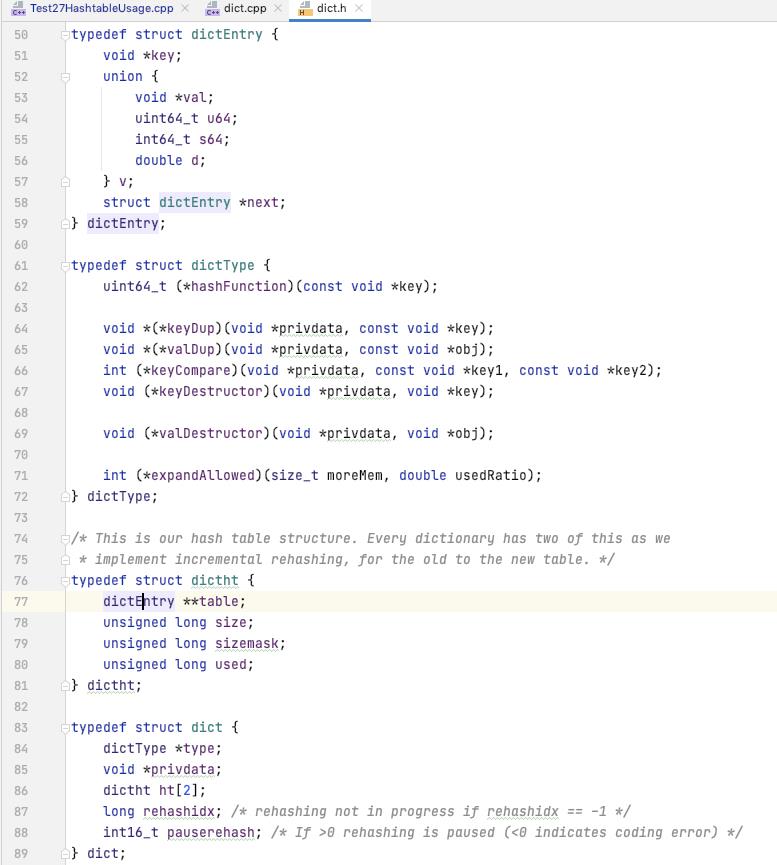
dictCreate
创建一个 dict 并初始化, 传入的 type 为 dict 所需要的一系列的业务函数
比如 如何计算给定的元素的 hash, key 怎么比较 等等
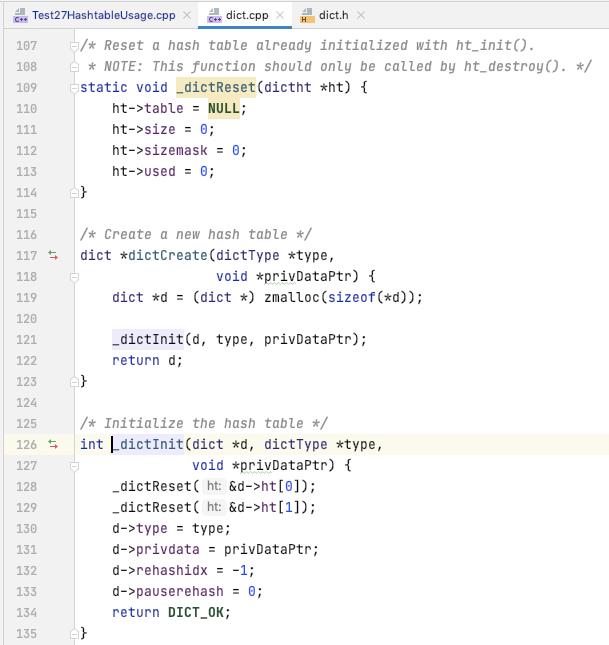
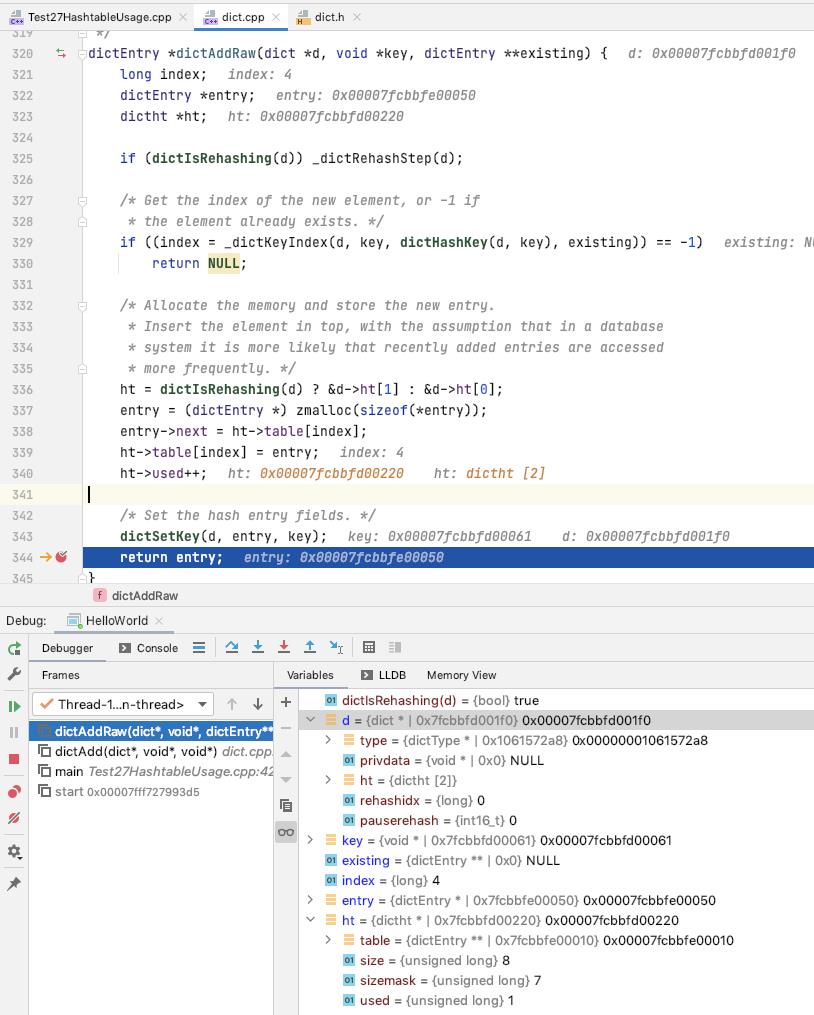
dictAdd
可以看出的是 在断点的位置, dict 里面又四个元素, 都存储在 ht[0] 里面
三个元素存储在 ht[0].table[2] 里面, 一个元素存储在 ht[0].table[3] 里面
然后 我们现在再往 dict 里面添加一个元素, 会触发 dict 的扩容, 所以我们这里就 dictAdd 和 扩容的方式一起来看
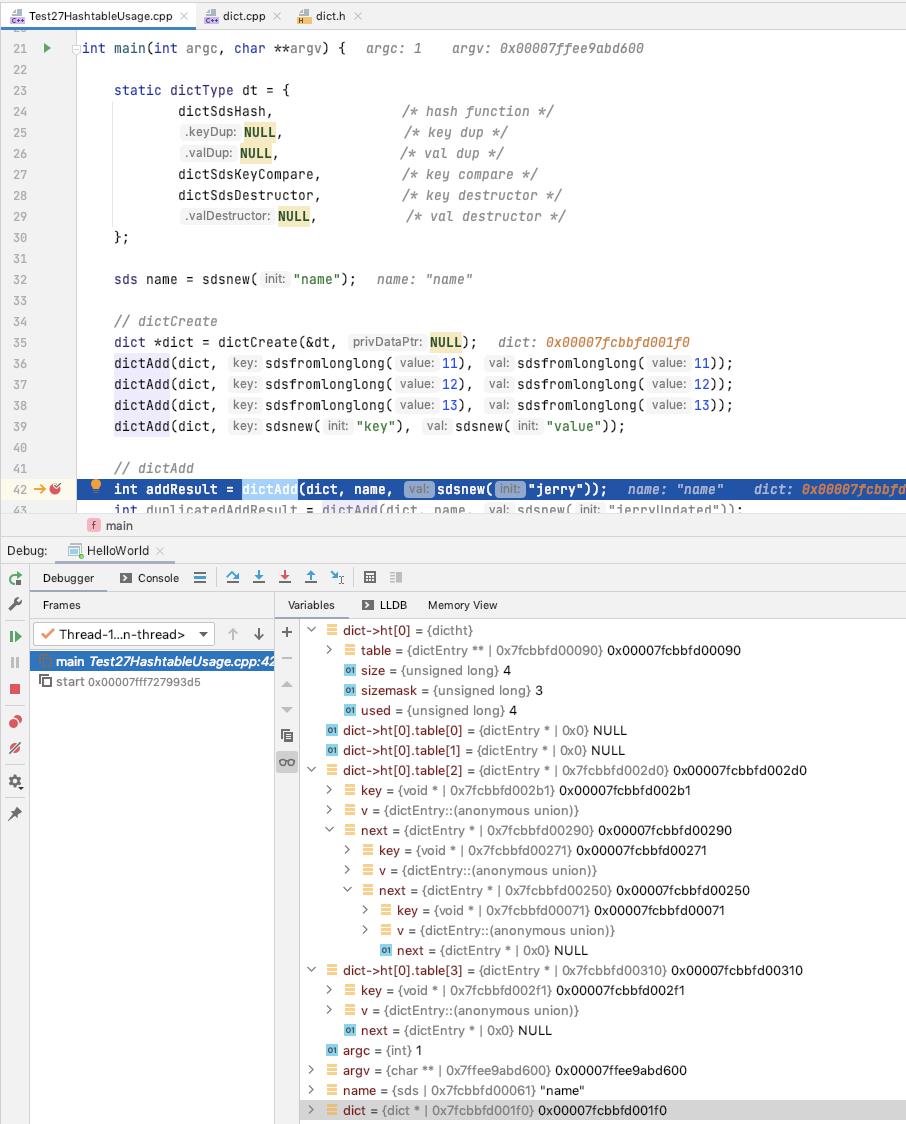
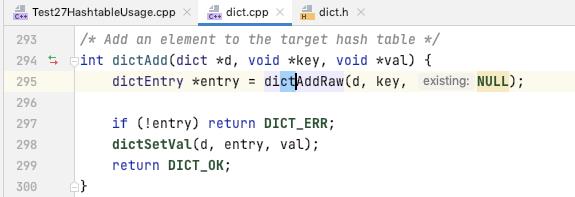
向 dict 中添加一个 entry(key, value)
如果 key 对应的 entry 已经存在了[dictAddRaw返回NULL], 则返回 DICT_ERR
可以看出 value 的值是后面才设置到 entry 里面去的
我们先概览一下 dictAdd 的逻辑, 之后 再来稍微看一下 扩容的部分
如果正在 rehash, 单步 rehash
根据 key 计算 hash, 然后计算 key 应该存放的 bucket 的索引, key 已经存在直接返回
如果是在 rehash, 关联 ht[1], 然后创建 entry, 并初始化, 头插法插入到 table[index], 更新 th->table[index]
设置 entry 的 key
关于扩容
扩容之前的情况
可以看到上面添加了 "name" -> "jerry" 整个 dict 处于 rehash 的阶段
所以将新加入的 "name" -> "jerry" 放到了 ht[1] 里面
那么我们看一下 此时的 dict 里面的 ht[0], ht[1] 的情况
可以看出的是 ht[0] 的里面的数据 还是和之前是一样的, ht[0].table[2] 里面有三个元素, ht[0].table[3] 里面有一个元素, ht[0] 里面合计四个元素
ht[1] 里面 ht[1].table[4] 里面有一个元素, ht[1] 里面合计有一个元素

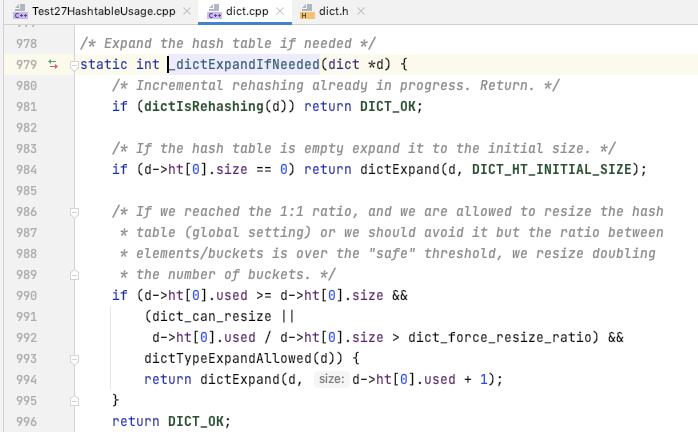
扩容的判断是在哪里呢, 以及扩容的具体细节怎么的呢?
可以看到的是 扩容的条件是 已经有的元素数量 大于等于 bucket 的数量 并且 dict_can_resize[dict扩容标记, 默认为 true], 或者 (已经有的元素数量/bucket 的数量) 比率超过了 dict_force_resize_ratio(默认为5)
下面的 dictTypeExpandAllowed 是预留的一个限制规则, 通过 type 传入进来, 如果 expandAllowed 为 NULL, 默认返回 true
扩容之后的结构呢?
具体扩容之后的 ht 的 bucket 数量是通过 size 来计算的, 相当于是 翻倍
分配了新的 hashtable 之后, 初始化 ht[1] 为新的 hashtable
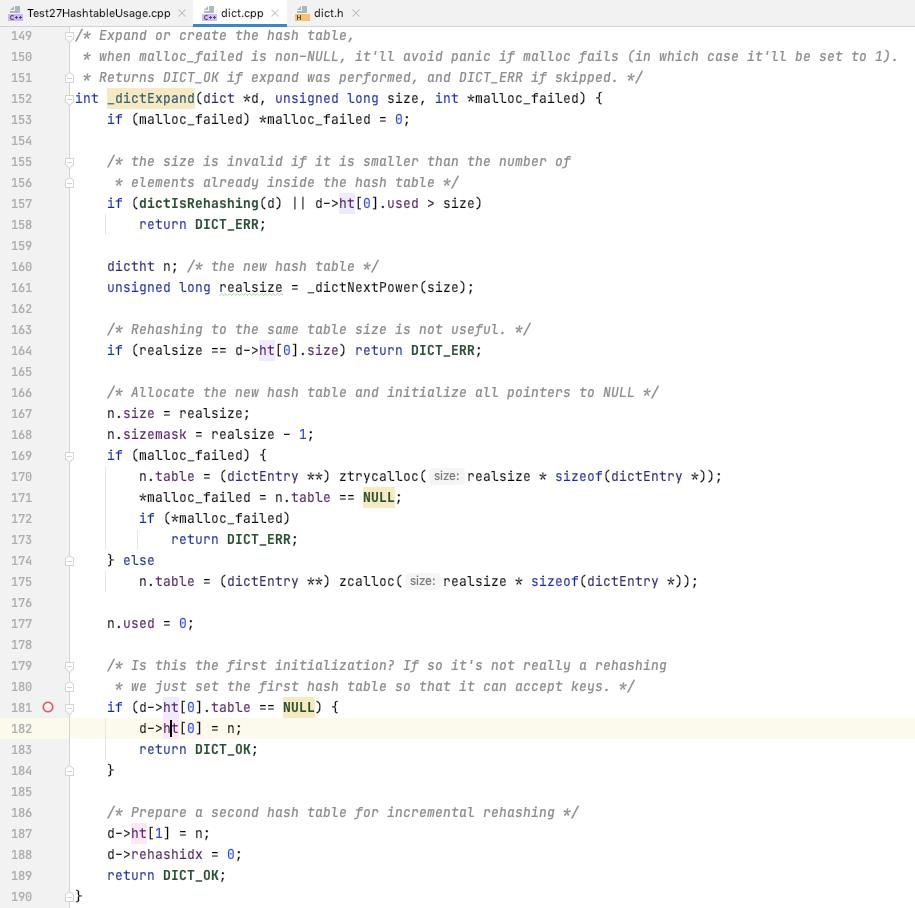
关于单步 rehash
调用的是 _dictRehashStep(d), 每一次处理一个 bucket 的数据
这个和 java.util.HashMap/HashTable 相比的差异就是, 前者是 在一定的操作下面来一部分一部分的来触发 rehash, 后者是在 expand 的过程中, 会创建新的 hashtable, rehash, 更新 hashtable, 整套流程做完
随着数据量越来越大, 显然是 dict 这里的处理会有更快的响应处理, 一次处理一部分, 直到所有的数据处理完成, hash 函数足够分散的场景下面, 一个 bucket 上面最好的期望应该是只有一个元素, 单步 rehash 会非常快
在那些情况下会推动 单步 rehash 呢?
1. dictAddRaw 添加元素的时候, dictAdd, dictReplace 都会调用
2. dictDelete, dictUnlink 删除元素的时候
3. dictFind 查询 entry 的时候, dictFetchValue 会调用 dictFind
4. dictGetRandomKey/dictGetSomeKeys 获取元素的时候
5. dictRehashMilliseconds 获取元素的时候[给定的时间限制内, 多次调用, 100步作为单位]
单步 rehash 的逻辑
可以看到是 传入一个 n, 表示 n step, _dictRehashStep 传入的 n 为 1
一个 step 就是迁移 ht[0] 里面的 rehashidx 或者下一个 有元素的 bucket 的数据迁移到 ht[1] 里面去
如果 ht[0] 里面的元素迁移完毕了, 更新 rehash 状态, 切换 ht[0] 的数据为最新的 ht[1], 重置临时表 ht[1]
调试真实的单步 rehash
回到我们的测试用例, 第一个 dictAdd 会触发 rehash
可以看出的是 ht[0] 的里面的数据 还是和之前是一样的, ht[0].table[2] 里面有三个元素, ht[0].table[3] 里面有一个元素, ht[0] 里面合计四个元素
ht[1] 里面 ht[1].table[4] 里面有一个元素, ht[1] 里面合计有一个元素
ht[0] 里面是有 table[2], table[3] 有数据, 因此 我们期望应该是第二个 dictAdd 会单步 rehash ht[0] 里面的 table[2] 的数据
接着的这一个 dictReplace 会单步 rehash ht[0] 里面的 table[3] 的数据
接下来我们调试一下 这个流程
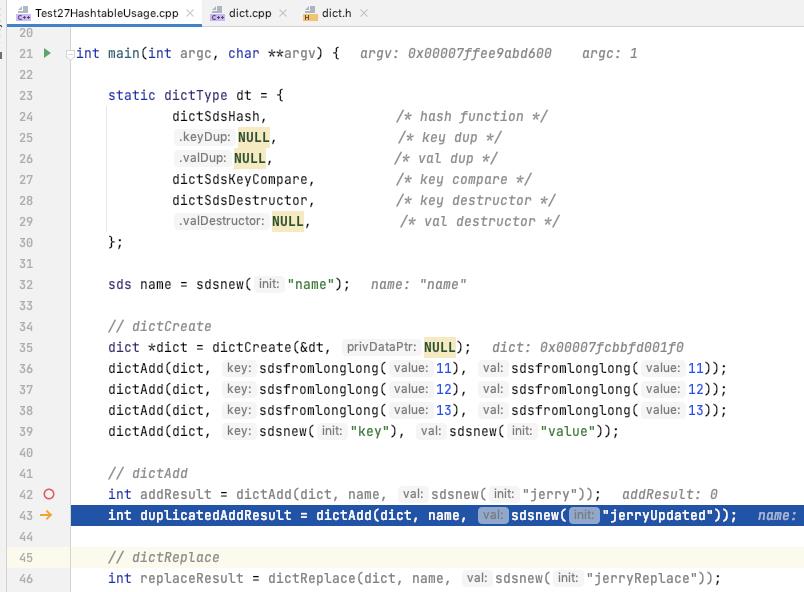
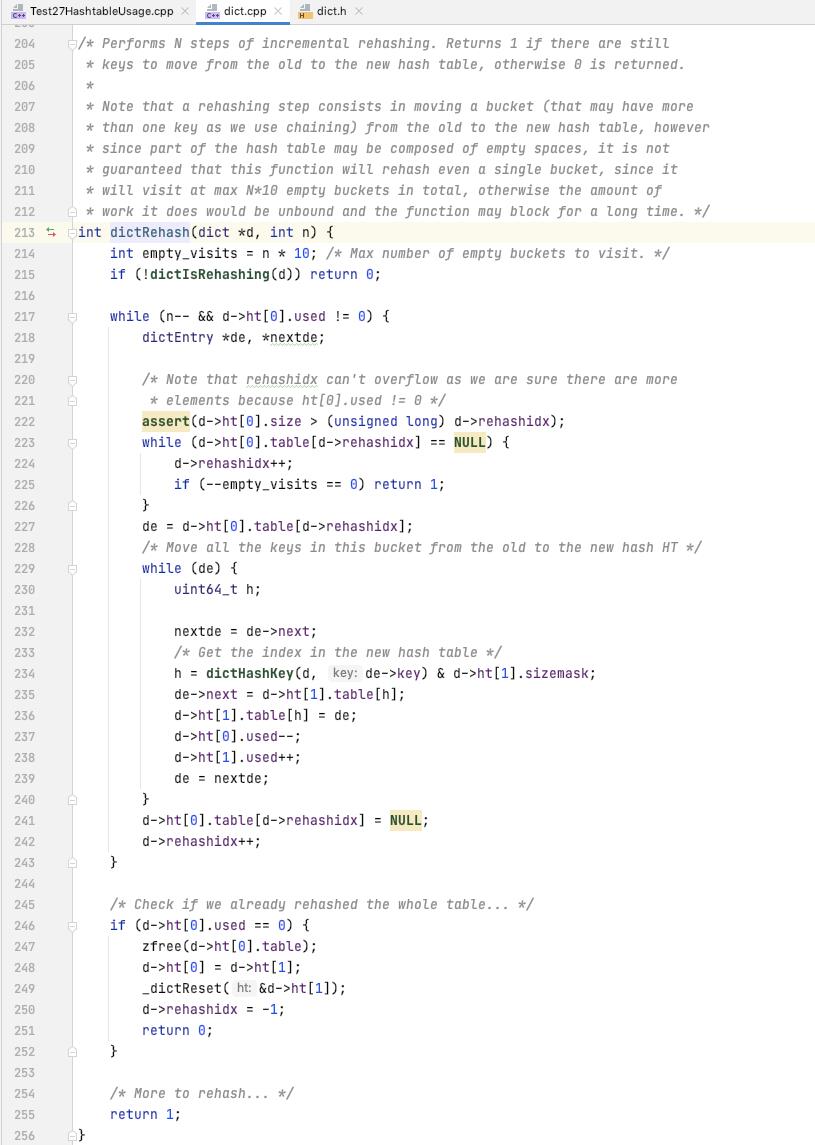
执行了第二个 dictAdd 之后
可以看到的是 ht[0].table[2] 的数据已经被清空了, ht[1].table[2] 里面装了数据了, 包含了三个元素[为什么我知道他会迁移到 ht[1].table[2], 呵呵 因为 这里的 hash 是我自定义的, 取得是字符串的长度]
ht[0] 里面只有 一个元素了, 在 table[3] 上面
ht[1] 里面有四个元素, 三个是在 table[2]上面, 刚才 单步 rehash 过去的, 一个是在 table[4]上面, 第一个 dictAdd 新增上去的

执行了第一个 dictReplace 之后
ht[0] 上面还有 table[3] 需要 rehash, 将 ht[0].table[3] rehash 了之后, 其数据会移动到 ht[1].table[3] 或者 ht[1].table[7] 上面
table[3] 处理完成之后, ht[0] 上面的所有的数据 就已经 rehash 完毕了, 可以执行上面的 切换 ht[0] 为 ht[1], 重置 ht[1] 的相关处理了
可以看到的是 ht[1] 上面解析各个 table 的数据已经报错了, 因为这里执行了 单步 rehash 之后 rehash 已经完成了, 重置了 ht[1], 导致这里的 watch 报错
可以看到的是 ht[0].table[2] 上面三个元素, ht[0].table[3] 上面一个元素, ht[0].table[4] 上面一个元素, 合计五个元素
至此 一个简单的 单步 rehash 的调试, 就调试完了
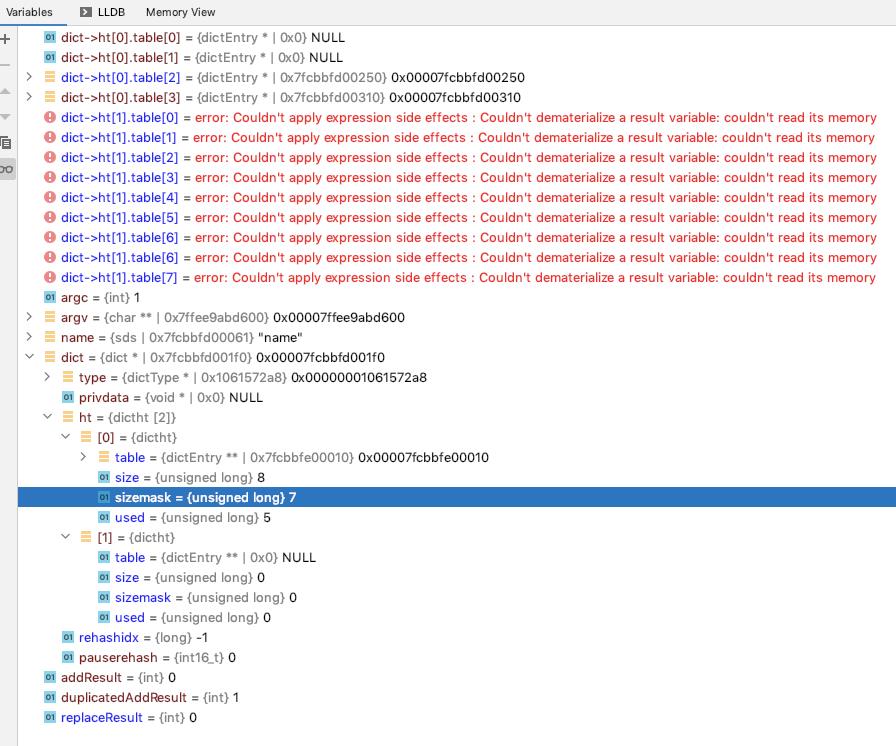
ht[0] 的完整数据如下
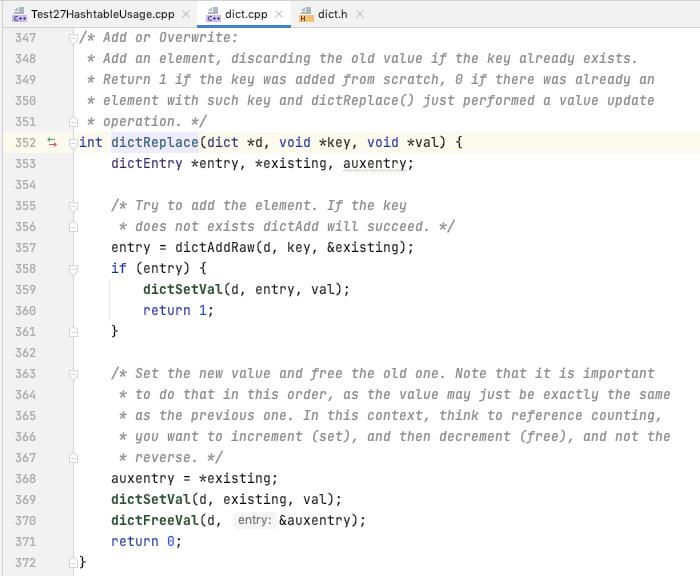
dictReplace
dictAdd 一个 entry(key, value), 如果新增成功 设置 entry.value
否则 更新已有的 entry 的 value
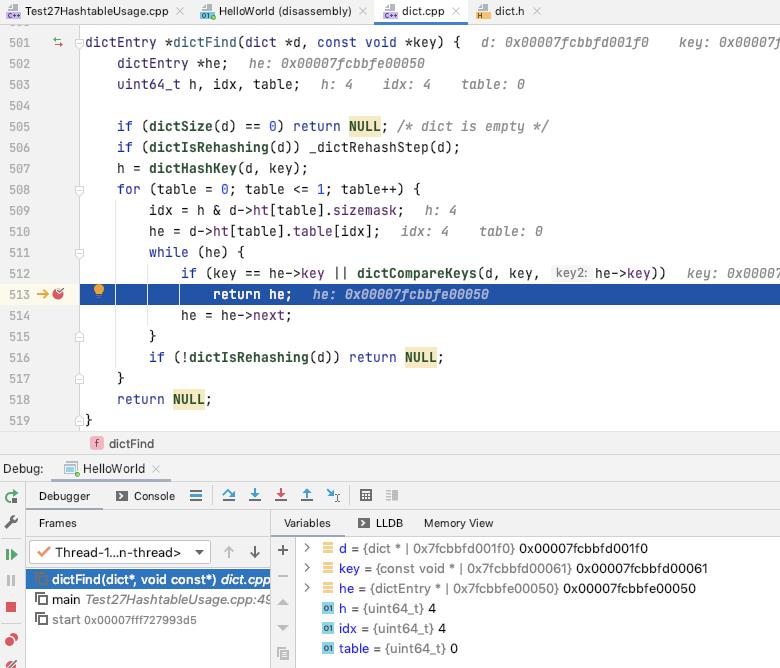
dictFind
如果是正在 rehash, 单步 rehash
计算 key 对应的 hash, 取模计算哪一个 bucket[两个 hash 表中查找]
遍历 bucket 根据 key 获取 entry 返回
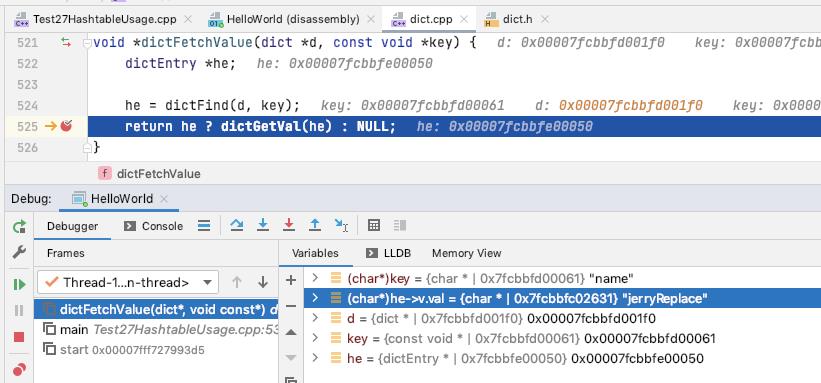
dictFetchValue
dictFind 找到 entry, 获取 value 返回
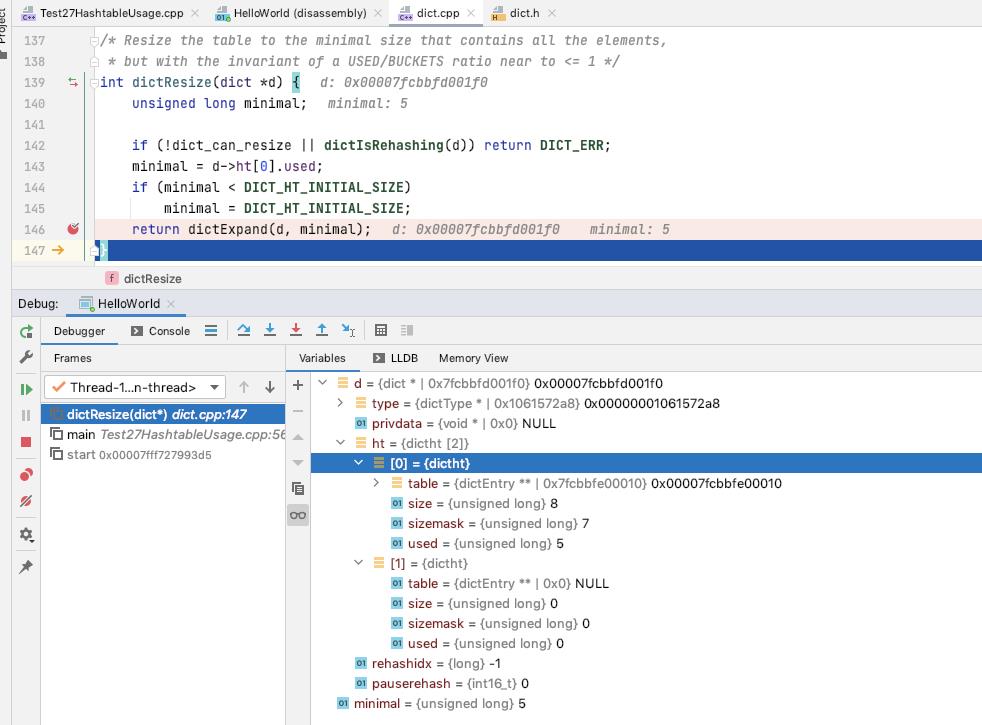
dictResize
根据 dict->used 来进行 resize
如果 dict->ht[0] 为空, 更新 dict->ht[0] 为 resize 之后的 hashtable
如果 dict->ht[0] 不为空, 更新 dict->ht[1] 为 resize 之后的 hashtable, 并设置为需要进行 rehash[然后后面的数据会在之后的业务处理过程中进行 单步 rehash]
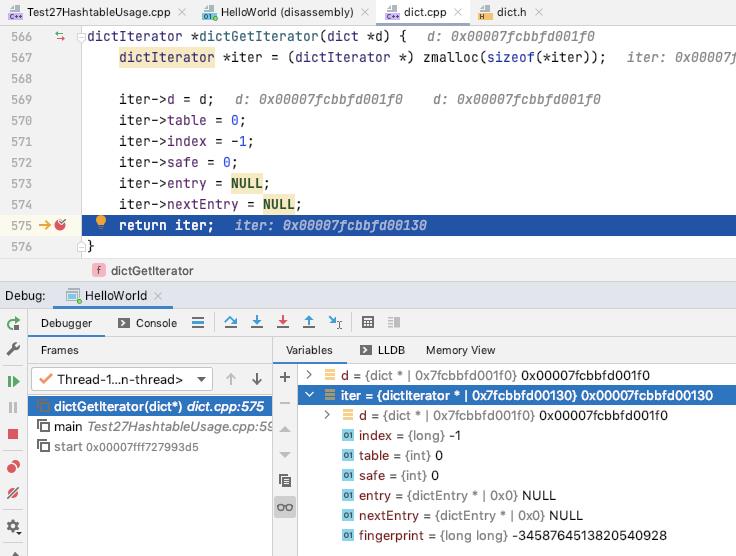
dictGetIterator/dictGetSafeIterator
初始化一个 dictIterator, 并初始化
初始化一个 dictIterator, 并初始化, 更新 safe 标记为 true
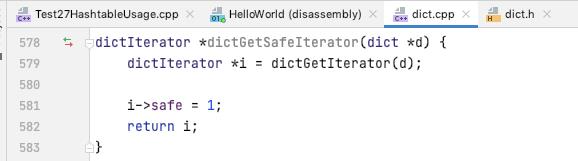
dictNext
如果 ite->entry[某一个 bucket 上面的节点] 已经初始化过了, 不断的向后迭代
否则 初始化 ite->entry, ite->fingerprint 记录的是 ht[0], ht[1] 的状态, 如果是 安全迭代器, 暂停单步 rehash
如果迭代完当前 ht 的最后一个 bucket, 判断是否是在 rehash, 切换 ht[1]
如果 不在 rehash, 或者 遍历完 ht[1], 返回 NULL
某一个 bucket 迭代完成, 更新 ite->entry 为 NULL, 向下一个 bucket 迭代
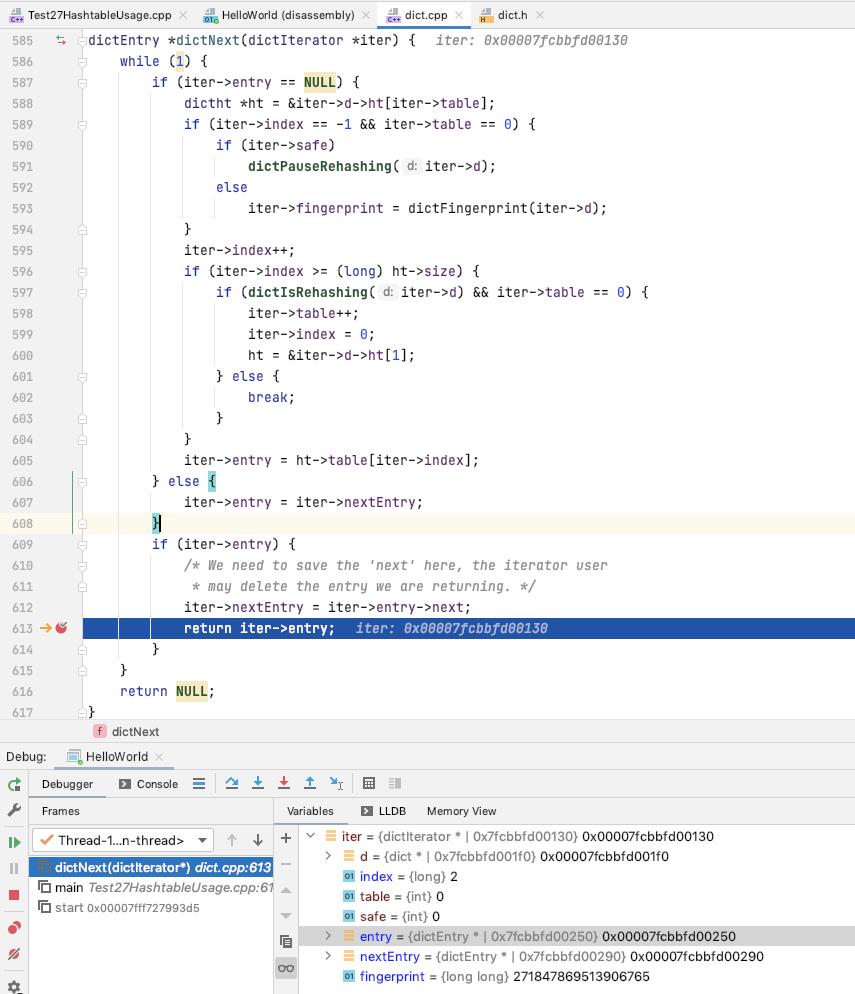
dictReleaseIterator
如果是安全迭代器, 恢复rehash的处理
如果是不安全的迭代器, 断言[确保程序对于不安全的迭代器使用正常]确保 迭代期间 dict 的状态没有发生变化
清理掉 iterator
dictGetRandomKey
先选择 bucket, 随机从 ht[0], ht[1] 选择一个 bucket
获取这个 bucket 的长度, 然后 随机选择一个元素

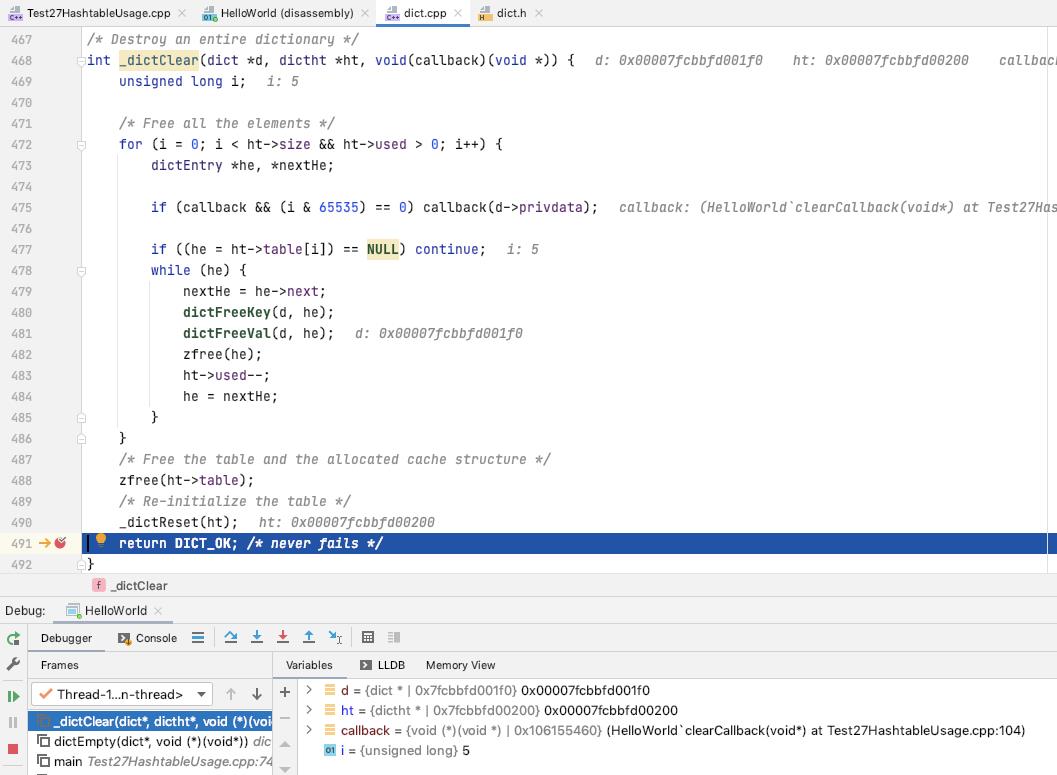
dictEmpty
清理掉 ht[0], ht[1], 并重置 dict 的状态
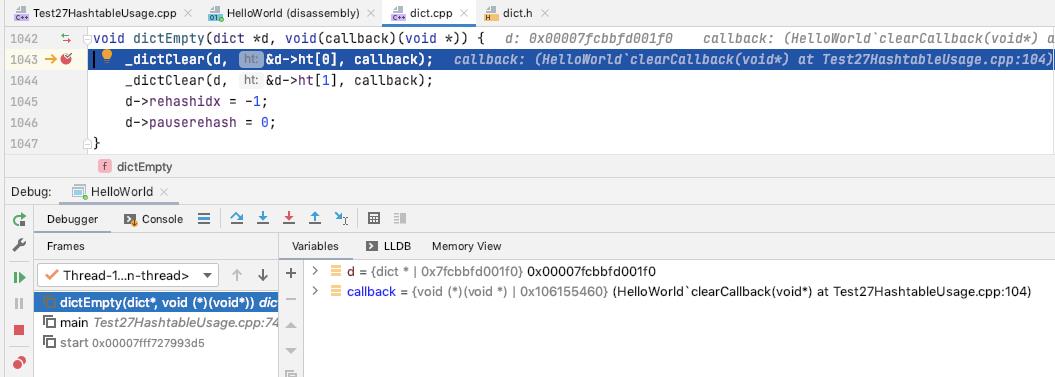
遍历整个 hashtable 的所有的 bucket
清理掉所有的节点
清理的处理过程中定期调用 callback, 传入 dict.privdata 作为参数
清理掉 ht.table, 重置 ht
完
以上是关于06 关于 dict的主要内容,如果未能解决你的问题,请参考以下文章